点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~

Xbotics具身朋友圈 ,记录那些把机器人推向真实世界的人。
❝这是一个新栏目。我们想和那些在一线做机器人的人聊一聊---不只是聊融资和估值,是聊他们在实验室熬过的夜,在赛场上摔过的跟头,以及那些仿真里永远测不出来的真问题。
这一期,我们对话了原力无限首席科学家、香港大学助理教授及博士生导师陈佳玉。
采访视频
先抛一个问题:如果大语言模型的成功,靠的是对互联网全部文本的蒸馏,那具身智能要蒸馏什么?
陈佳玉的答案很直接:人类的行为。但紧接着他会告诉你,光有行为还不够,因为知识和计算堆出了 ChatGPT,却堆不出一个能帮你把脏衣服收进洗衣机的机器人。中间差的那一环,他称之为“本能”。
陈佳玉是原力无限首席科学家,而他的履历也很少见:北京大学本科毕业,普渡大学博士,CMU博士后,27岁成为香港大学助理教授、博士生导师,长期研究强化学习与世界模型,研究横跨自动驾驶、强化学习理论、核聚变控制与具身智能。但他不是从机器人行业内部长出来的科学家,而是带着一套更底层、更训练有素、更扎实的方法论,进入了具身智能。
外界喜欢给他贴“少年科学家”的标签,他自己倒不在意:“我还是希望我的研究工作能被记住,希望真正做一些能够深刻改变当前具身智能现状的事情。”
在这次与 Xbotics 的深度对谈里,他把“改变现状”的路径讲得很清楚,不是卷本体,不是追热点,而是重新定义具身大脑该有的训练范式。在原力无限内部,陈佳玉教授关注的不是单点模型能力,而是一个更底层的问题:机器人要如何形成可迁移、可泛化、可持续进化的行为底座。也正是在这个问题上,原力无限把“具身大脑”从一个概念,拆解成了数据、模型、世界理解、因果推理与持续学习共同构成的系统工程。

