点击下方卡片,关注“具身智能之心”公众号
作者丨Lingfeng Zhang等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

研究背景与动机
Embodied navigation(具身导航)是智能体在物理环境中移动和交互的基础能力,但现有研究多聚焦于预定义物体导航或指令跟随,与现实中人类复杂、开放场景的需求存在显著差距。例如,现有视觉-语言导航(VLN)依赖过于具体的分步指令(如“左转、出门、直行”),而物体导航(ObjectNav)仅需找到预定义类别的任意物体,均无法处理“我想喝杯咖啡”这类需要高级推理和空间感知的指令——这类指令不仅需要推断目标物体(咖啡机),还需判断其可能位置(茶水间、厨房),并理解空间关系。
为填补这一空白,本文提出了长视野导航任务,要求智能体理解高级人类指令,在真实环境中完成空间感知的物体导航,并据此设计了分层框架NavA³。
核心贡献
提出了一项具有挑战性的长视野导航任务,要求智能体在复杂室内环境中理解高级人类指令,定位具有复杂空间关系的开放词汇物体。 设计了NavA³分层框架,通过全局策略和局部策略的结合,实现对多样高级指令的理解、跨区域导航及任意物体的定位。 构建了包含100万样本的空间感知物体affordance数据集,用于训练NaviAfford模型,使其能理解复杂空间关系并实现精确物体指向。 大量实验表明,该方法在导航性能上达到SOTA,为现实场景中通用具身导航系统的发展奠定了基础。
方法框架:NavA³的分层设计
NavA³采用“全局到局部”的分层策略,融合语义推理与精确空间定位,以应对长视野导航任务(figure 2)。
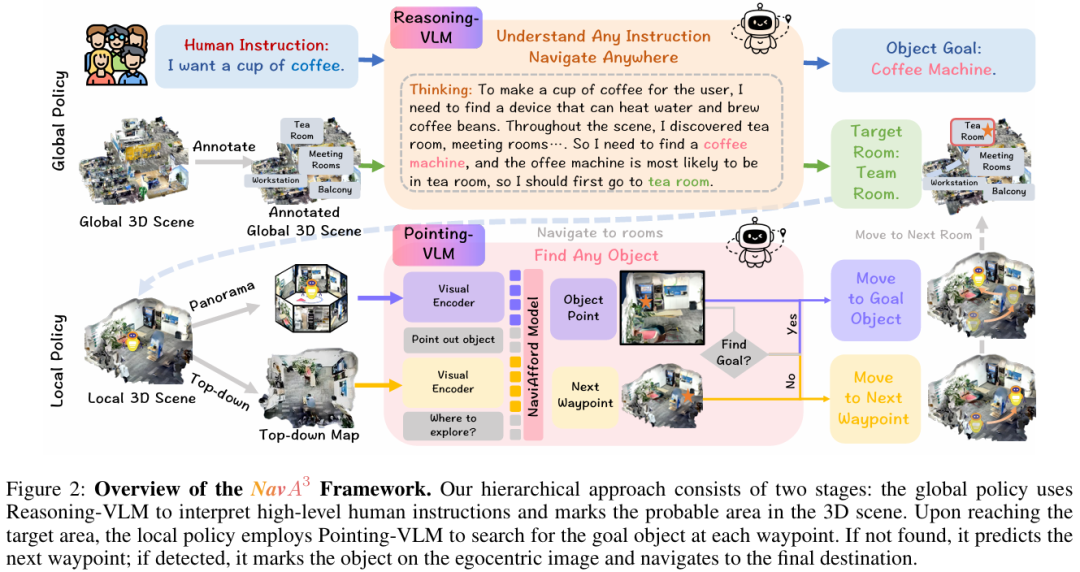
全局策略:解析指令与确定区域
全局策略依赖Reasoning-VLM(推理型视觉-语言模型),核心是将高级人类指令转化为可执行的导航目标。
指令解析与目标推断:给定指令(如“我想喝杯咖啡”),Reasoning-VLM通过语义分解推断目标物体(咖啡机),并结合带标注的全局3D场景,分析空间语义关系以确定目标区域(如茶水间)。例如,对于“挂衣服”的指令,会推断目标为衣架,且最可能在阳台(figure 1)。

场景表示与推理引导:全局3D场景通过RGB图像经2D到3D重建生成,包含房间和区域级语义标注(如“茶水间”“会议室”),表示为:
其中为几何区域,为对应语义标注。Reasoning-VLM通过结构化提示进行推理:“需完成指令I,基于全局场景视图和可选区域,思考需找到的物体及位置,并展示推理过程”(figure 3)。

