“编者按:这篇文章介绍的 VERSES AI,从根本上挑战了主流范式,展示了一条更高效、更透明,也更接近生命本质的智能路径。
翻译本文,是希望我们能一起跳出思维的惯性,思考一个问题:除了把模型做得更大,人工智能的未来,是否还有更激动人心的可能性?
深入 VERSES AI 的 AXIOM 架构:一个运行成本比 GPT 低 5000 倍、速度快 140 倍的认知系统。
作者:DEVANSH2025年8月4日
如今,大家都在说 AI 的“规模效应”到头了,生成式 AI 碰壁了。
它能画出宇航员骑着独角兽的逼真照片,却画不好一杯倒满的红酒。
它能大谈哲学,却连一个十岁小孩玩桌游时的多步推理都搞不定。
那些揪着 AI 数不对单词字母、解不开简单谜题不放的人,确实说到了点子上——生成式 AI 的局限性很大,离真正的“智能”还差得远。
更关键的是,我们不能再无休止地砸钱买显卡了。用谷歌 CEO 桑达尔·皮查伊的话说,那些唾手可得的成果,早就没了。
那接下来该怎么办?
一条路,是像修补匠一样,一点点修复系统的缺陷。这也是我们今天看到的智能体、工具使用、小语言模型这些热门技术的由来。
这条路想把大语言模型的毛病隔离开,用其他更合适的方案去解决。这确实管用。
另一条路,则是彻底的颠覆。有一帮人,就喜欢这样搞事情。
今天我们要聊的 VERSES AI 就是这样一支团队,他们有深厚的物理学和神经科学背景。
他们提出了一个非常激进的论点,这个论点源于物理学和生物学的第一性原理:
“智能,不是被动地识别统计规律。它是一个主动的、有目标的、不断建立和测试世界因果模型的过程,核心是为了不懈地减少预测错误。
听起来很深奥,我知道。我们后面会把它拆开揉碎了讲。
现在,咱们这些门外汉先看点实在的数字。
在一场代码破解挑战中,VERSES 的模型被证明比 OpenAI 的最新模型快 140 倍,成本效益高 5260 多倍。
在和另一个顶尖模型对决时,它的可靠性也高得多,做到了 100% 成功,而对手只有 45%,同时速度快了近 300 倍,成本效益高了 800 倍。
让我们深入看看 VERSES 是怎么做到的,以及他们最新的模型 AXIOM 如何让我们离真正的智能更近一步。
核心看点(全文摘要)
痛点:深度学习模型,包括大语言模型和强化学习模型,都非常脆弱、不透明、耗费算力,并且无法真正地举一反三。它们只是在模拟智能,而不是真的在理解因果。
AXIOM 的核心思想:智能不是靠梯度下降从海量数据里炼出来的。它是在与世界的主动互动中,通过最小化预测误差来建立的。这个思想的理论基础,是来自物理学的自由能原理,并通过主动推理来实现。
架构亮点:
槽混合模型 (sMM):用高斯混合模型把图像拆分成一个个对象,每个对象都是对场景的一种概率解释。这让模型有了结构,能被理解,学习效率也高。 身份混合模型 (iMM):给每个“对象”一个身份标签(比如:这是炸弹,那是挡板)。这样模型就能举一反三,即便对象颜色变了也认得。 转移混合模型 (tMM):学习一个通用的“运动规则库”,用来预测对象的移动,比如弹跳、下落。所有对象共享这套规则,无需监督就能自己学会。 循环混合模型 (rMM):这是“大脑”,根据互动、历史和奖励,来推断因果关系,决定该用哪个运动规则。 自生长智能:
扩展:当现有模型解释不了新情况时,系统会自动“长”出新的组件来理解。 剪枝:当发现有些组件可以合并,并且合并后预测能力更强时,系统会自动简化自己,实现“一叶知秋”。 这让 AXIOM 能自我进化,按需调整自己的复杂度。 规划能力:
它会用模型预测控制在“脑中”模拟多种未来的可能性。 然后根据预期自由能(也就是奖励大小 + 能学到多少新东西)来打分。 它追求的不仅是眼前的利益,还有对未知的好奇心。 惊人性能:
在基准测试中,AXIOM 用极少的训练数据和算力,就打败了最强的深度强化学习模型。 只用一万次互动,就能玩到人类高手的水平,而模型参数极小。 战略价值:
不需要庞大的数据中心和海量数据来训练。 能在边缘设备上实时运行,特别适合需要高度自主决策的场景,比如交通协调、灾难救援。 能秒速适应环境变化,无需重新训练。 整个系统天生透明,不是黑箱。

AXIOM 不是深度学习的升级版,它是一个全新的物种。
它是一个能自己建立理解、推断因果、并根据未知重塑自己的认知架构。
这是一个全新的范式,比神经网络更接近智能的本质。这一点无论如何强调都不过分。
第二部分:自由能原理——大自然的智能法则
所以,一家小公司凭什么能把行业巨头打得落花流水?
