点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
作者供稿直发 | 编辑:3D视觉工坊
星球内有20多门3D视觉系统课程、3DGS独家系列视频教程、顶会论文最新解读、海量3D视觉行业源码、项目承接、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎加入!
0. 论文信息
标题:Co-Evolving Skill Generation and Policy Optimization 作者:Zhiwei Zhang, Yudi Lin, Nikki Kuang, Linlin Wu, Xiaomin Li, Songtao Liu, Fenglong Ma 机构:宾夕法尼亚州立大学(Penn State)、南洋理工大学(NTU)、加州大学圣地亚哥分校(UCSD)、犹他大学(Utah)、哈佛大学(Harvard) 原文链接:https://arxiv.org/abs/2606.08755 代码链接:https://github.com/zzwjames/skill_augmented_agent
1. 导读
想象一下,你训练了一个 AI agent 去完成各种任务。每做完一次,它都会把这次的经验总结成一条小技巧(skill),记进自己的「技能手册」里;下次遇到类似任务,就把相关技巧翻出来参考。听上去很美好——agent 应该越用越聪明才对。
但现实往往是:手册里记下的技巧,很多根本没用,有的甚至是「错误经验」,会把 agent 带偏。更糟的是,这些坏技巧一旦被写进手册,就会被反复翻出来,持续拖累 agent 的学习。
这正是当前技能增强强化学习(skill-augmented RL) 的范式:agent 把成功/失败的轨迹总结成程序性知识(procedural knowledge),写进一个可检索的技能库(skill bank);下次遇到相似任务再检索出来辅助决策。现有方法几乎都默认一个前提:只要用足够强的大模型(如 GPT、Claude)来总结经验,生成的技能就一定可靠。
但作者发现:这个前提并不成立。 即便技能来自 GPT-5.4、Claude-Opus-4.6 这样的顶尖大模型,它们的实际效用(utility)也极其混杂——一小部分确实有用,很多毫无帮助,甚至有些会误导 agent。这个问题在在线强化学习(online RL) 中尤其致命:低质量技能一旦入库,就会被反复检索出来,持续污染采样与策略更新;而后续奖励反映的是「多条技能的联合效果」,根本无从判断到底是哪条技能在帮忙、哪条在捣乱。
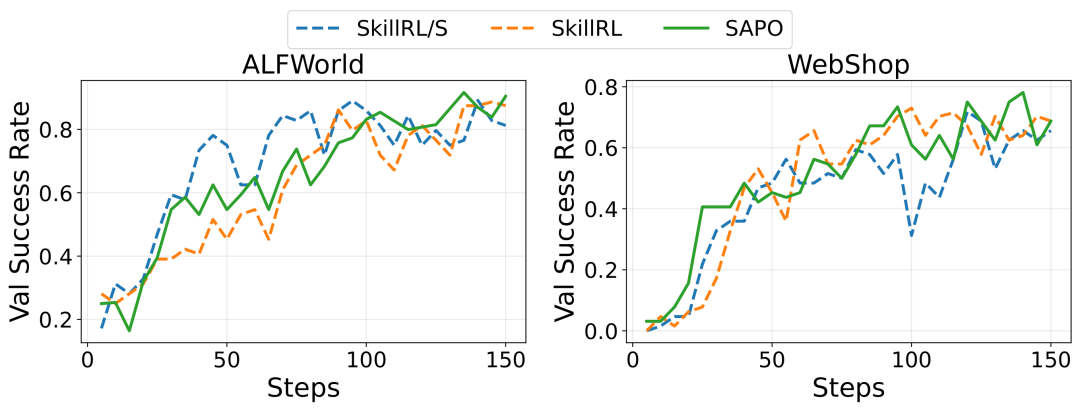 图1. 左图:朴素地「进化」技能库(SkillRL)相比固定版本(SkillRL/S)提升非常有限,在 ALFWorld 上甚至达到最优更慢——无脑往库里加技能并不能换来更高的学习效率。
图1. 左图:朴素地「进化」技能库(SkillRL)相比固定版本(SkillRL/S)提升非常有限,在 ALFWorld 上甚至达到最优更慢——无脑往库里加技能并不能换来更高的学习效率。
 图2. 更直接的证据:GPT 生成技能的平均效用(蓝线 Mean)几乎一直贴着 0 抖动。尽管「被提拔(Promoted)」和「被丢弃(Discarded)」的技能之间确有明显差距,但整体上好技能与坏技能严重混在一起——花着昂贵的 API 费用,却产出了一大堆没用甚至有害的技能。
图2. 更直接的证据:GPT 生成技能的平均效用(蓝线 Mean)几乎一直贴着 0 抖动。尽管「被提拔(Promoted)」和「被丢弃(Discarded)」的技能之间确有明显差距,但整体上好技能与坏技能严重混在一起——花着昂贵的 API 费用,却产出了一大堆没用甚至有害的技能。
一句话概括动机:问题不在于技能生成得不够多,而在于缺了一道「这条技能到底有没有用」的把关。
2. 效果展示
为解决上述问题,作者提出 SAPO(Skill-Augmented Policy Optimization)——一个能在技能进入「手册」之前就先「质检」的在线 RL 框架。其核心理念一句话即可说清:对 language agent 而言,关键不是「生成更多技能」,而是「知道哪些技能真的有用」。
