vivo BlueImage Lab团队 投稿
量子位 | 公众号 QbitAI
扩散模型又被玩出新花样了。
一直以来,提高扩散模型生成质量的关键手段,是在推理阶段加入引导(guidance)。
要么依赖文本条件(如CFG)——需要专门的训练策略,没有文本条件就不能用;
要么靠显式加噪破坏模型推理——然而效果有限。
现在,一种全新的思路来了:
不需要文本条件,不加噪声,不改模型,只在内部交换token。
来自上海交大和vivo的研究者提出了一种十分简单但非常有效的方法:自交换引导(Self-Swap Guidance,SSG)。该工作已被CVPR 2026国际会议接收为Oral。

一句话总结:
通过在空间和通道维度上交换token特征,把模型“搞差”,再用这个“变差”的路径去指导自己的生成。
听起来简单,但却十分奏效。
现有方法有什么问题?
当前主流的引导方法是CFG (Classifier-Free Guidance):简单来说,就是用“有条件输出”和“无条件的输出”做差,得到从“没那么符合语义”到“更加符合语义”的预测的一个方向,引导模型朝更这个由差到好的方向走,从而引导出更符合语义的生成,但它有一些主要的局限性:
必须依赖文本(prompt)的存在(没文本引导不了) 需要专门的训练过程(随机丢掉文本条件输入) 高Guidance Scale时容易过饱和、细节崩坏、多样性下降……
最近也有人尝试“无条件引导”(condition-free guidance),也就是不需要依赖文本也能够进行引导,比如:
SAG(往输入加噪声) PAG/SEG(往attention加噪声) TSG(往timestep向量加噪声)
但这些方法有个共同的问题:扰动添加的粒度比较粗——要么可能不够强,要么太过头。结果就是小扰动没什么引导效果,大扰动直接让图变的没法看。
如下图,现有的无条件引导方法在低引导系数下生成质量欠佳,在高引导系数下出现图像失真、过饱和、高噪声等现象。相比之下,自交换引导(SSG)的生成质量对引导系数更加鲁棒稳定。

SSG的核心想法:不加噪声,只做“结构性”
SSG的思想非常简单:与其加噪声,不如直接对部分特征进行“重排”。具体做法是,对于模型内部的token特征进行两个维度上的随机交换:空间维度自交换(spatial self-swap)和通道维度自交换(channel self-swap)。
在实践中,研究者发现随机选择token或者channel对进行交换就能起到比较明显的引导作用,而两两交换“最不相似”的一些token或channel对,引导效果最好,图片质量最佳。其原因在于可以实现更加充分的破坏,而不需要全局加噪。
具体做法是,使用两个前向推理分支。其中一个不做任何改动,原封不动地让预训练模型输出噪声预测(ϵori)。另一个分支会在模型的特定层执行自交换扰动,先在空间维度进行一些最不相似token的交换,再在通道维度进行一些最不相似通道的交换,最后得到经过扰动的噪声预测(ϵpert)。
在推理的每个时间步上,用两个分支的噪声预测做差,用这个方向对原始噪声预测进行一个修正,修正的强度由引导系数/omega控制,这一引导过程与CFG很相似:
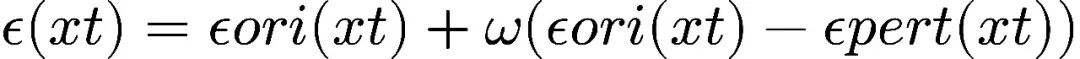
这种引导在每个时间步都会做一次,指导所有推理步都走完,就获得了经过引导生成的质量更高的样本,就是这么简单。
实验结果
研究者在无条件、有条件生图的设置下,使用COCO2014、COCO2017、ImageNet等多种真实图像数据集验证SSG的引导效果。在这些实验中,SSG在多个指标上超过了现有的SAG、SEG、PAG等无条件引导方法。

△SD1.5模型无文本条件生图在ImageNet上的定量实验结果
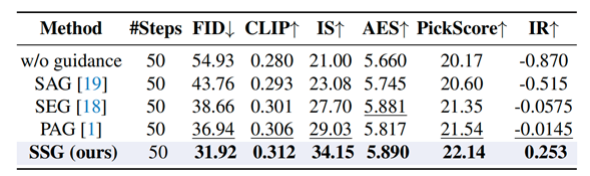
△SDXL模型有文本条件生图在COCO 2017上的定量实验结果
具体而言,采用的定量指标包括FID(衡量分布差异)、CLIP Score(文本遵循程度)、Inception Score(质量与多样性),以及肉眼质量指标(AES、PickScore、ImageReward)。对无条件生成也使用了Precision和Recall衡量质量与多样性。SSG在这些指标上均取得了优异的结果。

