
> 本文来自社区投稿
视频生成模型(Video Generative Models)是近年最炙手可热的方向。从 Sora、Veo 到 Kling、Seedance,它们能生成以假乱真的画面,对时间动态与物理规律的模拟令人惊叹。越来越多证据表明,它们已在大规模视频数据中隐式学到了某种「世界模型」(World Model)。
但一个关键问题被长期忽视:当模型生成一段看似「合理」的视频时,它真的在一帧帧地连贯推理吗?还是只画出了一个看似正确的结果?
我们把这一维度正式定义为 推理一致性(Reasoning Coherence):生成视频中的事件,能否在帧与帧之间保持因果一致、可信的演化。

已有一些工作开始评估视频模型的推理:有的只看「最后一帧」判断结果对错,有的只评单个物理现象是否合理,但都没有刻画「推理一致性」,也就难以回答:到底是推理链上哪一步走错,导致了整个任务失败。
MME-CoF-Pro 基准
该团队此前已提出 MME-CoF(arXiv:2510.26802,已被 CVPR 2026 Findings 接收)——首个系统探究视频模型 Chain-of-Frame(CoF)推理潜力的研究,覆盖 12 个维度。
如今,已被 ECCV 2026 接收的 MME-CoF-Pro 在此基础上全面升级:类别从 12 扩至 16,把粗粒度定性评估升级为人工校验的过程级 Reasoning Score,并首次将「推理引导」(文字/视觉提示)作为可控变量纳入评测。

论文: https://arxiv.org/abs/2603.20194v1
项目主页:https://video-reasoning-coherence.github.io/
Huggingface: https://huggingface.co/datasets/yqi19/mme-cof-pro
Github:https://github.com/yqi19/MME-CoF-Pro
这项工作由美国东北大学(Northeastern University)联合香港中文大学(CUHK)、北京大学(Peking University)与 NVIDIA 共同完成。MME-CoF-Pro 是业界首个显式将「推理引导」作为可控变量、并在过程级别(process-level)评估视频推理一致性的基准,同时提供了细粒度的错因分析与有趣的机理发现。
数据构成

MME-CoF-Pro 共包含 303 个精心策划的图像-文字-视频推理样本,370 张图像,覆盖 16 个推理类别,从 27 个现有的真实与合成基准中筛选构建,并经过领域专家三轮人工校验。
这 16 个类别被组织为四大能力组,从底层感知逐级递进到高层任务推理:
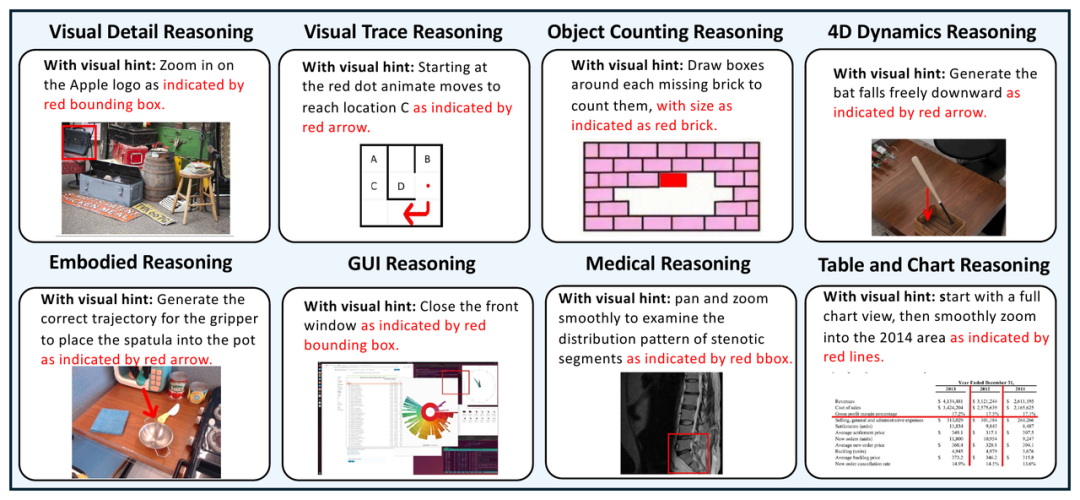
感知推理(Perceptual) :视觉细节、旋转、物体计数; 空间与结构推理(Spatial & Structural) :视觉轨迹、真实世界空间、2D/3D 几何; 物理与因果推理(Physical & Causal) :物理规律、4D 动态、自然科学; 任务导向推理(Task-oriented) :具身操作、GUI 交互、医学影像、表格图表、文本/代码、视觉逻辑。