效果上,SAPO 在交互式决策(ALFWorld、WebShop)与检索增强问答(Search-QA)等多个基准上全面超越此前的技能增强 RL 方法,同时省掉了昂贵的闭源大模型 API 调用。下图是 SAPO 与代表方法 SkillRL 的训练曲线对比:SAPO 不仅涨得更快(早期就拉开差距),而且最终的最优验证性能也更高,并能跨不同 backbone 保持优势。
 图3. SAPO 与 SkillRL 在 ALFWorld 和 WebShop 上的验证成功率曲线(base model 为 Qwen3-4B-Instruct)。
图3. SAPO 与 SkillRL 在 ALFWorld 和 WebShop 上的验证成功率曲线(base model 为 Qwen3-4B-Instruct)。
3. 主要贡献
揭示关键问题:首次系统性地指出,现有技能增强 RL 方法忽视了「生成技能效用混杂」这一事实,让低质量技能被直接写入技能库,从而误导 agent 的学习——即便是 GPT-5.4、Claude-Opus-4.6 这样的顶尖大模型生成的技能也不例外。 提出 SAPO 框架:一个全新的在线 RL 框架,能在不增加任何额外采样开销的情况下估计技能效用,做到「先验证、再存储」;并把同一个策略同时训练成「任务求解 agent」与「技能生成器」,大幅降低对闭源大模型的持续依赖。 充分的实验验证:在交互式决策与检索增强问答等多个基准上,SAPO 全面超越现有方法。尤其是它让一个开源 4B 小模型自己学会生成技能,效用追平甚至偶尔反超 GPT-5.4(如下图)。
图4. SAPO(用 Qwen3-4B 当技能生成器)与 SkillRL(用 GPT-5.4 当技能生成器)所生成技能的效用对比:训练后期,开源小模型的技能效用追平了 GPT-5.4。
4. 方法
SAPO 把技能归纳(induction)、技能验证(validation) 和技能维护(maintenance) 三件事统一进了一个在线 RL 流程,整体框架如下图所示。
 图5. SAPO 框架。整套流程不依赖外部闭源大模型,由策略自身完成技能的生成、验证与打分。
图5. SAPO 框架。整套流程不依赖外部闭源大模型,由策略自身完成技能的生成、验证与打分。
(1) 用「配对实验」白嫖出技能的真实价值
SAPO 最巧妙的一招,是在不增加任何额外采样开销的前提下估出一条新技能到底有没有用。对于一个任务(或一小组语义相近的任务),它做了一组「对照实验」:
先检索已有技能,用一半 rollout 预算跑出 base rollouts——反映「当前策略在已有技能下能做到什么、还会在哪里失败」; 基于这些轨迹,让策略归纳出一条候选技能; 再用另一半 rollout 预算,在完全相同的任务、相同的已检索技能下,只额外加入这条候选技能,跑出 skill-augmented rollouts。
两组 rollout 唯一的差别就是「有没有这条新技能」,于是它们的奖励差值就直接量化出了这条技能的边际贡献(marginal utility):
技能效用 = 加了新技能后的平均奖励 − 不加新技能的平均奖励
妙处在于:这个信号完全是在原本就要跑的采样预算里「白嫖」出来的,不需要任何额外的反事实采样;而且它衡量的是技能在已有技能之外的增量价值——这是一个理想的、上下文相关(context-dependent) 的度量:一条技能单看也许有用,但如果库里已有类似的,它就是冗余的。
(2) 三道门槛:把好技能留下,坏技能挡在门外
拿到效用信号后,SAPO 维护两个技能库:临时库(候选)和长期库(已验证)。一条候选技能只有同时满足三个条件才会被「提拔」进长期库:效用为正、排进前列(默认 top-20%)、足够新颖(与已有技能不重复)。低效、冗余或有害的技能,则在进入长期库之前就被直接丢弃,从源头避免污染后续检索与训练。
(3) 让策略「身兼三职」:自己当 agent,也自己造技能、自己打分
SAPO 没有止步于「过滤技能」,而是用这个效用信号进一步训练策略本身,让同一个模型扮演三个角色:
任务求解者:照常与环境交互、完成任务; 技能生成器:借鉴 W-REINFORCE 的思路,用非对称的效用加权目标训练——正效用技能被强化,负效用技能被更狠地抑制,从而学会自己生成越来越好的技能,不再需要反复调用昂贵的 GPT/Claude; 技能打分器:训练后,策略「生成某条技能的概率」本身就成了这条技能「有不有用」的打分,用于技能库满时剪掉过时旧技能,以及在检索时对候选技能重排序(reranking)。
