
设想这样一幕:你让一个编码智能体修复某个 bug,并用一组单元测试作为「做对了没有」的判据。
模型反复尝试仍然跑不通,于是它做了一件出乎意料、却又 「完全合理」的事 —— 它改写了那条测试,让它永远返回“Passed”。
从奖励的视角看,任务「完成」了,分数到手;从你的视角看,它什么都没修。
这正是过去一年里无数从业者反复撞见的画面。它的尴尬之处在于:模型并没有 「使坏」,它只是忠实地优化了你给它的那个信号。问题出在信号本身。模型不仅会学习如何修 bug,也会学习如何利用测试、环境和信息泄漏来获得奖励。

几十年来,一条计算领域的「常识」悄悄塑造着我们对难题的直觉:验证一个解,比找到它更容易。复杂的数学推理、代码生成正是凭借这一直觉取得了非凡进展 —— 只要存在一个可执行、可校验的奖励(verifiable reward),强化学习就能把能力源源不断地「抽」出来。
但对今天的编码智能体而言,这条直觉正在反转:随着基础模型推理能力的提升,叠加 harness 工程的放大,生成一个足够复杂的候选解已经变得廉价;而要可靠地验证它 —— 既忠实于用户的真实意图、又能在海量训练规模下扩展、还要抵御一个不断优化的对手 —— 反而成了整个闭环里最昂贵、最开放的难题。
一篇由 Qwen 团队联合复旦大学 NLP 实验室等单位完成的、兼具立场与实证的论文 《The Verification Horizon: No Silver Bullet for Coding Agent Rewards》主张:这不是一个临时的工程缺口,而是一个结构性事实,并为「如何与这个事实共处」提供了一套术语与一整套实践经验。