他们靠的不是更好的计算集群,而是从一个完全不同的、源自生物学和物理学的智能蓝图出发。
要理解这个蓝图,你得先忘掉所有关于深度学习的东西。
别再想什么反向传播、梯度、海量数据了。那是旧时代的信仰。
现在,我们只信奉一个法则——自由能原理。
我们把它掰开说说。
所有自组织的系统,从细胞到大脑,甚至到经济体,能活下来靠的都是最小化“惊奇”。
这里的“惊奇”不是惊喜,而是热力学上的意外:系统预期会感知到的,和它实际感知到的,两者之间的差距。
这个差距,就是系统的“自由能”。如果这个差距太大、太久,系统就崩溃了。
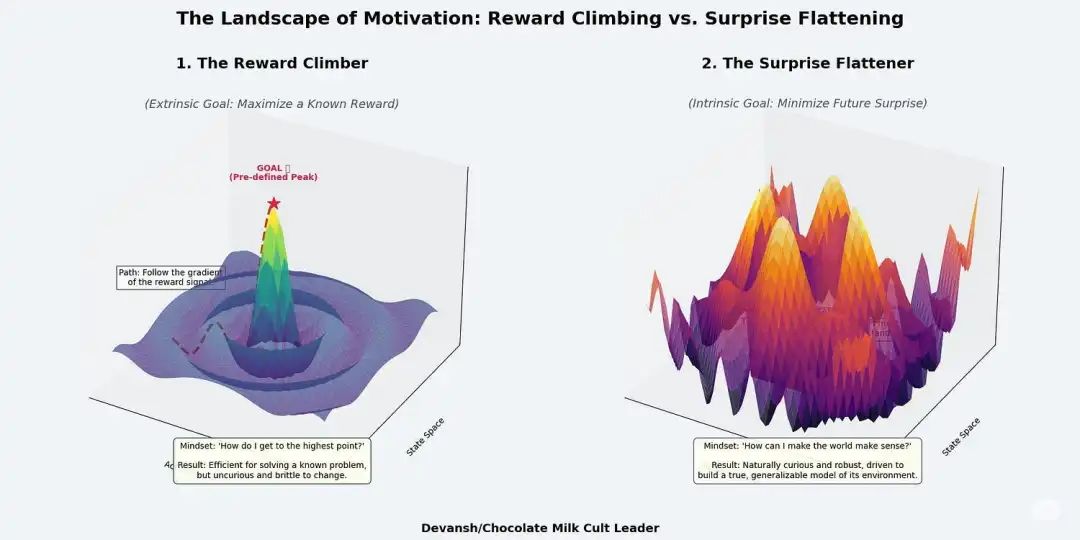
“惊奇”其实就是预测误差。
是你大脑里的世界模型,和现实世界给你的反馈之间的偏差。
你以为脚下有台阶,结果一脚踩空。你以为门没锁,结果推不开。这就是“惊奇”。
为了活下去(也为了别总出糗),你有两个办法来减少这个预测误差:
改变你的想法(感知):更新你脑子里的模型,让它更符合现实。比如你终于承认:“我支持的球队就是不行。” 你的模型变得更准确了。
改变这个世界(行动):你也可以采取行动,让现实变得跟你模型的预测一样。比如你觉得:“好无聊,去搞点事让生活刺激一点吧。”
好玩的来了。
你会发现,感知和行动,其实是同一枚硬币的两面。
它们共同构成了一个持续、高效的反馈循环,目的就是确保你那个不靠谱的内在模型,别再带着你一路犯错。

这个思想是我们的舞台。花点时间消化一下,我们再讲它在 VERSES 这里是怎么落地的。
AI 里的主动推理,到底是什么?