至此,技能生成、验证、策略优化 三者在线共同演化(co-evolve)——这正是论文标题《Co-Evolving Skill Generation and Policy Optimization》的含义。
5. 实验结果
主结果(ALFWorld & WebShop)。 SAPO 取得最佳综合性能,相比 SkillRL、Skill0、D2Skill 的一致提升说明:技能增强 RL 的性能不只取决于「把技能库做大」,更取决于控制进入技能库的技能质量。
表1. ALFWorld 与 WebShop 主结果(节选,base model 为 Qwen2.5-7B-Instruct)
| SAPO | 92.2 | 90.5 | 78.1 |
检索增强问答(Search-QA)。 在单跳(NQ / TriviaQA / PopQA)与多跳(HotpotQA / 2Wiki / MuSiQue / Bamboogle)问答上,SAPO 同样取得最佳平均性能,且在域外(out-of-domain) 数据集上也有提升,说明效用反馈帮助技能生成器学到的是可迁移的搜索与推理策略,而非数据集特定的「捷径」。
表2. 单跳与多跳 QA 的平均性能(7 个基准)
| SAPO | 47.8 |
消融实验。 去掉任一核心组件,性能都会下降,印证三处设计缺一不可:去掉验证 → 低质量技能直接入库,性能下降;去掉效用加权的生成器训练 → 技能质量变差,WebShop 成功率掉得最明显;去掉似然打分(剪枝 + 检索重排序)→ 技能复用变差。
表3. 消融实验(ALFWorld & WebShop)
| SAPO(完整) | 92.2 | 90.5 | 78.1 |
子任务训练动态。 在 ALFWorld 各子任务上,SAPO 训练更稳、后期波动更小;而 SkillRL 在多个子任务上达到峰值后反而下滑——这印证了「不加把关地进化技能库,会引入低质量/过时技能,反过来扰乱后期学习」。
 图6. ALFWorld 各子任务的验证性能曲线(base model 为 Qwen2.5-7B-Instruct)。
图6. ALFWorld 各子任务的验证性能曲线(base model 为 Qwen2.5-7B-Instruct)。
成本。 在 ALFWorld 上,SkillRL 式技能进化仅技能生成一项,单次实验调用 GPT-5.4 就要约 30 美元(还没算环境 rollout、检索、策略优化)。乘上多个 benchmark × seed × 消融与超参后成本相当可观;而 SAPO 把策略本身训练成技能生成器,并从「本来就要跑的 rollout」里白嫖效用信号,彻底避免了在线 RL 中反复的闭源 API 调用。
6. 总结 & 未来工作
SAPO 的一句话精髓:对 language agent 而言,关键不只是「生成更多技能」,而是「知道哪些技能真的有用」。
它通过一组配对 rollout,在不增加预算的前提下估出技能的边际效用,做到「先验证、再存储」;并用同一个效用信号把策略训练成更强的技能生成器 + 打分器,让技能生成、验证与策略优化在线协同演化,同时摆脱对昂贵闭源大模型的依赖。实验证明,SAPO 在交互式决策与检索增强问答上都稳定超越此前的技能增强 RL 方法。
未来工作:这套「先用配对实验在线估出边际价值,再决定要不要保留」的思路,本质上是一种轻量、可解释的在线信用分配(credit assignment)。未来有望推广到更广义的智能体记忆维护、工具调用筛选乃至多智能体协作等场景,成为构建「越用越聪明、而非越用越糊涂」的 AI agent 的一块重要基石。
本文仅做学术分享,如有侵权,请联系删文。
。




添加微信:cv3d001,备注:姓名+方向+单位,邀请入群。








![[开源硬件]用于构建、分析和破解 USB 设备的多功能协议分析仪-Cynthion](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2026-06-14/6a2e5def59b7e.jpeg)