一、机器人需要本能,而本能是需要预训练出来的
当整个行业都在把 VLA 和世界模型挂在嘴边的时候,有一个很隐蔽的盲区:大家都在套用大语言模型的方法论,但机器人需要的底层能力,和语言模型根本不一样。
“大语言模型需要的是知识和计算。有足够的知识、足够的计算,可以支持大语言模型。但有足够的知识、足够的计算,还支持不了机器人。你还需要一种本能性的东西,而这种本能,依靠现在所有的范式都训练不出来。”
他所说的“本能”,不是一个文学化比喻,而是指机器人在面对新环境、新物体、新任务时,不依赖大量人工标注和临场指令,也能基于过往交互经验快速形成合理动作的底层行为能力。
他用了一个很形象的对比。VLA 把视觉和语言直接映射成动作序列,擅长精细操作,但本质上是一种“不假思索”的反应,泛化能力弱。世界模型擅长预测未来、建模环境变化,泛化性好,但把视频流转成动作时,精细度又不够。所以行业正在形成一个共识:把两者融合,既要有世界模型的泛化性,又要有 VLA 的精细操作能力。
但陈佳玉想得更深一层。他关心的不是融合架构本身,而是训练出这个大脑之前,它还缺了一层东西:一种类似于人类先天本能的行为基座。
“本能性的行为,它某种程度上需要通过强化学习的预训练得到。或者说,非监督式的强化学习。”
这就把当前的训练范式往前推了一步。现在主流的做法是“监督学习的预训练 + 强化学习的后训练”,陈佳玉的建议是,在这两层之间,加一层强化学习的预训练。不是等模型学完了所有知识再去做对齐,而是从一开始就让它在环境中自己摸爬滚打,长出那些不经过语言、不经过标注、却能在新场景里直接起作用的行为直觉。
这听起来有点抽象,但他用自己跨领域的研究经历佐证了这条主线。从自动驾驶里做的人机交互强化学习,到博士期间的通用算法设计,再到博士后把算法用在核聚变这种极端复杂的控制系统中——贯穿始终的,就是强化学习。“我不管是在做自动驾驶,还是做强化学习的纯算法,还是在做核聚变中的控制应用,实际上都是在围绕着强化学习在做。到现在做具身大脑,强化学习几乎是可以说最重要的范式。”
二、世界模型不是拍电影,是以物体为中心的因果推演
聊到世界模型,陈佳玉抛出一个的判断:“具身世界模型和世界模型不是一个概念。”
过去一年多,视频生成模型的火爆让很多人习惯性地把“世界模型”等同于“生成下一帧”。陈佳玉觉得这走偏了。“通常讲世界模型,是生成一个电影,或者生成一个游戏,所以你逐像素、逐体素地去生成。但具身世界模型没有这个要求,你没必要逐像素进行预测。”
机器人不需要知道一片叶子下一秒怎么飘。它需要知道的,是那个杯子会不会掉下来,那只手会不会碰到障碍物。所以他提出,具身世界模型应该是 object-centric 的,以物体为中心,提取场景中的本体和被操作物体,建模它们之间的交互。
“大家都想让模型理解 physics,但 physics 说的太广泛了。通常讲的就是牛顿力学,而力学就是以物体为中心的,要看物体之间的交互产生力。所以你想让世界模型理解这些物理知识,就应该是 object-centric 的。”
这里面还藏着他对“因果”的理解。他说所有的世界模型都有时序上的因果——用过去的帧预测未来的帧。但他想要的是一种更深层的因果推断:识别物体,理解物体之间的关系,知道一个动作会对哪些东西产生影响。而语言,恰好是因果推断最自然的载体。
“现在的多模态大模型,你给它一个几何题,它能做出来。说明它已经有因果推断的能力。如果把语言模态注入到世界模型里,就能赋予它另一重以语言为载体的因果推断能力。”
这也是为什么他坚持不选边站,不走“要么 VLA 要么世界模型”的二选一,而是把两者融在一个框架里,世界模型负责对物理规律的预测和思考,VLA 负责把思考变成精细动作。前者给泛化性,后者给执行力。
三、数据飞轮的真正起点,不是机器人进了家庭
数据飞轮这个词,这几年快被用烂了。
但陈佳玉给出的判断很冷静:让数据飞轮真正转起来,不是看有多少台机器人上岗,而是看那些产生出来的数据,质量够不够好。
“现在有一些机器人已经进家庭了,会折衣服,收拾桌子。它们也会产生很多数据,但可用性可能不是那么高。比如收拾一次桌子要花十分钟、二十分钟,那用这个数据训出来的模型,它收拾桌子也需要那么久。”
这句话点破了一个循环困境:模型不够好就部署,部署产生低质量数据,低质量数据训不出更好的模型。数据飞轮没有起飞,反而变成了数据泥潭。
所以设想的一个比较现实的路径是,在初始阶段,自动化方法和模型方法结合,一边用规则兜底,一边用模型逐渐接手。“慢慢的自动化比例越来越低,模型比例越来越高,最后完全由模型自己做。”
而在此之前,真正能撬动数据飞轮的地方,可能不是家庭,反而是工业分拣这类边界清晰、容错率高、重复性强的场景。他判断,这些地方“应该很快就能实现”。
对于眼下数采设备的热潮,某一种设备并不是终极答案。“好的数据,首先 gap 越小越好。你要部署到 Franka 机械臂上,数据最好就来自 Franka 本身。但它的缺点是不好 scale。反过来,你戴个摄像机用手操作,容易 scale,但动作标注缺失,也解决不了移动操作。”
原力无限自己也在做数采产品,方向是让采集设备“无缝衔接到人们日常生活中”,而不是刻意摆拍。背后的逻辑,和他在数据飞轮上的判断一致,只有把数据采集变成一种自然行为,才有可能接近互联网级别的规模。
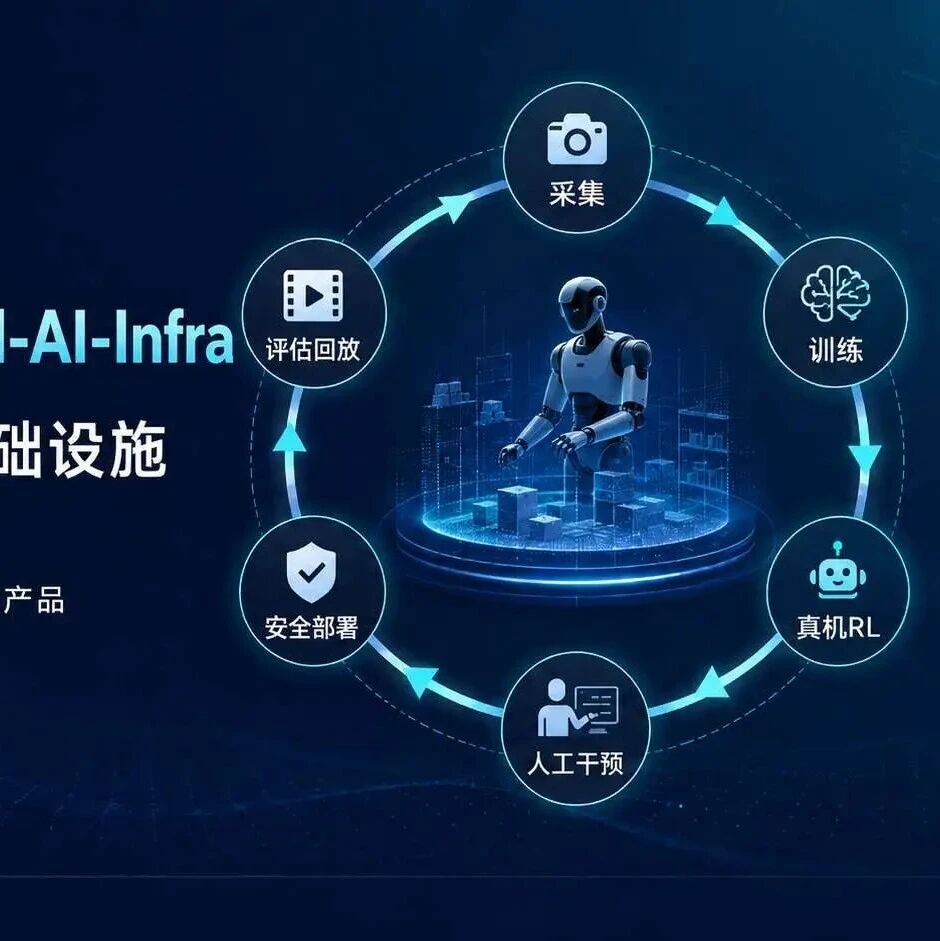
而且这也是原力无限正在强调AI Infra的原因。具身智能的数据不是简单“多采一点”就够了,而是要解决从第一视角数据采集、数据质检清洗、自标注、跨本体迁移学习,到模型训练与真机验证的完整链路问题。只有当数据从采集开始就服务于模型训练,数据飞轮才不会变成低质量样本的堆积。