通过对比实际生图效果,可以发现SSG可以更稳定地生成较高质量、更加自然的图片,在有文本条件的生成设置下,与文本的一致性更好。随机交换的性能已经超过多个现有方法,而“最不相似”交换策略可以获得更优的生成质量。

△Token交换策略的消融实验
研究者对于不同的交换策略进行了对比,其中随机交换就已经能实现相当不错的引导效果,甚至比此前的方法都要好。交换最不相似的token特征在两项人类偏好分数上更优,整体上实现更佳的指标权衡。通道交换效果整体优于空间交换,二者结合使用可以实现图像质量和美学感知分数的最佳权衡。
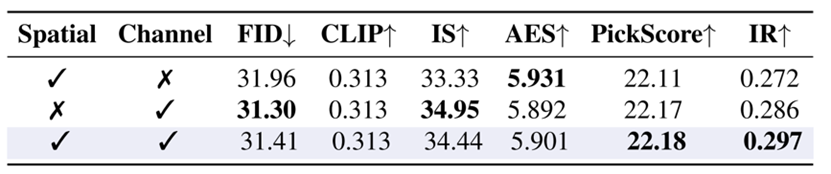
△空间与通道交换策略的消融实验
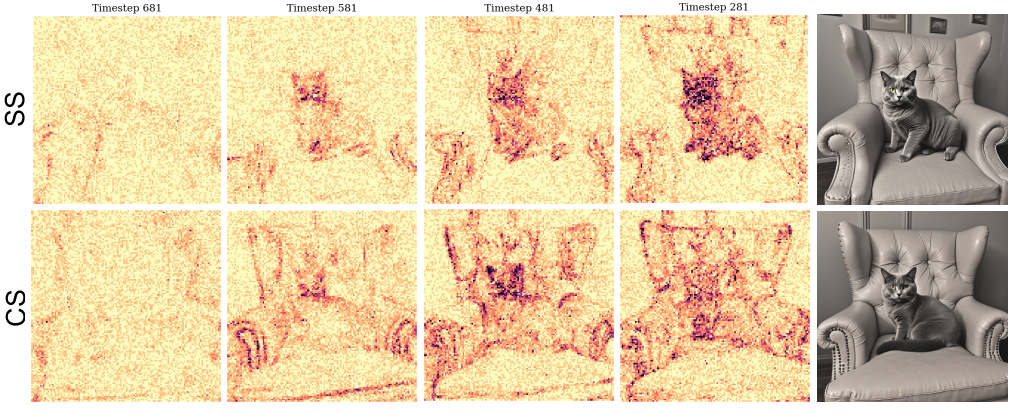
通过对空间、通道两种交换技术进行消融实验,可以验证两种方法都能有效地引导生成,通道交换的效果整体上优于空间交换,而两种交换同时使用可以实现更好的总体效果。因此可以说两种交换在一定程度上互补——对其引导模式的可视化也展现出明显的区别。如下图,通过可视化可以发现两种交换的引导模式差异明显。
一些其他探讨
SSG与同期工作TPG都在特征的空间维度上引入了扰动设计——SSG选择部分token进行空间上的位置交换,而TPG直接对所有token进行随机重排列。在指标上来说,SSG的最不相似token交换方案略优于TPG的token随机重排列,而计算开销也大于后者。
此外,SSG首次揭示了特征通道维度上的扰动对于引导扩散模型的显著效果,并且发现通道维度扰动的引导效果显著优于空间维度,这一现象为后续设计更高效的引导机制提供了新的思路。
至于该研究的局限性,首先是缺少系统性的理论支撑,以及其方法性能对于扰动添加的具体层位置较为敏感。这些也是扩散模型引导系列工作普遍存在的问题。因此,如何从理论层面对其有效性进行解释,并设计更鲁棒的扰动机制,仍是值得深入探索的方向。
另外,在模型内的多个层分别计算token相似度会引入一定程度的计算开销,对SSG计算效率的优化也将是具有实际意义的后续课题。
关于vivo BlueImage Lab
蓝图影像创新实验室,主要负责移动影像算法创新,包括图像/视频处理、图像/视频交互、图像/视频增强、多模态理解大模型等方面的技术前沿探索。
致力于不断提升vivo移动影像的算法能力,使用户能够拍摄出更加清晰、美观的照片和视频。同时积极探索增强现实、具身智能等新兴技术领域的应用,努力为用户提供更加丰富和便捷的影像体验。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
【学术投稿】请在工作日发送邮件至:ai@qbitai.com,标题注明【投稿】,并告诉我们:你是谁,从哪来,投稿内容附上项目/主页链接,以及联系方式。
🌟 点亮星标 🌟