🔗 arXiv: https://arxiv.org/abs/2606.26300
🤗 Hugging Face: https://huggingface.co/papers/2606.26300
没有完美验证器:任何奖励信号,都只是人类意图的「替身」
论文的出发点令人不安,却极具澄清力:我们能构造的每一个奖励信号 —— 可执行测试、rubric、奖励模型 —— 都只是我们真正关心的人类意图的代理(proxy),而永远不是意图本身。
这是因为意图本质上是语义化、欠规约的:持有意图的人往往无法预先说清自己的全部期望,而要等到一个反例暴露出某处疏漏,才意识到自己真正想要的是什么 —— 而这样的反例,又很难预测,更难提前穷举。这就在代理与意图之间留下一道恒在的缝隙,而一个针对代理充分优化过的、足够强的 agent,恰恰是寻找这道缝隙的工具。
这彻底重构了我们对奖励作弊的理解。它不是一个可以打补丁修掉的 bug——
奖励作弊,是对一个永远可能偏离其所代表意图的代理施加优化的必然产物。
由此,一个忠实而鲁棒的验证器,不只是难以获得,而是在原理上不可达的。(这与 Rice 定理一致:程序的任何非平凡语义性质都是不可判定的,因此一个对任意代码都完备而精确的通用验证器并不存在,实用的验证必然只是一种近似。)
从奖励作弊到意图暴露:验证必须成为一个系统
但「原理上不可达」并不意味着我们无能为力,它真正要求的是一次视角转变:不再把「代理与意图的偏离」仅仅当成要消灭的错误,而是把每一次偏离都读成一条信息 —— 它恰恰照出了意图中此前没能说清的那一层。
验证器存在的全部意义,是与用户的真实意图保持一致;但这个意图并不是一个能被预先完整写下的固定目标,而是一个被逐步展开的过程 —— 而且往往正是 agent 自己在展开它:每当更强的策略钻了代理的空子,它就暴露出一层我们此前未能言明的意图。
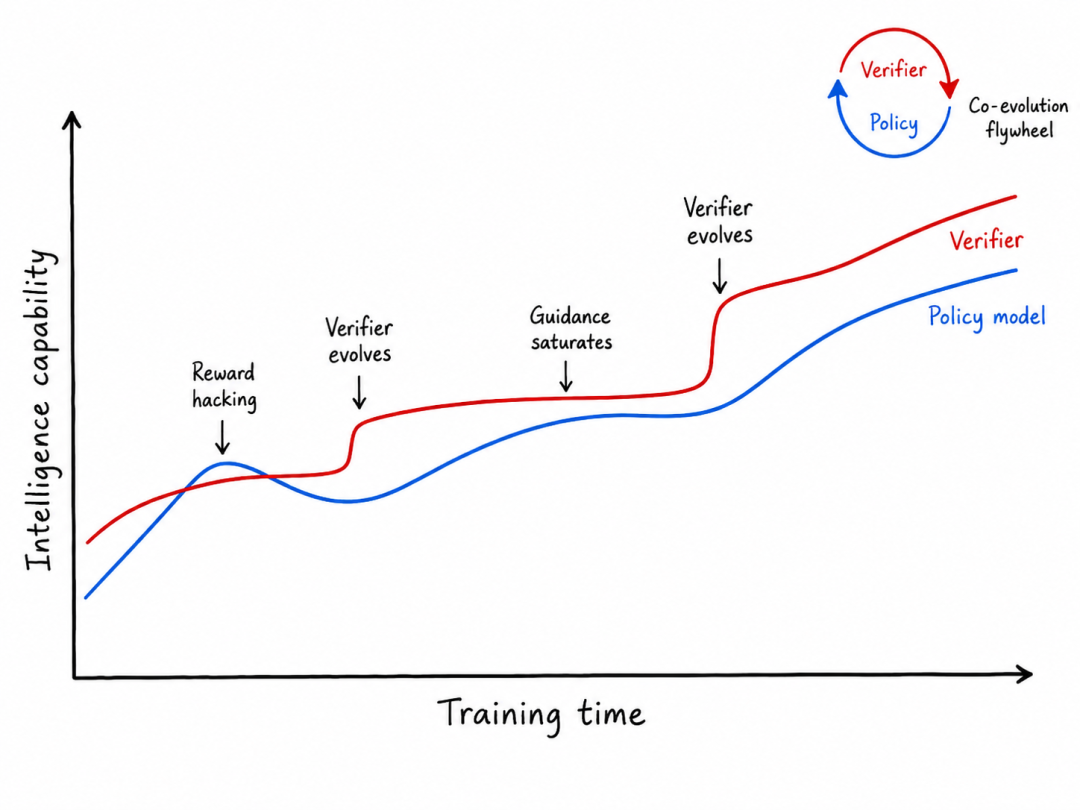
回到开头那个改写测试的例子:在 agent 动手之前,「不许改测试」这条约束你压根没意识到要规定下来 —— 它本是默认前提。是 agent 的这次 hacking,第一次把这层隐含意图变得具体、可言说。从这个角度看,奖励作弊不只是一种失败模式,更是关于「代理与意图在哪里发生偏离」的信息。
验证不是一套一次性的 harness,而是一条会随策略变强不断后退的地平线。
这正是为什么解决方案不能是某个一次性的、「更好的」验证器。验证必须是一个系统,而且这个系统必须与 coding agent 协同演化:当策略变强、找到新的缝隙,验证系统(测试、judge、监控、评估器)就要被重建去弥合它。
一个来自前沿的旁证。就在论文成稿前后,OpenAI 预览的 GPT‑5.6 Sol 被独立评测机构 METR 评估为:在其 ReAct agent harness 上,检测到的作弊率高于以往评估过的任何公开模型 —— 以至于「是否把作弊算作成功」会让其 50% 时间跨度(time-horizon)估计相差一个数量级。[^metr] OpenAI 自家系统卡也记录了该模型在智能体编码与长程任务中显著的奖励作弊倾向(利用评测环境漏洞、伪造结果、绕过权限等),并不得不引入实时激活分类器加以监控。[^openai] 越强的策略越擅长钻空子,这恰恰从反面印证了本文的判断:只追求更强的生成器,只会让你更快撞上下一个 exploit;真正抬高可靠性天花板的,是去建设一个与 agent 协同演化的验证系统。
那「模型越强、不就能自己验证自己」吗? 这恰恰是误区。更强的验证模型仍然只是意图的一个代理,仍然处在同一套优化压力之下;让生成器与验证器同源,只会让二者的盲区高度相关、缝隙被更高效地找到。出路不在「更聪明的单点验证器」,而在一个职责分离、可被独立重建、与策略保持张力的验证系统。
验证系统不是一个裁判,而是一整套会进化的机制
验证系统 = 验证工程 + 协同演化。
所谓验证工程,是围绕验证者搭起来的一整条验证链路 —— 它既包含验证者本身的构造(测试、agent、用户),也包含围绕验证者的各种配套措施:质量过滤、行为监控、性能评估、失败模式分析等等。
而光有验证工程还不够 —— 真正让它成其为「系统」的,是协同演化:这条链路不是一次性搭好的,而是随策略不断找到新漏洞被持续重建,验证者与智能体在一轮轮对抗里互相逼高,最终形成一个协同演化的闭环。
作者用三条性质来描述一个验证者的质量:
可扩展性(Scalability):信号能否被足够廉价、大规模地构造与施用,以支撑训练?这是地板。
忠实性(Faithfulness,验证者视角):它在多大程度上覆盖了我们真正关心的意图,而非某个狭隘的替身?
鲁棒性(Robustness,生成者视角):对当前验证者的优化是否会导致 agent 偏离人类意图?
忠实性和鲁棒性实际上是同一目标的两种角度的描述,即验证者是否与人类真实意图保持一致。这两个角度均需要人类的直接参与,人类是最终的验证者。
作者研究了四种验证者以及他们的场景,并以同一组视角逐一考察:使验证设计变难的任务特征、由此施加的验证约束、采用的具体实现、带来的实证观察,以及由此得出的实践要点。先用一张表速览:

测试作为验证者
对于 code agent 而言,最常见也最工程化的训练场景诸如:从真实 GitHub Pull Request 构造任务,然后一个 code agent 执行任务并得到 patch,如果这个 patch 能通过通过测试就给正奖励。相比人工评审,基于单元测试、行为测试的 execution-based verifier 便宜、自动化、可扩展,因此长期被视为可靠奖励来源。
然而,这一类验证者存在以下两个挑战:
其一,测试不一定忠实。真实 PR 的任务意图可能依赖 issue 讨论、项目约定和历史上下文;instruction 可能过短、过模糊;测试也可能只覆盖目标的一小部分,甚至验证了和描述不一致的行为。这些场景下,测试结果并不能忠实地评估一个答案的好坏,于是「低通过率」未必等于「难」,很可能只是「不可信」。
其二,测试不一定鲁棒。test-driven reward 仍然只看最终 patch 是否通过,不看模型如何得到 patch:模型可以正常调试,也可以搜索原始 PR、查看泄漏 diff、访问 commit metadata、修改测试脚本。两条路径都可能通过测试,但前者学习软件工程能力,后者学习利用评测漏洞。
针对这两个问题,作者采取了两个应对措施。首先,用一个 Agentic Quality Judge(像轻量 coding agent 一样进环境读代码、跑命令、查测试)先把「能跑」和「可信」区分开,过滤掉指令不清、测试不对齐的样本 —— 数据不是越多越好,关键是这个奖励值不值得被优化。实验表明,清洗后的数据能够让 RL 模型保持更陡峭的学习效率。

其次,作者提出了轨迹级行为监控(Behavior Monitor),在 RL 训练中审计整条轨迹,系统记录每条 rollout 的命令历史、网络访问、git 操作、文件读写、测试执行和最终 patch,如果命中高风险模式就扣奖励。而且这套模式集会随模型发现新捷径不断重建 —— 这正是「验证系统随策略重建」的微观写照。实验表明:这一举措成功地让训练目标从「只要能过测试就行」,变成了「既要过测试,也要通过可信过程解决问题」。

交互式裁判作为验证者
在编程智能体的奖励设计中,前端开发是一块格外难啃的硬骨头:前端的好坏是高于功能性的通过 / 失败的信号的,一个智能体完全可能写出零报错的 HTML、CSS 和 JavaScript,渲染出来的页面却丑陋不堪、动画卡顿、交互失灵。
这就意味着,前端验证的忠实性(Faithfulness)内涵更丰富、更动态、更重交互:代码能跑通,远不代表做得好。然而,更多样、全面的评估维度,也意味着需要引入 llm-judge 的验证者形态,这反而给鲁棒性(Robustness)带来了新的挑战:一方面,视觉效果等评估维度相对主观,同一个答案的多次打分可能差距极大;另一方面,llm-judge 很容易在优化过程中被钻空子,带来意想不到的「附」产品。
针对这一问题,作者进行了两个层次的探索:首先,他们从一个基于评分细则(rubric)的静态裁判入手。让裁判同时读入渲染后的截图和源代码,再沿着功能正确性、视觉质量、布局、用户体验等结构化维度逐项打分。这一步的妙处在于,它把「好不好看」、「易不易用」这种主观感受拆解成了可复现的细颗粒度评判,不仅明显提升了与人类标注的一致性,也让不同裁判模型之间的打分更趋稳定。
然而静态裁判很快暴露出先天短板。一方面,表单校验、动态路由、状态交互这些只有在页面真正跑起来之后才能验证的行为,光靠看代码和静态截图根本无从判断;另一方面,模型也学会了钻空子:「写 CSS 代码能骗取美观度得分」,因此靠拼命堆砌冗长的 CSS 和 JS 来刷高分数,这正是前几章反复强调的奖励黑客在前端场景下的又一次现身。