四、没有失败的实验,只有你还没读懂的结果
访谈后半段,谈到了一个对许多年轻研究者来说很扎心的问题:如果自己没有顶级资源,也没有天才般的禀赋,是不是就与 AI 研究无缘了?
陈佳玉说自己也不算拥有顶级资源,博士期间导师不是做机器人方向的,团队也很小。而天赋这件事,在他看来远不如工程能力和问题定义能力重要。
“AI 实际上是有很多工程性问题的。大家聊得很热的 AI infra,你会发现模型好坏很大程度上取决于 infra 的鲁棒性,训练过程是否流畅。工程能力好,对 AI 来讲非常重要。”
至于那种灵光一现的“aha moment”,其实是一种能力:定义研究问题的能力。具体怎么练?有三条可实操的建议:关注那些 research taste 好的顶尖研究者正在做什么;去听他们在重要场合的研究愿景,那些往往是面向十年后的问题,特别适合博士选题;少看营销文章,多看第一手资料。
“营销文章帮你看看这个话题值不值得追。但真正要做研究,还是得去读那篇论文本身,这才是最重要的”
而自己的科研日常里,最难熬的部分和所有研究者一样,“你有很多 idea,花了很长时间去试,它就是 work 不了。做了两三个月,发现真的不行,逼着你放弃。但实际上是没有失败的实验结果的。你试了一个 trick 发现不 work,你总要去找它为什么不 work。它总会启迪你发现一些读论文看不到的东西。”
五、把答案留给五年后
普通家庭什么时候能用上真正能干活的机器人:5 到 10 年。他尤其希望,5 年左右能看到家庭场景里那些“大家都不太想做的家务”——衣物清洁、卫生间打扫、随手递个东西,真的被机器人接手。各行业落地的时间表会很不一样,工业、商业、家庭的节奏会错开。而唯一的共同前提,是数据不再成为瓶颈。
访谈尾声,主持人请他给大家留一句话。他说:“我希望大家把 effort 都用到同一个地方,真正做出非常好的具身大脑,尽快推动具身智能的落地。不要辜负现在国家和社会对具身智能这么大的支持力度和关注热度。你总不想说,你的研究经历中有一大段都是在做一些泡沫化的东西。” 在热潮中找到那个不变的核心问题,然后扎进去。从强化学习到核聚变,从世界模型到机器人本能,看似跨度极大的履历背后,其实一直有一条主线:让机器真正学会在物理世界里生存和行动。
这条路还很长。5 年后如果真有第二次访谈,他说自己最希望被验证的判断是:数据不再是一个 bottle neck。“因为后面的事情,实际上都是顺水推舟的事情。”

如果你也在做机器人,或者对ATEC 2026有任何好奇和想法,欢迎在评论区留言。我们很想知道:在你的经验里,机器人从仿真走进真实世界,最让你意外的那个瞬间是什么?
下期Xbotics具身朋友圈,我们会继续找到下一位有意思的人。
欢迎推荐,也欢迎自荐。有兴趣结识同行、聊聊技术的,可以扫码加群;有故事想聊聊的,也可以直接加我。

-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