点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
星球内有20多门3D视觉系统课程、3DGS独家系列视频教程、顶会论文最新解读、海量3D视觉行业源码、项目承接、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎加入!
太长不看版:LiAuto-GeoX为3D重建以及后续的自动驾驶相关任务,提供了高效的驾驶几何模型。该模型在精度与效率之间实现了良好的平衡,能够适应多种不同的相机配置;同时,它还将所学习的密集几何信息应用到姿态估计、深度估计、3D重建、轨迹预测、占用情况预测以及未来占用情况预报等任务中,在各项任务中都展现了出色的性能。

论文信息
标题:LiAuto-GeoX: Efficient Grounded Driving Transformer
作者:Jiawei Lian, Haoyi Sun, Yang Wu, Lifu Mu, Siyuan Wang, Le Hui, Ning Mao, Tao Wei, Pan Zhou, Kun Zhan, Jian Yang
机构:Nanjing University of Science and Technology、Li Auto Inc.、Northwestern Polytechnical University 4Department of Computing, The Hong Kong Polytechnic University
原文链接:https://arxiv.org/pdf/2606.05774
代码链接:https://github.com/ljwwwiop/GeoX/tree/infer
导读
密集的3D重建技术在空间理解方面展现出巨大潜力,但能否作为自动驾驶系统中的实时、嵌入式表示方法,仍是一个有待解决的难题。现有的大规模视觉几何模型通常需要大量的计算资源,且无法满足动态驾驶环境对长距离几何精度、全景一致性以及实时处理效率的要求。为填补这一空白,我们提出了LiAuto-GeoX——一种高效的驱动场景理解模型,专为实现以车辆为中心的3D场景理解而设计。该模型首先从大规模的全景数据中学习高容量的驾驶几何模型,同时利用稀疏的激光雷达数据为那些距离较远、结构不清晰或信息不足的区域提供可靠的几何参考。接着,通过一种创新的几何保持式蒸馏框架,将这一功能整合到仅有155百万参数的紧凑型嵌入式模型中。该框架通过掩码引导的深度感知蒸馏技术来保留精细的几何结构,同时利用相对姿态关系蒸馏技术来确保不同视角下的空间一致性。大量测试表明,LiAuto-GeoX在KITTI数据集上的运行速度可达220帧/秒,同时还能保持高精度的3D重建效果,从而实现实时应用。此外,该模型所学到的几何信息还可以被用于后续的自动驾驶任务中:在轨迹预测方面,其准确率为90.6 PDMS;在物体存在性预测方面,准确率为24.63 mIoU;在未来帧预测方面,准确率为47.67 IoU。这些结果都表明,高效的密集3D重建技术不仅可以作为感知工具,还可以作为下一代自动驾驶系统中的基础几何表示方法。
效果展示
多视角3D重建效果的定性比较。我们利用各基准方法(VGGT、OmniVGGT、PI3、DVGT)的默认开源配置,对其方法进行了比较。每个结果均展示了主体视图(上方)和自上而下视图(下方)。在不同相机数量(2至8个视角)下,我们的模型均能呈现出更为清晰的几何形态和更完整的结构。