主动推理,就是把上面那个原理变成工程现实的武器。
你不再是训练一个网络去死记硬背“这堆像素=猫”,而是打造一个智能体,它会:
对这个世界看不见的内在状态,建立一个信念。 预测在这些状态下,它会看到、听到、感觉到什么。 把预测和现实做比较。 如果预测错了,就修正自己的信念,或者采取行动改变现实来消除这个错误。
本质上,这是一个永远不会停止学习的模型。
明白了这个前提,你就该知道为什么在万亿参数模型上搞反向传播是条死胡同了。
这种新方法还能构建出对世界更丰富的表征,连知识图谱这种复杂技术都望尘莫及。
真正的主观能动性,也来源于此。
大语言模型没有目标,没有内在动力,它就是个等指令的木偶。
而一个主动推理的智能体,它的核心里就刻着一个根本使命:最小化未来的“惊奇”。
这个内在动机,逼着它去探索、去验证假设、去高效学习。因为在自然界里,浪费能量就等于自取灭亡。

这带来了几个巨大的优势:
理解因果:它学习的是“为什么”,不只是“是什么”。它建立的是事物相互影响的因果模型,而不是一堆相关性数据。它看到球在滚,学到的是动量和障碍物,而不只是一堆像素的变化。
学习神速:一旦你懂了因果,就不需要海量样本了。就像你不用看一万把椅子,也能明白“能坐的东西”是什么。VERSES 的智能体玩游戏,只需要几千次互动就能学会,而不是几百万次。
真正的“自知之明”:它对自己的判断有多大把握,是有精确的数学定义的。当它说“我有七成把握”时,这是有意义的。就算错了,这个“错”也比神经网络那种“蜜汁自信”的错误,提供了多得多的有用信息。
当然,这一切并非唾手可得。
起步的门槛很高,整个生态也才刚刚萌芽。
但别忘了,我们现在这条路也一点都不容易,它只是建立在万亿美金砸出来的基础设施上而已。
当旧系统快到头的时候,我们再不看看它的反面,就太傻了。
主动推理不仅是不同,它更精简、更透明、更去中心化。一旦它跑通了,就会颠覆一切。
第三部分:深入 AXIOM,看 VERSES 如何实现智能
那张架构图……信息量是真大。
喝口水,我们把它拆开,一个概念一个概念地啃。
我本想引用论文原文,但论文里全是下面这种天书:
[密密麻麻的数学公式图片]
后面也全是这个画风……
所以,我们还是用大白话来讲吧。
3.A:用“槽混合模型”,搭建感知能力
智能体在思考和行动前,必须先看懂世界。
它要把一堆原始的感官数据,变成有结构、有意义的东西。
它要把世界划分成一个个独立、持续存在的实体,这样才能跟踪、预测和控制它们。
一切智能,都始于以对象为中心的感知。
槽混合模型,就是 AXIOM 解决这个根本问题的法宝。
它是系统的视觉皮层,但不是用卷积网络或 Transformer 搭的,而是用一种无监督的、为了争夺解释权的概率竞争来构建的。
没有标签,没有梯度,没有预训练。只有像素流和一个贝叶斯法则的指令:要么解释你看到的,要么被淘汰。
核心洞察:智能,源于对象
AXIOM 不再满足于处理像素。它对现实的本质,下了一个根本性的赌注:
你在屏幕上看到的,是由少数几个连贯、持久的对象在移动和互动中产生的。
它把视觉世界,看作是这些隐藏对象的混合体。
它是怎么工作的?
我们先理解两个核心数学工具。
第一个是高斯分布,也就是钟形曲线。它代表一种有把握,但不绝对的信念。
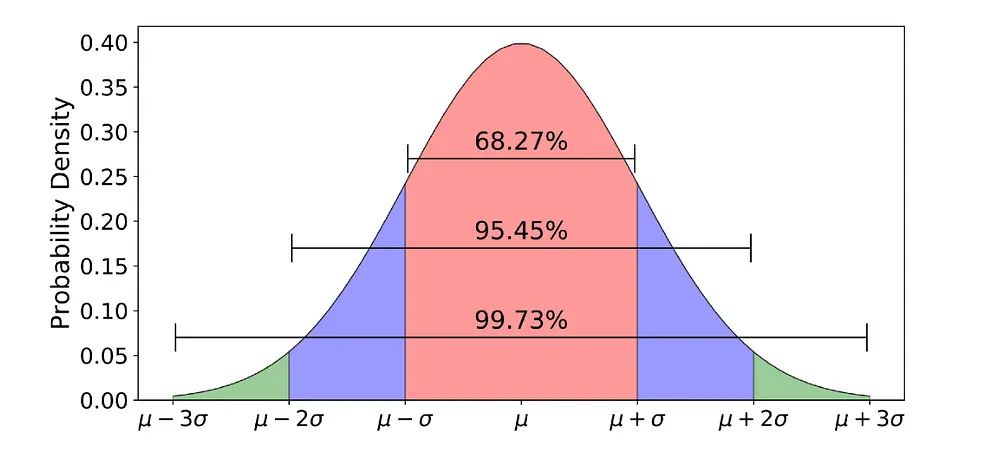
传统变量说“x = 5”,是死的。高斯分布会说:“我猜 x 很可能是 5,但 4.9 或 5.1 也有可能。但绝对不可能是 2 或 8。”
它既给出了一个最可能的值,也给出了一个不确定性的范围。
第二个是混合模型。想象一下,把好几个钟形曲线混在一起,就能表示出更复杂的形状。
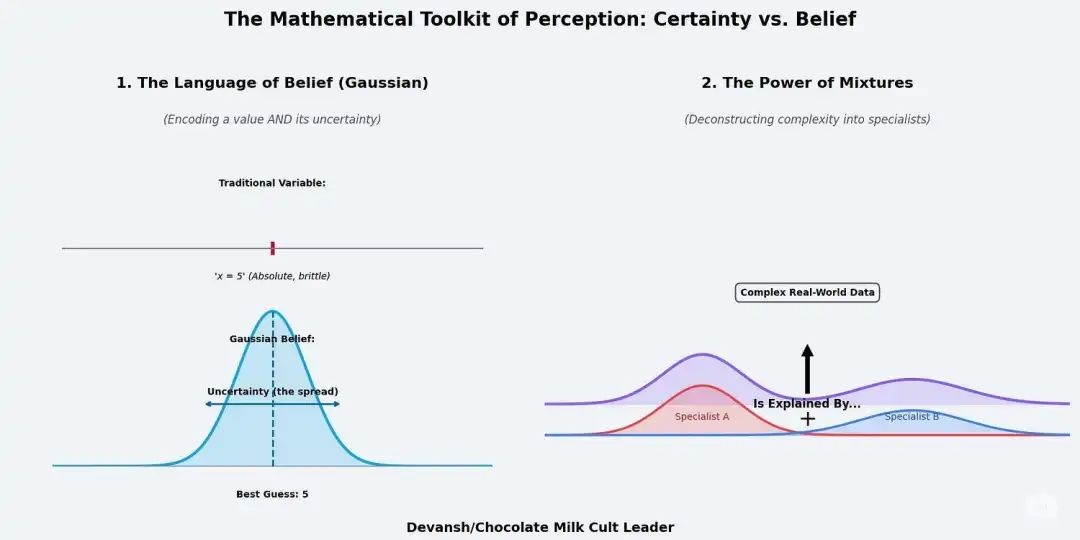
它假设,任何复杂的数据分布,都可以看作是几个简单的正态分布混合而成的。
把这两个工具合在一起,就是高斯混合模型:一个由多个高斯专家组成的团队,每个专家都负责解释数据的一部分。
实战中的 sMM:一场争夺像素的战争
AXIOM 拿到一帧图像,比如一张游戏画面。
画面里有几万个像素,每个像素都有自己的颜色和位置信息。
现在,“对象槽”的竞争开始了。
AXIOM 里有几个“对象槽”,每个槽都代表一个它认为可能存在的物体。
比如,槽 A 的信念是:“我大概率在左上角,是红棕色的,形状有点像球。”
槽 B 则有另一套完全不同的信念。
接着,生成性的战争打响了。系统把这些假设的“对象”重新投射回画面上。
它会问:“如果左上角有个红色的球(槽 A),那边还有个别的东西(槽 B)……那整个画面应该长什么样?”
然后,它把这个“脑补”的画面和真实的画面做对比。
对于每一个像素,它都会评估,哪个槽的“脑补”更接近真实。
左上角的像素,被槽 A 的“红球”假设完美解释了,于是槽 A 就对这些像素负起了主要“责任”。
最终,整个画面被柔和地、完整地分割开来。
每个像素都被赋予了不同槽的“责任权重”,原始的像素流,就这样变成了一个基于“对象”假设的、有结构的场景理解。
这个过程,带来了两个颠覆性的结果:
效率高到离谱:AXIOM 学的不是像素组合,而是几个高斯分布的参数。这让它的学习速度快得惊人,模型尺寸也小了整整 400 倍。因为它解决的问题,从根本上就更简单、更正确。
天生的可塑性:如果画面里突然出现一个新东西怎么办?系统内置了一个机制,当它发现所有现存的“专家”都解释不了这个新东西时,它有权当场“创造”一个新槽位,说:“我猜,这里出现了第 N+1 个物体,现在我来给它建模。”
sMM 是 AXIOM 世界观的基石。它提供了一个干净、结构化、以对象为中心的世界,让真正的推理得以开始。
3.2:构建时间、记忆和因果
sMM 提供了“名词”——一个对象清晰的世界。但这还不够,世界是动态的。
智能体需要理解“动词”,需要理解“语法”,需要对过程进行建模。
不然,它怎么知道这个红圈是水果还是炸弹?这个方块是会弹还是会滚?
这些问题,光看颜色和位置是答不出来的,需要“类型”层面的理解——把外观和预期行为联系起来。
为什么“身份”这么重要?
假如你学会了红球会弹,绿块会炸。现在又来一个红球,难道你要从零开始学它的运动规律吗?
那之前学的知识不就白费了?
更糟的是,如果红球因为光线变化,中途变成了蓝色,难道就要当成一个全新的东西吗?
这就是传统模型的通病:对表面特征过度拟合,稍微有点变化就歇菜。
AXIOM 不会。它用 iMM (身份混合模型)来创造身份代码。
这是一个紧凑的标签,把行为相似的对象归为一类。
这让智能体可以跨实例复用学到的动态模型,还能在对象外观变化时,把它重新映射回正确的类别。
这一切都不是硬编码的,而是从与世界的互动中,自己学出来的概率性记忆。
理解马尔可夫过程
为了实现这种智能,Axiom 的运作基于一个简单但强大的前提:马尔可夫过程。
简单说,就是一个系统的未来只取决于现在,跟过去怎么到这儿的没关系。
这个“无记忆性”大大简化了问题。想象一下玩马里奥,只要当前关卡的所有状态(金币、道具、位置等)都一样,你之前是怎么玩到这儿的,对未来怎么玩毫无影响。
在这个基础上,我们加上行动、奖励和长期回报,就构成了马尔可夫决策过程,这也是整个强化学习的数学基石。
AXIOM 的后续模块,就是一个旨在学习“世界如何从当前状态转移到下一状态”的工程堆栈。
理解了这些,后面的模块就清晰了。
1. 身份与记忆 (iMM)
解决的问题:它要搞清楚,“现在这个红球”是不是“两秒前那个红球”,即便它中途被挡住过。这就是对象持久性和身份识别的问题。 工作方式:它像 AXIOM 的记忆中枢,分析对象的颜色、形状等特征,给它分配一个离散的“身份代码”。这样,它学的就不是“红球1号”和“红球2号”的模型,而是“红球”这一类型的通用模型。
2. 动态与预测 (tMM)
解决的问题:一个对象被识别出来后,它会怎么动?这个世界的基本“物理法则”是什么? 工作方式:它是 AXIOM 自己搭建的“物理引擎”。它会学习一个共享的运动原型库,比如“正在下落”、“正在弹跳”、“保持静止”等基本模式。这个库是所有对象共享的,所以它不用为每个新东西都重新学习一遍“下落”是什么意思。
3. 逻辑与上下文 (rMM)
解决的问题:这是“总指挥”,它看着全局,决定此时此刻应该用哪个运动模式。球在空中是“下落”,一碰到地板就得切换成“弹跳”。是什么决定了这个切换?是上下文。 工作方式:它是逻辑引擎,根据对象自身状态、和谁互动、玩家刚做了什么、刚得到了什么奖励等所有信息,来做出最关键的状态转换决策。它学习的是游戏深层的、因果的语法。
正是因为这套明确的、基于因果的推理,VERSES 的模型才能在逻辑挑战中做到 100% 准确。
它构建了一个真实的游戏规则逻辑模型,并能完美执行,这是更“随性”的大语言模型做不到的。
这个从 iMM 到 tMM 再到 rMM 的层级结构,就像一条认知能力的流水线。
它把 sMM 创造的对象世界,置于时间的逻辑之下,从零开始,构建起一个能预测、能理解因果的环境模型。
3.3:结构化智能——生长、压缩与控制
AXIOM 不只是运行一个固定的模型,它在生长一个大脑,它在重塑自己。
它自己决定要学什么新知识,丢掉什么旧包袱。
然后,它用这个不断进化的模型去模拟未来,并选择能最大程度消除“意外”的行动。
这太疯狂了。
神经网络靠堆叠层数来变大,Transformer 靠增加万亿参数。
而 AXIOM 靠积累结构来成长——只在需要时增加新组件,在冗余时进行压缩,一切都为了一个目标:精确地建模世界,以便在其中行动。
这个过程分为三步:扩展、剪枝和规划。
1. 扩展:当世界变得复杂时
系统里的每一个混合模型,都具备自我扩展的能力。
当它遇到一个用现有“知识库”无法解释的新情况时,它就会触发一个机制,问自己:
“我需要发明一个新组件来理解这个新东西吗?”
无论是新的视觉模式、新的物体类型,还是新的运动轨迹,系统都有权当场创造一个新的组件来对其建模。
这种生长,不是盲目的,而是在预测误差持续过高时,也就是当系统被持续地“惊到”时,才会发生。
这正是对抗模型过拟合的解药。
2. 剪枝:当世界可以被简化时
生长带来力量,但无节制的生长只会导致混乱。
为了保持高效,AXIOM 会定期“修剪”自己的模型,这个过程叫“贝叶斯模型约减”。
目标很简单:只有当合并两个相似的组件能让模型对未来的解释力变得更强时,才进行合并。
比如,它可能会尝试把“撞到红球会受伤”和“撞到蓝块会受伤”合并成一条更通用的规则:“撞到东西会受到惩罚”。
如果这条新规则能让它玩得更好,合并就会被接受。
这让 AXIOM 能够从极少的事件中举一反三,防止模型变得臃肿,并始终保持精简和高效。
3. 规划:通过模拟未来,做出选择
现在,到了收获的季节。
传统的强化学习智能体,要么在瞎碰运气,要么依赖预先算好的策略。
AXIOM 则是通过模拟未来来规划行动,它要寻找的,是能最好地平衡奖励和理解的路径。
它会同时“脑补”出好几种行动方案。
然后对每一种方案进行打分,评分标准有两条:
能得到多少奖励? 能学到多少新东西?
它要选的,是那个既能减少“意外”,又能减少“无知”的最佳策略。
因为模型本身是高度结构化的,这种规划速度极快,且完全可以在本地完成,不需要庞大的算力集群。
这种模式,与深度强化学习有着本质的不同。
如果世界变了,它会重塑自己。 如果世界有规律,它会压缩和泛化。 如果世界是未知的,它会主动测试和学习。
这一切都让它成为了边缘计算的绝配。
结论:迈向会思考的系统
过去十年,人工智能被一个信条主导:模型越大,数据越多,智能就越强。
这在某种程度上确实奏效了——直到它撞上了天花板。
我们得到了能流利模仿人类语言和视觉的模拟器,但我们没有得到真正的自主性,没有得到理解力,没有得到能实时适应、因果推理的系统。
AXIOM 做到了这三点。
这背后不是什么聪明的小技巧或新的算法,而是因为它建立在一个完全不同的基石之上。
它不靠死记硬背,而是去主动建模这个世界。
它不靠人工调整,而是会自我重构。
它不被动等待意外,它在每一帧都在预测、测试和更新。
我一直在想,智能或许不取决于模型的规模,而取决于其数学结构。也许,上帝是个分形家。
说句题外话,我们对 AI 投入了这么多,却对自己到底什么是智能,并没有增加多少理解,这本身就挺讽刺的。
像 VERSES 这样另辟蹊径的探索,或许能改变这一点。
通过重新思考“智能系统”的含义,我们或许也能更多地了解我们自己。
尤其是当这个新范式,既有生物学依据,又完全可以被理解和审计时。
去了解一下 VERSES 吧,也欢迎告诉我你对他们方法的看法。
感谢阅读,祝你今天过得愉快。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!