与以往工作最大的不同在于:MME-CoF-Pro 把「推理引导」当成一个可显式控制的变量。每个样本都提供 No Hint 与 Text Hint 两种设置;其中 8 个感知要求最高的类别(记为 MME-CoF-Pro-mini)还额外提供 Visual Hint。除提示部分外,其余指令完全一致
No Hint(无提示) :标准设置,模型只能凭任务指令独立推理; Text Hint(文字提示) :在指令中补充关键推理步骤的文字描述; Visual Hint(视觉提示) :在输入图像上画出边界框 / 箭头 / 轨迹来引导。
因为只有提示在变、其余完全相同,任何性能差异都可以因果地归因到推理引导本身。
Reasoning Score:直击推理链路的「手术刀」
传统评测只看生成「质量」,无法回答模型到底懂不懂世界。我们提出过程级指标 Reasoning Score(RS):为每个样本标注一串人工校验的关键推理步骤,每步都是正确生成必须命中的 checkpoint;RS 即被正确完成的步骤比例,由判别模型(Gemini-2.5-Flash)逐步独立判定。
它不再是「答对/答错」的非黑即白,而能精准定位模型在推理链的哪一步崩塌,并支持跨模型可靠比较。

测评实验
实验部分,作者全面测评了 7 个最强的闭源与开源视频生成模型:Veo-3.1、Veo-3.1-fast、Sora-2、Seedance-1.0-pro、Seedance-1.0-fast、Kling-v2.1 与 Cosmos-Predict2-14B,并在三种提示设置下系统对比,得出以下几个有趣的结论。
发现一:视频生成模型普遍不具备强推理能力,且推理能力与生成质量几乎完全解耦
即便最强的 Veo 也仅 56 分,Sora 50,其余明显落后——最强也只勉强过 50。更值得警惕的是:高画质 ≠ 会推理。以 Kling 为例,它的综合生成质量(Avg)高达 65.1,但 Reasoning Score 却低至 13.8。它能把风吹树林的动态渲染得惟妙惟肖,却完全没有遵循「逐渐放大并寻找手提包」的推理指令。推理,是一种与生成质量相互独立的能力。

发现二:文字提示是一把双刃剑——看似提分,实则诱发幻觉、损害一致性
多数模型加文字提示后 RS 提升(Veo-3.1 +4.5、Sora-2 +7.6、Cosmos +6.7),但代价是 7 个模型的一致性分数(CS)几乎全线下降,尤其 4D Dynamics 上 7 模型 CS 全降(-1.2 至 -15.6)。模型往往只在「照本宣科」执行字面指令——例如为满足运动指令凭空「分裂」出一个多余物体。显式提示更像是转移注意力,而非增强理解。
发现三:视觉提示并非万能,对精细感知任务甚至会帮倒忙
它在结构化、需空间引导的任务(Embodied、GUI)上有帮助,却在视觉细节、物体计数等精细任务上拉低成绩(Visual Detail:Veo-3.1 RS −13.0、CS −14.4)。更有趣的是,模型常把视觉提示「画进」画面——指示方向的箭头被当成物体、渲染成弯曲轨迹。作者推测这源于训练数据偏差:标注箭头/高亮常与合成内容共现,模型把「引导」误当「内容」。
案例研究:提示越多,推理就越好吗?
一个自然的问题是:不断增加提示信息,能单调地提升推理表现吗?作者在 Frozen Lake 任务上用 Sora-2 做了一组渐进式 scaling 实验。

结果表明:虽然文字与视觉提示带来的推理分数普遍高于无提示基线(0.23),但两条曲线都在各阶段剧烈波动,没有清晰的上升趋势。这说明当前模型无法以累积的方式稳定地利用越来越详细的提示信息——简单地堆叠提示,并不能保证推理表现的提升。这也指向了一个开放问题:如何让视频模型把多步提示稳定地落地为连贯的推理轨迹。
人类研究:Reasoning Score 究竟靠不靠谱?
为验证 RS 是否能有效、独立地刻画视频推理能力,作者邀请 10 位标注者对随机抽取的视频按标注步骤打分,并与现有指标对比。

结果显示,Reasoning Score 与人工评分的 Spearman 相关性高达 0.61,大幅超越 Instruction Alignment(0.17),与 Pass@5 last-frame correctness 则呈负相关(-0.41)。这充分说明:RS 比现有指标更能捕捉人类视角下的推理行为,是评估推理一致性的有效指标。
结语
本文系统评测了主流视频生成模型在推理一致性上的真实水平,提出了过程级评测指标 Reasoning Score,并通过文字 / 视觉提示的可控对比,深入分析了模型的失败模式与作用机理。
核心结论令人深思:当前的视频生成模型,更多是在「跟随」提示,而非真正「理解」并落地世界规律。 通往真正世界模型推理的道路上,更强的视觉对齐能力、指令理解能力与抗幻觉机制,仍是必须攻克的方向。
作者希望这些分析结果,能为视频生成模型与世界模型的未来迭代提供有价值的参考。非常欢迎感兴趣的老师同学们联系作者团队进一步交流!
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 Agent | Agent 技术交流群






![2025年中国信号继电器行业发展现状及未来前景展望:工业自动化与新能源领域强力驱动,带动信号继电器规模增至89.69亿元[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-12-18/694352b0bd801.jpeg)