引言
尽管稠密三维重建长期以来一直是计算机视觉的基本问题,其在自动驾驶中的角色正在经历范式转变。对于驾驶系统而言,三维几何不仅仅是重建目标。更确切地说,它是从自车视角推理可行驶区域、物体布局、动态智能体以及未来场景演化的基础表征。这一基础角色带来了严格的现实约束。离线重建模型或许能产生高精度的几何,但实际的车载表征要求实时效率、空间一致性以及与下游自动驾驶任务的无缝集成。因此,核心问题不再仅仅是二维图像能否被提升为稠密三维,而是这种稠密视觉几何能否作为可部署、基础性的表征用于真实世界的驾驶。
大规模视觉几何模型的迅速涌现,使得这一探索日益切中要害。从经典基于学习的多视角立体到近期基于Transformer的几何架构,视觉重建已朝着直接从图像恢复度量三维结构的方向演进。然而,将这些通用基础模型迁移到自动驾驶领域,带来了不小的挑战。在空间层面,驾驶场景依赖重叠区域有限的环视相机,造成跨视图关联稀疏且不均匀。在部署层面,自动驾驶车辆施加严格的部署约束,要求感知模块在有限的车载算力下低延迟推理。因此,尽管现有大规模几何模型重建能力出色,它们仍未成为驾驶智能可行、可部署的基座。
一个自然的方向是将高容量几何模型的能力迁移到一个紧凑的车载模型中。然而,这种迁移不能被当作传统的模型压缩。稠密驾驶几何对局部和全局误差都高度敏感。在局部,物体边界、薄壁结构或远距离区域周围的不准确深度可能导致几何变形,尤其在复杂天气和光照条件下。在全局,环视相机间不一致的空间关系会破坏自车场景布局,这在相机配置或数量变化时尤为明显。诸如通用的特征匹配或logits对齐这类标准的蒸馏目标,在两个关键方面存在不足:它们平等地对待所有空间区域,并独立地建模多个视图。在教师模型与学生模型容量差距大的情况下,紧凑的学生模型倾向于拟合占主导、简单的区域,而丢失边界处的细粒度深度,并无法在重叠有限的相机之间维持全局一致的空间关系。这一关键差距促使我们提出保持几何的迁移框架,显式地维护细粒度的深度保真度和跨视图空间一致性。
本文提出LiAuto-GeoX,一个用于可部署三维驾驶场景理解的高效几何接地驾驶Transformer。我们首先从大规模环视数据中学习一个高容量驾驶几何教师模型。关键是,我们不单纯依赖视觉外观,而是将车辆标定好的多相机位姿作为显式几何输入来条件化教师模型。这种位姿条件的建模将视觉观测锚定在以驾驶为中心的坐标系中,使教师能够预测具有更强度量一致性的稠密驾驶几何,特别是在远距离、模糊或弱纹理区域。然后,我们通过保持几何的蒸馏,将这一能力实例化到一个紧凑的1.55亿参数的车载模型中。具体而言,掩码引导的深度感知蒸馏强调可靠且几何信息丰富的区域,以保持细粒度的度量结构;而相对位姿关系蒸馏则迁移由位姿引起的跨视图关系,以维持全局一致的驾驶几何。为了提供更强的学生监督,我们从高容量教师那里蒸馏稠密预测,而非稀疏的激光雷达测量,从而为远距离、模糊和结构稀疏区域产生更连续的几何信号。
最终模型在重建保真度和部署效率之间取得了很好的平衡。LiAuto-GeoX 在 KITTI 数据集上以 220 帧/秒的速度运行,同时保持高质量的稠密三维重建。更重要的是,学习到的几何并不仅限于重建本身。它能有效迁移到下游自动驾驶任务中,在轨迹预测上达到 90.6 PDMS,占据预测的 Occ mIoU 为 24.63,未来帧预测的交并比(IoU)为 47.67。这些结果表明,高效的稠密三维重建不仅能作为感知目标,还可以成为下一代自动驾驶系统可扩展的几何表征。
主要贡献
我们的贡献总结如下:
可部署的驾驶几何。我们提出 LiAuto-GeoX,一个高效几何接地驾驶 Transformer,将稠密三维重建探索为自动驾驶实用的车载表征。
几何保持的迁移。我们提出一个几何保持的迁移框架,将大规模驾驶几何模型适配为紧凑可部署模型,同时保留局部深度感知和跨视图一致性。
实时性能与任务迁移。LiAuto-GeoX 在 KITTI 视频深度上以 220 FPS 运行,并展示出向轨迹预测、占据预测和未来帧预测的有效迁移。
方法
我们将 LiAuto-GeoX 构建为一个用于实时环视三维重建的教师-学生框架。给定标定好的环视图像 I = {Ii} N i=1,其中 Ii ∈ R 3×H×W,以及相机参数 C = {(Ki, Ti)} N i=1,模型预测稠密的三维驾驶几何,包括每幅视图的深度图 D = {Di} N i=1 以及重建的点云 P ∈ R M×3。如图 2 所示的整体流程包含三个阶段:教师训练、几何保持蒸馏以及高效的环视推理。我们首先从大规模环视数据中训练一个高容量驾驶几何教师模型 F T θ,其中稀疏激光雷达先验为挑战性区域提供几何根基。教师产生可靠的重建目标以及中间几何令牌,记为 (DT, PT, ZT)。
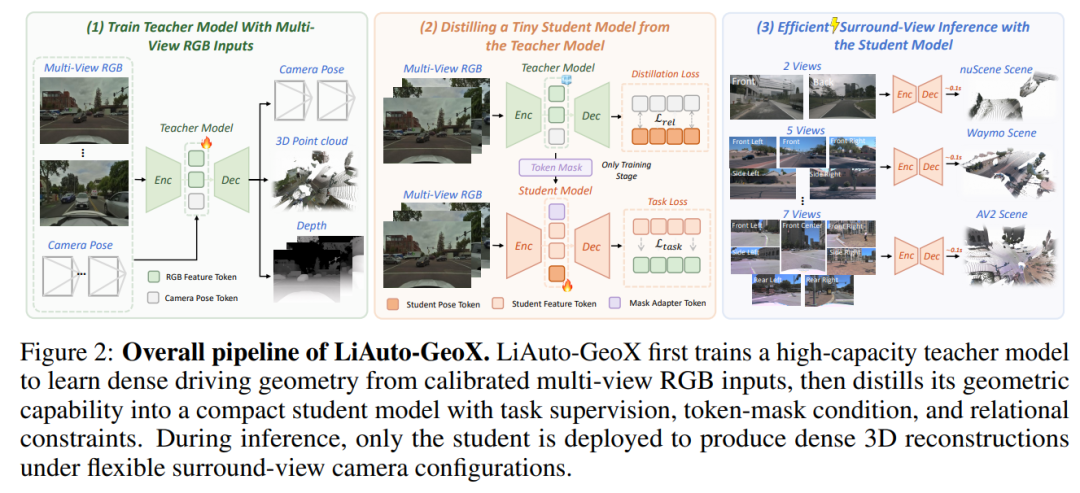
然后,我们将教师蒸馏到一个紧凑的 1.55 亿参数的学生模型 F S θ 中,用于实时部署。LiAuto-GeoX 不依赖于通用的输出或特征对齐,而是通过两个互补目标迁移几何:用于可靠深度结构的掩码引导深度感知蒸馏,以及用于跨视图空间一致性的相对位姿关系蒸馏。训练后,仅部署学生模型,接收标定好的环视 RGB 图像作为输入,并在单次前向传播中产生稠密三维重建。


