公众号记得加星标⭐️,第一时间看推送不会错过。

需要总是发明之母,如果你正试图建立自主的计算引擎设计和制造能力(就像中国正在做的那样),那么中国八个国家计算中心不仅会为其超级计算机建造国产加速器,还会创建没有卸载模型的全CPU机器,这些机器只是使用MPI将计算任务分散到传统的横向扩展网络中。
这样一来,中国就能制造出相对简单的大型机器,其实际限制仅在于空间和功率。为了设计武器以及推进所有科学领域的尖端技术,中国有资金和实力走规模化路线,而不是依赖密集的计算机辅助设计。
几年前,中国正是这样做的,为无锡国家超级计算中心打造了“海洋之光”超级计算机,它基于自主研发的神威SW26010-Pro CPU,拥有4193万个核心,理论峰值性能约为1.5 exaflops。如今,中国又用同样的方式打造了“光之星”超级计算机,它现在是世界上最快的超级计算机,并安装在深圳国家超级计算中心。
我将在另一篇文章中深入探讨LineShine机器的架构——LineShine大概是英文“sunbeam”(阳光)的直译——但总的来说,LineShine基于深圳新思科技(NSC Shenzhen)与中国IT巨头华为(可能是其海思芯片部门)联合设计的Armv9兼容服务器CPU。凌坤LX2 CPU设计有304个活动核心,而且很可能芯片上还有更多核心以提高良率。LineShine机器采用凌琦专有的LQLink互连技术,我相当肯定它基于InfiniBand技术的某种变体,但也可能是以太网的简化版。
结论是——或者更确切地说,鉴于 LineShine 在已正式提交高性能 Linpack 测试结果的超级计算机中排名第一——这款 LX2 CPU 凭借其 SVE2 向量单元提供了强大的 FP64 运算能力,仅需 1379 万个核心即可实现 2.74 exaflops 的理论峰值性能(四舍五入到小数点后三位)。在 HPL 测试中,LineShine 的性能略低于 2.2 exaflops,比之前排名第一的超级计算机——位于美国劳伦斯利弗莫尔国家实验室、基于 AMD MI300A 计算引擎的“El Capitan”超级计算机——性能提升了 21.5%。
中国在超级计算机领域重回巅峰,我们强烈怀疑中国还拥有更多未公开的百亿亿次级超级计算机。,即使中国没有提交官方的Top500排名,它在百亿亿次级超级计算机竞赛中也一直处于领先地位。
我不会逐一介绍榜单前十名的所有机器。您可以自行查阅,反正大家都这么做。我想在评论中提供一些有价值的信息,因此我会坚持我从2024年6月排名开始采用的方法,只关注本次榜单新增的机器,而忽略云服务提供商和电信运营商(主要在中国)的大量机器。这些机器会扭曲榜单,使其偏离高性能计算(HPC)的真正目的。这些机器并没有进行真正的高性能计算工作,这一点大家都心知肚明。
话虽如此,我们仍需提醒大家,我们仍然没有赶上摩尔定律每两年性能翻一番的步伐,至少在超级计算领域,我们的投入还不足以让我们搭上这趟顺风车。请看:
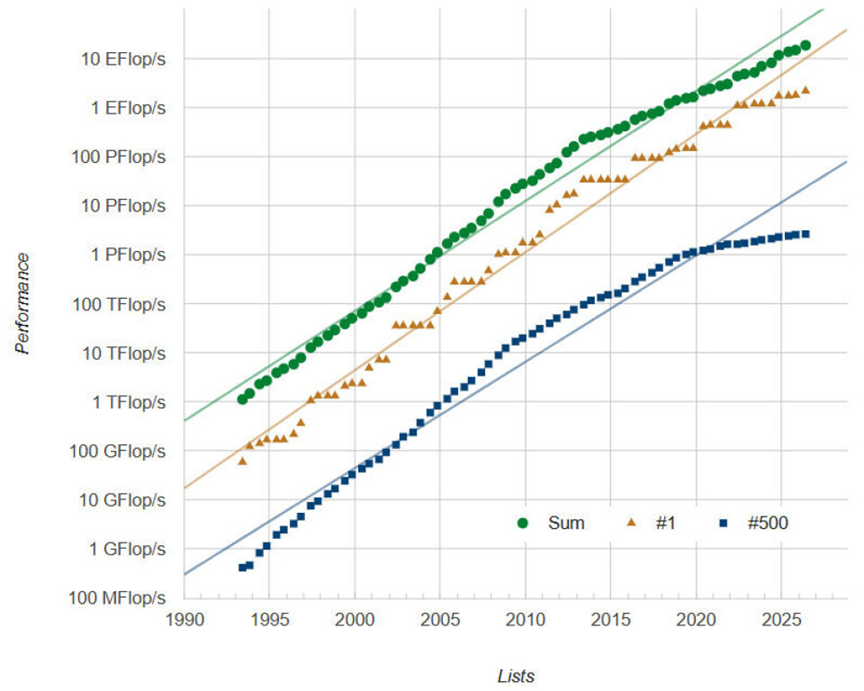
这更多的是预算问题,而不是技术问题。
看看哪些供应商在 Top500 排名中占有多大份额也很有趣,所以这里有一个漂亮的树状图,显示了谁按总容量占多大份额,这才是最重要的,因为失败案例就像代币一样,就是金钱。