区域导航:确定目标区域后,在其局部边界内随机采样路径点,由Pointing-VLM引导智能体前往,缩小搜索范围以提升效率。
局部策略:精确物体定位与导航
局部策略聚焦于目标区域内的探索和精确物体定位,核心是NaviAfford模型(Pointing-VLM)。
NaviAfford模型:基于100万样本的空间感知数据集训练,能处理物体affordance和空间affordance两类标注:
模型架构为视觉-语言框架,输入文本查询Q和RGB图像V,输出目标点坐标:
物体affordance:计算方向关系(上下、左右、前后),如“沙发前的电视”; 空间affordance:识别满足约束的自由空间,如“桌子上的空位”。
其中处理文本,编码视觉输入,映射视觉特征至LLM嵌入空间,生成坐标文本(figure 4)。

导航过程:智能体在每个路径点捕获全景RGB视图,NaviAfford模型检测目标物体: 若检测到,输出多个点坐标,取中心点作为定位结果; 坐标转换:通过相机内参将像素坐标转为相机坐标:
再通过旋转和平移转为机器人坐标:
若未检测到,Reasoning-VLM分析局部3D场景和历史数据,决定继续探索当前区域(由NaviAfford确定下一路径点)或切换至新区域。
实验验证
实验在5个场景(会议室A、会议室B、茶水间、工作站、阳台)的50个任务上展开,通过导航误差(NE)和成功率(SR)评估性能,并与SOTA方法对比。
与现有方法的对比
NavA³在所有场景中显著优于现有方法(table 1):

平均成功率达66.4%,较最佳基线MapNav(25.2%)提升41.2个百分点; 各场景成功率提升明显:会议室A(72.0% vs 26.0%)、工作站(76.0% vs 28.0%)等; 导航误差大幅降低:会议室A(1.23m vs 7.21m)、茶水间(1.89m vs 9.12m)等。
通用VLMs(如GPT-4o、Claude-3.5-Sonnet)在该任务中成功率接近零,凸显NavA³分层策略的优势。
消融实验
标注的影响:完整标注使茶水间和工作站的成功率分别提升28.0%和36.0%(table 2),表明语义标注能增强Reasoning-VLM对空间关系的理解。

Reasoning-VLM的影响:GPT-4o作为Reasoning-VLM时平均成功率达68.0%,显著高于开源模型(如Qwen2.5-VL-7B的40.0%)(table 3),说明强推理能力对复杂空间任务的重要性。

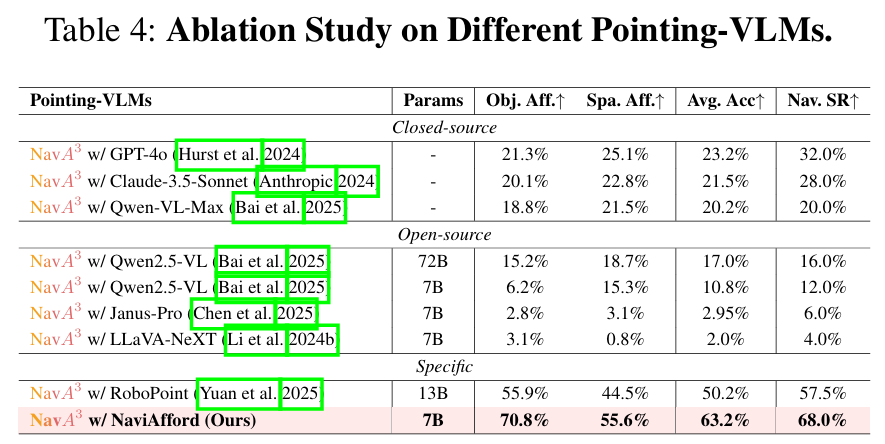
Pointing-VLM的影响:NaviAfford的平均affordance准确率达63.2%,较RoboPoint提升13.0%,对应导航成功率提升10.5%(table 4),验证了空间affordance训练的有效性。
定性分析
figure 5展示了NavA³的实际表现:

能准确理解“笔记本左侧的沙发”“衣柜内的空位”等空间关系; 长视野导航中,从“想喝咖啡”到找到咖啡机的推理过程清晰; 在轮式机器人和四足机器人上均能稳定运行,体现跨载体适应性。
参考
[1]NavA^3: Understanding Any Instruction, Navigating Anywhere, Finding Anything