实验结果
我们在表 2 中报告了环视三维重建的定量结果。遵循常见的重建评估协议,我们在计算点云精度和完整度之前应用 Umeyama 对齐,该对齐在统一尺度和位姿后测量重建点云与真实点云之间的几何差异。跨五个自动驾驶数据集,LiAuto-GeoX 仅凭 1.55 亿参数便取得了有竞争力的重建质量,使其比参数超 10 亿的 VGGT 类基线模型以及 9.59 亿参数的 π 3 显著更紧凑。虽然大型模型在某些数据集(如 Waymo 和 PandaSet)上仍能达到更高的精度,但 LiAuto-GeoX 在模型规模小得多的情况下保持了相当的点云重建质量。值得注意的是,在 DDAD 上,LiAuto-GeoX 在精度和完整度两方面均取得最佳性能,精度为 1.012,完整度为 1.174,优于所有对比方法,包括规模更大的 π 3。在 nuScenes 上,我们的方法也获得了很强的完整度分数 1.729,超越了 VGGT、FastVGGT、LiteVGGT、OmniVGGT 和 DVGT。这些结果表明,紧凑的驾驶几何模型能够保持有竞争力的重建质量,同时提供更实际的部署效率。


总结 & 未来工作
本文提出了 LiAuto-GeoX,一个高效的几何接地驾驶 Transformer,重新审视了稠密三维重建作为自动驾驶可部署几何表征的作用。我们没有将重建仅仅视为离线的感知目标,而是聚焦于核心部署问题:稠密视觉几何能否做到精确、空间一致且足够高效,以用于车载驾驶系统。为此,我们首先从环视驾驶数据中构建了一个大规模驾驶几何教师模型,然后通过几何保持蒸馏将其能力迁移到一个紧凑的 1.55 亿参数学生模型中。所提出的掩码引导深度感知蒸馏在几何信息丰富区域保持了细粒度的度量结构,而相对位姿关系蒸馏在环视相机几何下强制执行了跨视图一致性。
大量实验表明,LiAuto-GeoX 在重建保真度和实时效率之间取得了很好的平衡,在 KITTI 视频序列上以 220 FPS 运行,同时保持了高质量的稠密几何。更重要的是,学习到的表征超越了重建本身,在多种驾驶任务中有效迁移,改进了轨迹预测、占据预测和未来帧预测。这些结果表明,高效的稠密三维重建可以不仅是视觉几何任务:它可以成为下游自动驾驶可扩展的几何基座。通过连接高容量几何学习与紧凑的车载部署,LiAuto-GeoX 为面向真实世界驾驶智能的可部署、几何接地表征指明了一条实用路径。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
。




添加微信:cv3d001,备注:姓名+方向+单位,邀请入群。