
你有没有想过这样一个问题:为什么ChatGPT、DeepSeek、Claude..能够如此聪明,而你公司花了几百万训练的AI模型,却连基本的业务问题都回答不好?
前几天,我和一位做AI的朋友聊天。他苦笑着告诉我:"我们团队用了最先进的Transformer架构,调了几个月的参数,结果模型在医疗场景下的表现还不如一个刚毕业的实习生。"
这个故事听起来很熟悉吗?

真正的壁垒不是算法,是数据
很多人以为AI大模型的核心竞争力在于算法架构。
错了。今天,Transformer架构已经开源,各种优化技巧也都公开了。你想要的GPU算力,云服务商都能提供。那为什么OpenAI、Google这些公司还能保持领先?答案很简单:数据。

我见过太多公司,花大价钱买最好的硬件,请最牛的算法工程师,结果训练出来的模型效果平平。
问题出在哪里?数据质量太差。就像做菜一样,你用最好的厨师、最贵的锅具,但食材是烂的,能做出好菜吗?
现在网上流传一个说法:"互联网上的数据不够用了。"这话对,也不对。
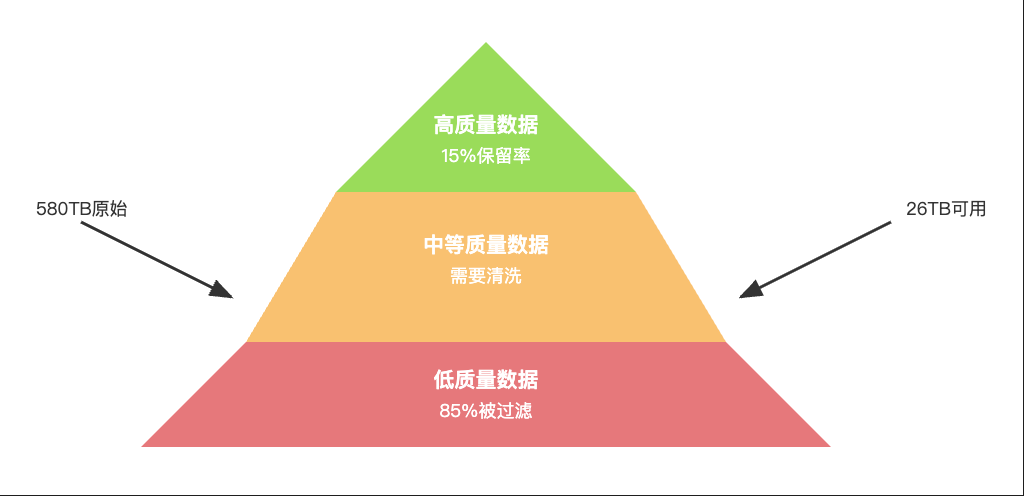
对的是,Common Crawl这样的公开网页数据确实被各大公司反复使用。580TB的原始数据,经过清洗后只剩下26TB可用内容。这些数据就像公共食堂的菜,谁都能吃,但营养有限。不对的是,真正有价值的数据还有很多,只是被锁在了企业内部。
医院的病历数据、银行的交易记录、制造业的工艺参数...这些才是真正的"营养品"。
但这些数据有个特点:不对外开放。
我认识一家做医疗AI的公司,他们花了两年时间,才说服几家三甲医院提供脱敏后的病历数据。有了这些专业数据,他们的模型在诊断准确率上直接提升了30%。这就是垂直领域数据的威力。
数据质量比数量更重要
很多人有个误区:数据越多越好。
我见过一个团队,收集了几十TB的网络文本,兴冲冲地开始训练。结果模型学会了一堆网络谣言和错误信息。数据就像员工,宁缺毋滥。一个优秀员工顶十个混子。
Google的C4数据集,从580TB的原始数据中只保留了15%。剩下的85%都是什么?重复内容、垃圾信息、格式错误的文本。
清洗数据是个苦活累活,但必须做。就像淘金一样,你得把沙子筛掉,才能找到真金。我见过一个项目,工程师发现训练数据中某个网页被重复了100次。结果模型对这个网页的内容"记忆"特别深刻,但对其他内容却一知半解。这就是数据污染的后果。
最近两年,用AI生成训练数据成了新趋势。
听起来很聪明:让GPT-4生成问答对,然后用这些数据训练新模型。这个方法确实有效,但也有风险。就像近亲繁殖一样,AI用AI生成的数据训练,容易放大原有的错误和偏见。
我见过一个案例,团队用GPT生成了大量训练数据,结果新模型继承了GPT的所有"坏习惯",还变本加厉。
合成数据可以用,但要控制比例。一般建议不超过总数据的20%。就像做菜加味精,少量提鲜,过量就毁了。
数据正在成为新的"石油"

做中文大模型更难。英文互联网内容相对规范,中文网络就是个"大杂烩"。简体繁体混杂,方言网语满天飞,还有各种错别字和语法错误。光是处理中文语料就花了6个月。
他们要处理的问题包括:简繁转换、网络用语规范化、方言识别...每一个都是技术活。更要命的是,中文的高质量专业内容相对稀缺。英文有PubMed、ArXiv这样的学术资源,中文的同类资源就少得多。
这也解释了为什么中文大模型的发展相对滞后。不是技术不行,是"食材"不够好。
有人说,数据是新时代的石油。
我觉得这个比喻很贴切。石油需要勘探、开采、提炼,数据也需要收集、清洗、标注。
石油有不同品质,数据也有高低之分。掌握了优质数据源的公司,就像掌握了油田的石油公司。他们可以源源不断地"开采"价值,而其他公司只能买"成品油"。
这就是为什么Google、Meta这些公司如此重视数据收集。他们不只是在做产品,更是在建设数据"油田"!
结语
未来的AI竞争,表面上是算法和算力的竞争,本质上是数据的竞争。谁掌握了更多高质量的专业数据,谁就能在垂直领域建立不可逾越的壁垒。
对于想要在AI时代立足的企业来说,与其盲目追求最新的算法架构,不如先问问自己:我有什么独特的数据资产?如何把这些数据转化为AI能力?
毕竟,再好的厨师,也需要好食材才能做出好菜。
如有内容涉及违规侵权,请联系圈主处理,感谢 🙏🙏


🔗 扫描下方二维码  备注【DA】加入【大数据AI智能圈】学习交流👇
备注【DA】加入【大数据AI智能圈】学习交流👇

往期推荐

点击下方蓝字关注智能圈