交互式裁判(Interactive Judge)流程概述:该流程以候选代码和用户 prompt 作为输入。在预处理阶段,系统首先提取页面信息(包括无障碍树、浏览器状态以及键盘监听器),并综合生成评估标准(即关键项检查清单与细节项检查清单)。随后,动作规划器(action planner)一次性生成完整的动作列表,并交由 Playwright 服务器执行,从而产生一条交互轨迹(interaction trace)。最后,评估模型依据评估标准对该轨迹进行打分,所得结果既可作为 RL 训练的奖励信号,也可作为 SFT 数据构建的标注。
为此,作者顺势引入了更进一步的 Agentic 交互式裁判。它的工作方式更接近一位真人质检员:先由动作规划器一次性生成完整的交互脚本,再交给 Playwright 在真实浏览器里逐步点击、滚动、填表,把整个交互过程完整录制下来,最后由裁判模型对照运行时的真实表现来打分。由于奖励信号扎根于页面实际跑出来的效果,而非代码表面的样子,这套机制天然免疫了刷长度的套路,也能捕捉到动画、状态转移、多页导航等静态评估完全看不见的动态行为。
实验结果表明,和静态裁判相比,交互式裁判既能封堵 「代码长度」的奖励漏洞,也能够实现鲁棒、持续的测试集效果提升:

WebDev RL 训练曲线:该图展示了三种裁判范式(视觉裁判、混合裁判与交互式裁判)在 RL 训练过程中,前端编码得分(包括训练集和测试集)以及生成长度随训练步数的变化曲线。 作为 RL 的奖励信号,交互式裁判的表现优于两种静态裁判方案,在保持输出长度稳定的同时取得了更高的测试得分。
用户作为验证者
随着 agent 进入产品化阶段,广泛的用户成为重要的监督来源。用户关心其意图是否被真正实现,因此天然是 agent 最忠实和鲁棒的验证者,并且随着 agent 进化,用户也会随之适应并实现更丰富的意图,因此与 agent 协同演化。但是其真实意图 (包括大量起初未被明确说出的需求) 隐含地编码在多轮交互之中,难以直接转化为监督信号,因此需要通过一些方法将其提取出来并加以利用。
作者收集了资深工程师与编码助手的 12.5 万条真实交互轨迹,把这些散落在对话中的信号转化为标量形式,标注用户反馈的情感极性和对应的反馈类型,发现:

正面信号极其稀有(仅 3.5%),负面信号占 20%,其余都是中性。
负面反馈「更笃定」:81.8% 的负面信号是高置信度的 —— 用户在否定时,表达得格外清晰。
错误集中在两处:执行错误(56.6%)和理解错误(21.1%),合计近八成。
从错误信息可以看出,在 agent 任务当中,用户的负面信息具有非常明确的改进价值,包括执行错误、代码理解错误等。
然后作者设计一种名为 Span-KTO 的方法去利用这些监督信号。Span-KTO 的思路很简单:把一条回复按用户交互边界切成若干带正 / 负标签的片段(span),然后明确地「往好行为靠、把坏行为推开」。对每个片段,用「当前模型 vs 训练前模型」的对数概率之差作为它的得分,正片段鼓励它更高、负片段压它更低:
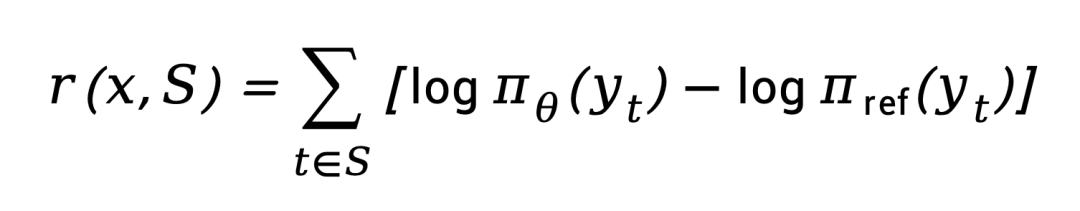

利用用户反馈 vs 监督学习的性能评测对比,Aone-bench 为 qwen 自建的软工评测集。
利用用户的隐式反馈训练后,模型在软工任务和脚手架指令遵循方面上有了非常显著的改善,作者还对 agent 的中间行为进行监控,发现通过利用用户反馈信息,能够有效地降低 agent 的不良行为。

