高通正式发布面向 AI 数据中心市场的突破性技术 —— 高带宽计算架构(HBC,High-Bandwidth Compute),旨在打破存储墙瓶颈。
高通HBC:叠置于 DRAM 底层的存储加速器,相较传统 SRAM 与 HBM 方案性能大幅跃升
在 2026 投资者日上,高通推出创新技术 HBC,该方案可大幅提升存储容量与带宽。HBC 架构采用专用近内存计算方案,通过 3D 堆叠芯片设计将计算单元与高带宽存储紧密键合。高通希望借助这项技术,解决长期困扰整个科技行业的存储瓶颈难题。
一份题为《高带宽内存(HBM)》的演示幻灯片列出了现有 HBM 的多项短板:单位 Token 能耗高、能效差,有效存储带宽受限,系统总体拥有成本(TCO)居高不下,幻灯片中还配有堆叠存储芯片示意图。
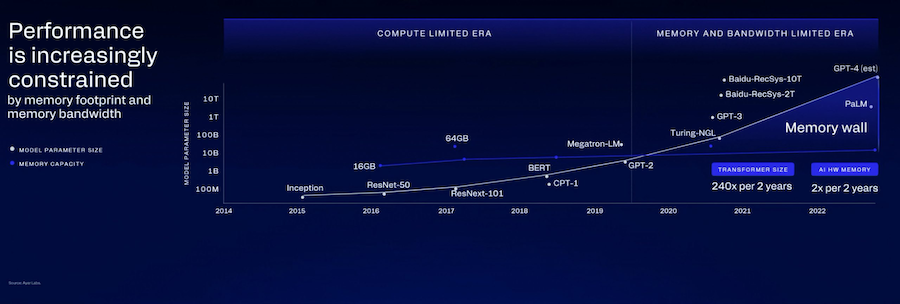
当前 HBM 是 AI 算力加速器的主流存储方案,但随着功耗持续走高,单位 Token 运算成本不断上涨,这套方案的能效短板日益凸显,进而推高整机总体拥有成本。

高通表示,全新 HBC(高带宽计算)架构可实现更低的单位 Token 能耗、更高的有效存储带宽,同时降低系统总体拥有成本。该架构依托四大核心技术根基打造:领先的 3D 集成工艺、全系统级协同设计、成熟的 LPDDR 技术积淀、顶尖功耗优化能力。
配图为高通介绍 HBC 高带宽计算技术的演示页,标注核心优势:单位 Token 能耗更低、有效存储带宽更高,搭配多层堆叠芯片示意图。

HBC 工作原理
HBC 加速器堆叠在 LPDDR 存储堆栈下方。之所以选用 LPDDR 作为存储介质,核心优势在于单堆容量更大;LPDDR 堆栈通过硅通孔(TSV)工艺与下方 HBC 加速器互连。
第一代 HBC(HBC Gen1)将搭载于新一代 AI250 算力加速芯片,HBC 赋能的 LPDDR 堆栈与芯片同置于二维有机基板。单块 AI250 加速卡带宽可达 133TB/s,相较搭载 LPDDR5X 的 AI200 芯片带宽提升 18 倍。
配套示意图标注关键组件:LPDDR 堆栈、HBC 加速器、二维有机基板、硅通孔 TSV,背景为芯片抽象结构图。

竞品对标性能
能效层面,HBC 单位功耗带宽是 HBM 的 6 倍;单位功耗存储容量是静态存储 SRAM 的 200 倍。高通将联动产业链战略合作伙伴,攻克当下 AI 行业三大核心瓶颈:存储容量、存储带宽、整机总体拥有成本。
高通演示幻灯片《多代加速器产品路线图》展示 AI200、AI250、AI300 三代产品,并预测 2029 财年全球 AI 加速器市场规模将达 6800 亿美元。

搭载第一代 HBC Gen1 的 AI250 AI 加速器预计 2027 年年中量产落地。高通同时公布远期迭代规划,第二代 HBC Gen2 配套 AI300 加速器将于 2028 年推出;相较 AI200,其有效带宽最高提升 54 倍,单位功耗带宽相对 HBM 提升 7 倍。
原文链接
https://wccftech.com/qualcomm-hbc-stacks-compute-beneath-dram-to-smash-the-ai-memory-wall
今日推荐:











