如您有工作需要分享,欢迎联系:aigc_to_future
作者:Zuhao Yang等
解读:AI生成未来

文章链接:https://arxiv.org/pdf/2508.01698
项目链接:https://mwxely.github.io/projects/yang2025vtg/index





亮点直击
提出了一个统一的多功能过渡生成任务,旨在为物体变形、概念混合、运动预测和场景转换生成平滑且合理的过渡。 设计了VTG,一种新颖且多功能的框架,能够有效生成语义相关、高保真且时间连贯的视频过渡。 引入了TransitBench,一个精心策划的数据集,用于对概念混合和场景转换进行基准测试。通过TransitBench和其他公开基准, 在定性和定量上均证明,VTG在这四种过渡生成任务中始终优于现有技术。
总结速览
解决的问题
现有过渡视频生成的局限性: 现有方法(如插值或光流估计)难以生成长序列、平滑且语义合理的过渡视频。 缺乏统一的框架支持多种过渡任务(如物体变形、概念混合、运动预测、场景转换)。 生成视频的保真度(fidelity) 和运动平滑性不足,尤其在内容突变或跨域场景中表现不佳。 数据与评估瓶颈:现有研究依赖私有数据集,缺乏公开基准(如 TransitBench)推动领域发展。
提出的方案
插值初始化(Interpolation-based Initialization): 对输入帧的隐空间噪声和文本嵌入进行球面插值,缓解内容突变问题,保留物体身份一致性。 结合双LoRA-U-Net,在去噪过程中捕捉物体级语义。 双向运动微调(Dual-directional Motion Fine-tuning): 通过轻量级微调预训练图像到视频扩散模型,融合前向与反向预测噪声,提升运动平滑性。 表示对齐正则化(Representation Alignment Regularization): 引入自监督视觉编码器,显式对齐生成帧的特征表示,增强保真度和语义连贯性。 统一任务支持: 通过最小化任务适配,支持四类过渡任务(物体变形、概念混合、运动预测、场景转换)。
应用的技术
扩散模型基础:基于图像到视频扩散模型(如U-Net架构),结合LoRA微调。 球面线性插值(Spherical Interpolation):用于隐空间噪声和文本嵌入的平滑过渡。 双向噪声预测:通过前向-反向噪声融合优化时间一致性。 自监督学习:利用视觉编码器(如CLIP)进行特征对齐正则化。
达到的效果
生成质量:生成视频在平滑性(时间连贯)、保真度(与输入帧一致)和语义对齐(符合文本提示)上显著优于现有方法。 任务通用性:单一框架支持四类过渡任务,在 TransitBench基准上表现一致优异。
数据与评估贡献:开源 TransitBench(含200对帧-文本数据),促进未来研究。
方法
基于插值的初始化
在扩散模型中,初始高斯噪声决定了早期去噪步骤中出现的粗粒度结构,而高频细节则在后期细化。由于现有的图像到视频扩散模型在推理时随机初始化隐变量,每一帧中间帧都遵循不同的随机轨迹:颜色、微观纹理甚至物体姿态在帧间会轻微偏移,从而产生感知上的“闪烁”。
为了抑制这种偏移,我们通过在端点噪声之间进行插值来关联帧间隐变量,而非独立重采样。先前工作[6]表明,线性插值通常会产生在单位高斯分布下极不可能出现的中间隐变量范数,而球面线性插值(SLERP)能保持欧几里得范数并使样本保持在分布内。因此,我们利用两个输入帧和的隐变量噪声进行SLERP,公式如下:

其中,表示隐变量插值的参数。如下图2所示,将与和沿帧维度拼接,并将其作为DDIM采样的初始隐变量噪声注入。需要注意的是,我们仅在早期去噪步骤中注入插值后的隐变量噪声,以尽可能保留图像到视频主干网络的外观和运动先验。通过这种精心设计的隐变量注入策略,本文的方法解决了随机和突变的过渡帧问题。

与GANs不同(其隐空间具有结构化和语义意义),扩散模型在非结构化的噪声空间中运行,该空间并未显式编码高级语义。这种结构缺失可能导致在语义不同的输入之间插值时产生伪影。为了抑制此类过渡伪影,我们首先给定两个输入帧和训练两个LoRA模块和,优化以下目标:

其中是第帧的编码隐变量向量,是与过渡描述相关联的文本嵌入。接着,我们对两个LoRA模块进行线性插值以融合两个输入帧的语义:

其中表示LoRA插值过程中的参数。
通常,视频扩散模型仅使用一个描述文本作为条件输入。这会阻碍两个概念不同物体之间的过渡生成,导致内容突变而无法生成具有混合含义的中间帧。然而,对于图像到视频扩散模型,整个帧序列的文本嵌入通过交叉注意力层集成在去噪U-Net中,而没有明确定义每帧的文本嵌入。相关的静态图像方法通过线性混合两个文本嵌入来实现两个静态端点之间的变形,而本文的方法则在提示序列上进行帧感知的SLERP,如下所示:

其中作为帧感知系数控制过渡序列;和分别表示首帧和末帧的文本嵌入。
双向运动预测
在实验中,观察到输入帧顺序反转时存在显著的质量差异。这种差异主要源于两个因素:
由于条件图像泄漏,模型更倾向于接近初始输入帧; 现有图像到视频扩散模型仅针对前向运动预测进行预训练,而真实世界运动本质上是非对称的,导致反向运动预测存在模糊性。
本文同时预测前向和反向运动以缓解模糊性问题。将时序自注意力图水平和垂直旋转180度,如图3所示实现注意力关系的反转。给定输入帧和,我们将原始前向视频轨迹反转为,并通过沿时间维度翻转获得反向噪声隐变量,随后将其输入3D U-Net进行反向运动预测。
训练时采用轻量级微调策略,仅更新时序注意力层中值矩阵和输出矩阵参数(即)。目标函数通过计算预测噪声与真实反向噪声之间的L2范数来构建:

将预测的反向噪声再次反转后与前向噪声融合。本文采用线性插值来确保前向-反向一致性:

其中表示权重因子。
表示对齐正则化
尽管前述技术有效缓解了内容突变和运动反转模糊性问题,但本文的方法仍可能生成模糊且低保真的过渡视频,特别是当输入帧包含细粒度纹理(如自行车辐条或织物编织)时。近期工作[53]表明,与DINOv2等自监督表示相比,扩散隐变量本质上缺乏高频语义。这种不匹配会随着视频帧累积并表现为模糊。
本文提出将DINOv2特征蒸馏回视频扩散的去噪轨迹。如下图3所示,视频隐变量首先沿时间维度被分块为个包含个标记的序列。

对于帧视频,第帧隐变量的形状为。给定预定义分块大小,序列长度应为:。接着,我们通过多层感知机(MLP)投影视频扩散的每帧潜表示,以对齐DINOv2表示,其中表示给定干净视频帧时编码器的输出;和分别表示DINOv2编码器的分块数和嵌入维度。设为中间扩散潜特征的投影表示,表示MLP的可训练参数。正则化项通过聚合所有视频帧的分块相似度来计算:

在推理阶段,外部编码器与MLP投影器将被丢弃。
实验
实验设置
训练细节:本文使用150个高质量内部视频作为训练数据,涵盖各类运动(如跑步、飞机滑行)和外观变化(如从青年到老年的过渡)。反向U-Net的可学习参数初始化为零,其余权重从DynamiCrafter的预训练检查点初始化。采用AdamW优化器(学习率),在4块NVIDIA A100-80GB GPU上训练约20K次迭代(批量大小为2)。
推理细节:实验采用Stable Diffusion v2.1-base作为插值主干。训练LoRA时,设置秩为16,使用AdamW优化器(学习率)训练200步(单块A100-80GB GPU耗时约85秒)。在反转和采样阶段,使用DDIM采样器,总时间步数设为默认值50。所有模型均采用文本分类器无关引导,负面提示词统一为“扭曲、不连续、丑陋、模糊、低分辨率、静止、静态、畸形、肢体断裂、面部丑陋、手臂残缺”。
对比方法:与以下方法比较:DiffMorpher、TVG、SEINE、DynamiCrafter、Generative Inbetweening、文本嵌入插值(TEI)、去噪插值(DI)和注意力插值(AID)。
评估基准:使用多个公开数据集及自建TransitBench全面评估生成质量。具体包括:
物体变形:MorphBench 运动预测:TC-Bench 概念混合与场景过渡:因缺乏专门基准,此前工作[16]采用CIFAR-10和LAION-Aesthetics,但前者仅含10类概念,后者全为合成图像。本文构建首个专用基准TransitBench,包含200对多样化图片(每对构成一个过渡样本的首尾帧),均分两类:
概念混合案例 场景过渡案例
数据均来自网络资源,旨在推动通用过渡生成研究。
定性分析
为证明本方法的优越性,本文提供了VTG与五种前沿基线的可视化对比。将所提方法与DiffMorpher、Generative Inbetweening、TVG、SEINE、DynamiCrafter在四种过渡任务中进行统一比较。下图4展示了不同方法的生成结果。