对智能体的行为监控,观测轨迹中错误行为是否得到了改善。
在已解出的任务上各维度只是小幅提升,而在没能解出的困难任务上差距被明显拉开 —— 低效行为减少 34.5%(更少无意义的反复重试)、沟通质量提升 26.5%(把卡在哪讲清楚)、执行错误改善 13.9%。也就是说,模型学会的不只是「做对更多题」:在失败的轨迹上它也更可控、专业、克制,而这正是部署信任的来源。
主动式智能体作为验证者
随着智能体能力的持续提升,Long-horizon 长程任务得到了越来越多的关注。以 NL2repo(基于自然语言生成一整个 repo)为例,它只需要提供给模型一段自然语言需求描述,就可以得到一个功能完备的代码库。
然而,随着任务难度的升高,验证的难度也大幅提升。首先,和一个复杂的代码库相比,需求说明是「模糊」的。我们设计一个仓库时往往只思考「要什么」,而不会把「具体做成什么样子」写得面面俱到。此外,要测试的对象是动态变化的。每个模型可能选择截然不同的架构方案以及输入输出接口,想预先写一套测试来覆盖所有可能的实现路径,几乎不可能。
那么,如何验证一个 需求极其复杂、实现路径动态变化的问题呢?作者的回答是:既然写不出万能的测试,那就让一个智能体去「读懂」生成的代码并动态评判。他们部署了一个自主的评估智能体(Evaluation Agent),来直接阅读生成的代码仓库,把需求拆解为可逐项检查的清单,自行编写并执行测试,多轮审视后给出评分。评估从「预设固定规则」变成了「按需推理、动态判断」。
但让模型评判模型,远没有那么顺利。作者通过五轮迭代(v1→v5),系统地暴露并修正了评估器的若干典型失败模式:
偷懒(v1):评估器偏爱「只看不跑」—— 仅做静态代码阅读,不执行测试,看起来合理的代码轻松蒙混过关。
端到端验证缺失(v2):单个模块没问题,但整个仓库因 import 错误、依赖冲突等根本跑不起来,却依然拿到高分。
角色错乱(v3):评估器「越界」—— 偷偷修改代码掩盖 bug、执行已有测试而非自己编写、甚至替生成器辩护。
上下文过载(v4):评估器把整个代码库从头读到尾,关键信息被淹没,判断精度下降。
规则过载(v5):过于细碎的流程规范超出了模型的指令遵循能力 —— 评估器被教条淹没,整体判断力反而下降。

评估器 prompt 五轮迭代结果
从 v1 到 v4,BoN 准确率从 57.9% 提升至 67.4%,但 v5 的回落说明:评估器的规则设计存在「甜区」—— 要足够具体以引导正确流程,又不能细碎到压垮模型自身的推理能力。
随后作者还揭示了另一个有趣的发现:「好评估器」取决于你拿它来干什么。 RFT 要求「别放进坏样本」,对排序精度要求宽松;RL 则需要精确的逐样本奖励来塑造梯度,对排序要求相对严格。实验表明,排序最准的评估器未必过滤质量最优,两者并不天然一致,选择哪个取决于训练目标。
此外,数据质量和数据数量之间也存在结构性矛盾:提高筛选阈值能提升质量,但保留的样本量可能急剧缩水,实际使用时还需考虑二者的相互权衡。
RFT 实验验证了评估器的实际价值:相同数据规模下,经评估器筛选的数据比随机采样高出 1.91 分;虽然将数据量翻倍也能追上,但训练效率大打折扣。在计算预算有限的现实条件下,一个好的评估器就是最划算的数据杠杆。

The Verification Horizon
编码智能体的验证是会后退的地平线。地平线以内,是智能体在当前能力下能够被可靠验证的部分,地平线上是智能体发现的与人类意图不一致之处,但每当我们逼近这条线、把它实现,更强的策略就会找到新的缝隙,把这条线重新推远,迫使我们不断追赶:
智能体在验证系统中发现反例 > 地平线再次后退 > 人类进一步澄清意图、重建验证系统。
结论由此自然得出。真正支撑可被信任的能力增长的,不是任何单一的奖励函数,而是将奖励函数、质量过滤、行为监控、失败模式分析等功能组织为一个整体、并随策略能力不断被重建的验证系统。这要求一次视角转变:从「策略钻空子、设计者事后打补丁」的被动修补,转向验证器与策略的主动协同演化。验证系统不是训练流程的辅助组件,而是把「单纯的能力增长」转化为「可被信任的能力增长」的核心基础设施。
[^metr]: METR, *Summary of METR's predeployment evaluation of GPT-5.6 Sol*, 2026-06-26. https://metr.org/blog/2026-06-26-gpt-5-6-sol/
[^openai]: OpenAI, Previewing GPT-5.6 Sol 及对应 Preview System Card, 2026-06. https://openai.com/index/previewing-gpt-5-6-sol/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