五台官方认证的百亿亿次级处理器(exaflops)主导了性能格局,另外五台HPL性能超过400千万亿次级的机器也挤占了许多性能较小的机器的市场份额。这次,你必须拥有2.66千万亿次级的HPL性能才能跻身榜单。坦白说,考虑到现代CPU或GPU的性能极限,这个数字并不算高。
接下来,让我们来看看2026年6月Top500榜单上的新机器。以下是所有机器的列表,按架构排序,并在每个架构内按尺寸排序:

这次新增了 44 台机器,显而易见的是,除了 LineShine 机器占据主导地位(占 6 月份新增 5.3 exaflops 总算力的 51.6%)之外,一些高性能计算中心仍在观望,倾向于在配备加速器的机器中安装“Hopper”H100 和 H200 GPU。原因显而易见。首先,Hopper GPU 更便宜,而且与后续的“Blackwell”B200 和 B300 GPU 相比,它们的 FP64 浮点运算能力更强,每美元的浮点运算能力也更高。目前,仅使用 Nvidia 计算引擎的最强新机器基于 Hopper 架构,但也有三个集群使用了 Blackwell 架构。
另一点值得注意的是,很多集群都采用了英特尔至强处理器搭配英伟达显卡。这也不难理解,因为高性能计算领域和整个行业一样,对CPU的偏好和偏好也同样存在。此外,在人工智能(GenAI)蓬勃发展的今天,价格和可用性也是一个重要因素。六月份的榜单上就有11台这样的新机器,另有9台机器采用了AMD Epyc处理器搭配英伟达显卡。这些混合架构加起来占总浮点运算能力的15.3%。
另一台大型新机器是意大利石油天然气巨头埃尼集团的HPC7系统,它基于AMD的混合CPU-GPU加速器MI300A;HPC7本质上是El Capitan系统的升级版,在榜单上排名第六。它是目前已提交计算结果的最大商用超级计算机。(不要把它和最大的商用超级计算机混淆。我们不知道全球各大石油公司可能拥有多少台更大的机器。他们很少公开炫耀。)这两台MI300A系统占新增浮点运算能力的16.3%。此外,还有两台机器混合使用了独立的AMD CPU和GPU,正如你所看到的,它们又增加了1.7%的计算能力。
这样就只剩下纯CPU算力了。新增的五个高性能计算集群仅采用AMD Epyc处理器作为计算引擎,贡献了新增浮点运算总量的0.8个百分点;另有四个新增的英特尔至强处理器集群,贡献了另外1.8%的算力。纯CPU算力机器虽然不会主宰世界,但它们也不会消失。
这里有一个有趣的小表格,比较了过去五个列表中新增机器的核心数、HPL 上的 Rmax 和 Rpeak 性能:
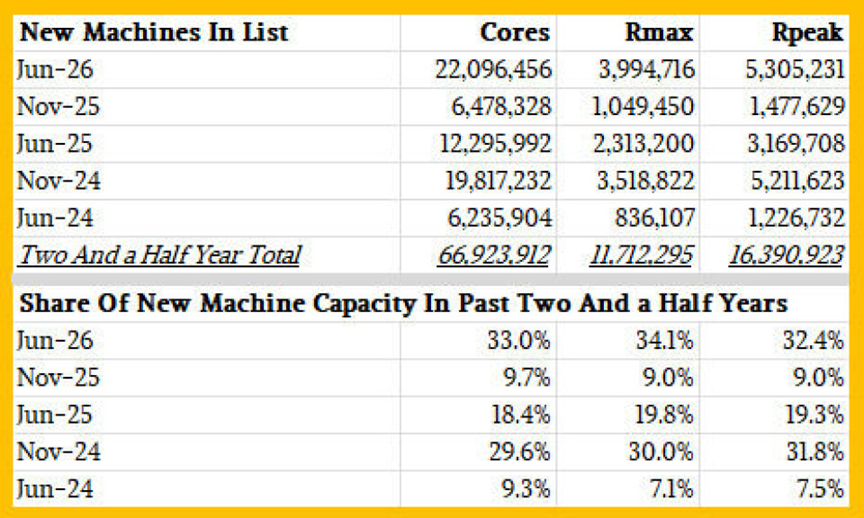
正如您所见,高性能计算 (HPC) 领域的升级呈波浪式发展,并遵循产品周期。2024 年 6 月和 2025 年 11 月的新增容量相对较少,而 2026 年 6 月和 2024 年 11 月则异常强劲。此外,值得一提的是,这主要由百亿亿次级 (exascale) 级机器的安装所主导。再次强调:这里指的并非高性能计算超级计算机,而是提交了 Top500 HPL 基准测试结果的已安装高性能计算系统。但更广泛且有时较为隐秘的高性能计算市场可能会在一定程度上反映官方榜单的情况,而这正是我们关注 Top500 榜单的初衷。
最后,我们来看看加速计算方面的情况。根据 Top500 网站的列表,共有 274 台机器具备某种形式的加速功能,尽管网站上的文字显示有 277 台机器。我反复核对了三次,结果应该没问题。以下是这 274 台机器的架构分类:

英伟达在机器数量上占据绝对优势,拥有237套系统,而AMD只有32套。但如果以峰值浮点运算能力来看,AMD的装机容量为8.18 exaflops,而英伟达只有11 exaflops。在并发能力方面,AMD售出的加速机器的CPU和GPU并发核心总数达到3530万个,而英伟达则为3890万个。这是一场真正的竞争,或许也预示着人工智能计算的未来走向。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END
今天是《半导体行业观察》为您分享的第4447内容,欢迎关注。
推荐阅读
★
★
★
★
★
★
★
★

加星标⭐️第一时间看推送