在物体形变任务中,对比方法存在生成质量低(如DiffMorpher、DynamiCrafter)、过饱和效应(如TVG)和语义不准确(如Generative Inbetweening、SEINE)等问题。相比之下,VTG实现了自然的过渡,并较好地保留了首尾帧内容。在运动预测任务中,Generative Inbetweening和SEINE因模糊的中间帧生成效果较差;TVG因生成人物正面图像(实际应为侧脸)导致过渡不自然;DiffMorpher的过渡质量较低,其生成视频类似背景与前景物体无关的间歇图像序列,这主要源于其图像扩散主干缺乏时序建模。VTG与DynamiCrafter结果相当甚至更优,验证了其能有效保持扩散模型的外观与运动先验。
在概念混合任务中,多数视频扩散基线出现内容突变,而其他基线存在模糊(如DiffMorpher)和歧义(如TVG)的中间帧。VTG则实现了狮子与卡车的平滑过渡,且中间结果合理(如狮子颜色/尺寸的卡车)。在相关场景图像间的场景过渡任务中,现有方法存在内容突变或相似度低(如TVG)的问题,而VTG产生了视觉效果自然的场景级过渡。
定量分析
评估指标。通用过渡生成的目标是在两个源帧与(附带描述文本)间生成个中间视频帧。高质量过渡视频需同时满足四个标准:输入端点的语义保真度、视觉质量、时序一致性和感知平滑度。为公平对比,我们采用与原始论文一致的实验设置进行量化评估,具体指标如下:
(1) FID ()与PPL ()沿用DiffMorpher。FID在Inception特征空间比较首尾帧与生成过渡帧;PPL计算插值路径上的平均LPIPS波动,值越低表明感知跳跃越少。
(2) TCR ()与TC-Score ()来自免训练的TVG框架。TCR是CLIP嵌入与任一端点相似度在预设阈值内的帧占比;TC-Score通过平均余弦相似度补充衡量帧级一致性。
(3) 平滑度 ()改编自AID。对每对相邻帧计算LPIPS及这些距离的基尼系数,反映逐步变化的均匀性。报告其倒数使高分代表更平滑过渡。
定量结果
如下表1和表2所示,VTG在原始实验设置下均优于现有方法,证明了其生成高质量、时序一致且语义连贯的视频过渡的能力。值得注意的是,仅在Metamorphosis子集上VTG的PPL(22.80)排名第二。尽管如此,VTG仍展现出卓越的综合性能,取得了最优的FID和可比的PPL。


根据AID的定义,良好的概念混合序列应呈现渐进且平滑的过渡。
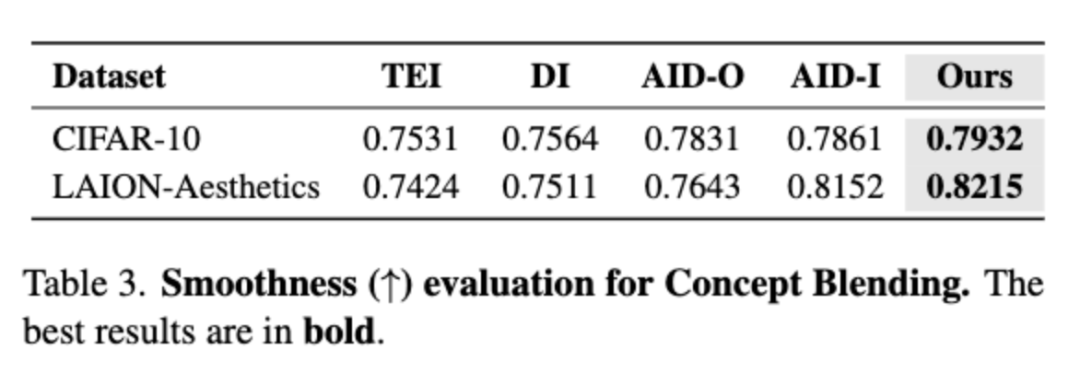
用户调研
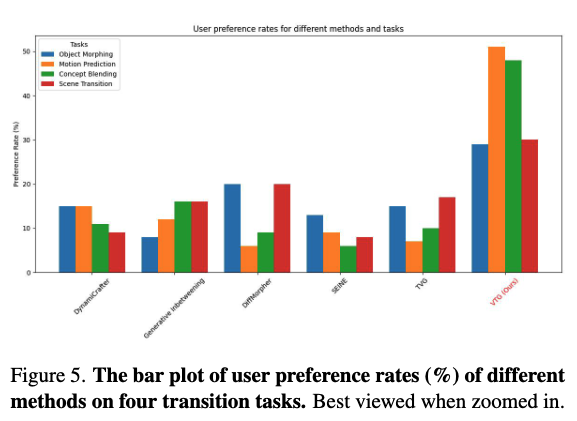
为进行主观评估,进一步开展用户调研。要求Amazon Mechanical Turk(AMT)工作人员从五组候选视频中选择最佳生成的过渡视频。给定输入帧及对应过渡文本,AMT工作人员基于三个问题评估视频:1)哪个视频语义最连贯?2)哪个视频时序最一致?3)哪个视频保真度最高?为确保公平,包含静态或明显错误的视频以排除随机选择。每个测试样本由10位不同工作人员评估,过滤随机点击后共收集每任务150份有效反馈。结果如下图5所示,VTG因生成质量优越而获得最高偏好率。
结论
本文提出了通用过渡生成问题,涵盖物体形变、运动预测、概念混合和场景过渡四项代表性任务。基于预训练图像到视频扩散模型,设计了统一框架VTG,可单模型处理四类任务。定性与定量实验表明,给定文本提示对和输入帧,VTG能生成语义相关、时序连贯且视觉逼真的过渡视频帧。凭借这些优势,VTG可高效应用于现实内容创作场景,为媒体生产提供高质量的过渡生成工具。
参考文献
[1] Versatile Transition Generation with Image-to-Video Diffusion
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!











