8月15日上午,由DISCOVER实验室主办的第48期AIR青年科学家论坛如期举行。本活动有幸邀请到密歇根大学新入职的助理教授高俊博士,为AIR的老师和同学们做了题为3D Grounding From and For Vision Foundation Models的精彩报告,研究如何使用视觉基础模型来做 3D grounding,并利用 3D grounding 反过来进一步增强视觉基础模型的能力。

讲者介绍

高俊,将于 2025 年秋季加入密歇根大学电子工程与计算机科学系(EECS)任助理教授。他于多伦多大学获得博士学位,本科毕业于北京大学,曾在 NVIDIA 担任高级研究科学家。他的研究方向包括三维计算机视觉、计算机图形学与生成模型等领域,致力于构建可控的生成式人工智能模型,以创造真实、丰富且可交互的虚拟环境。他的工作曾获SIGRAPH Aisa最佳论文奖,曾担任NeurIPS、3DV等会议的领域主席。
报告内容
视觉基础模型的兴起改变了 2D 视觉理解与生成的发展,也引出了一个核心问题:在视觉大模型时代,我们是否仍然需要 3D 表示?以及如何利用视觉模型提升 3D?高俊博士认为,3D 表征在一致性、可控性与交互性方面具有不可替代的优势,而视觉大模型则为构建 3D 世界提供了强大的数据与先验。二者的融合可以兼顾结构性与生成能力。在本次报告中,他基于2D 与 3D 协同结合的研究框架,介绍了团队近期在可控视频生成与 3D 理解等方向上的探索与成果。
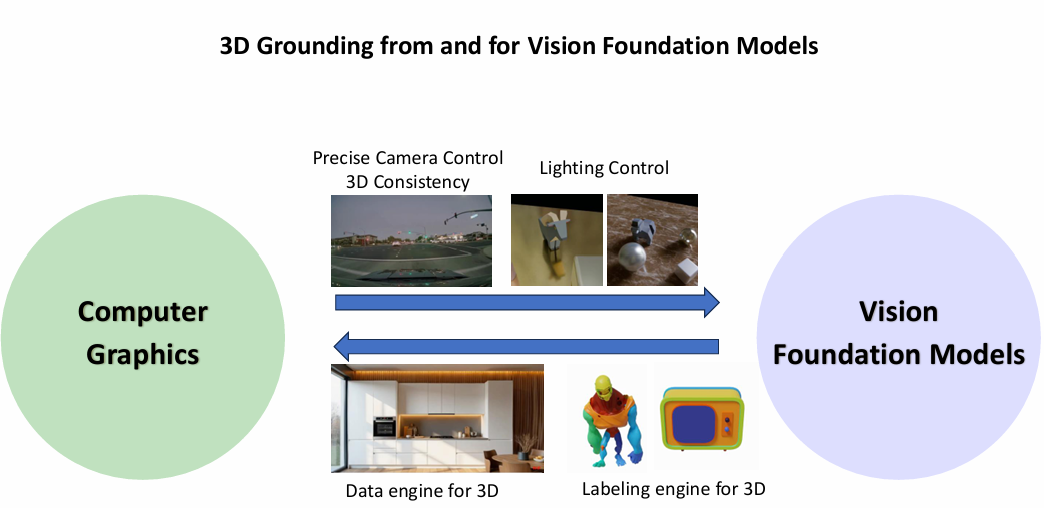
利用3D信息增强视觉基础模型
高俊博士首先从利用 3D信息提升视觉基础模型能力的视角出发,介绍了如何通过 3D 表征为视觉生成模型提供更加精确的相机控制与三维一致性。当前主流的视频扩散模型在大幅度改变相机视角时往往表现不佳,其根本原因在于缺乏对 3D 场景的显式建模与一致性约束,导致诸如物体突然消失或出现等不一致现象。针对这一问题,高俊博士团队在 Gen3C 中提出了一种简洁而高效的解决方案:将 3D 点云融入视频扩散模型,以引入对时间一致性与空间控制能力的建模,从而实现可控视频生成以及在极端摄像机位姿下的新视角合成。
具体来说,GEN3C 将深度估计信息反投影为点云,并通过将点云编码为 3D 缓存(3D cache)对生成模型进行引导,在生成下一帧时,GEN3C 会以 3D 缓存的二维渲染结果为条件,并结合用户提供的新相机轨迹。

利用3D cache,Gen3C在动态场景重建、多视角生成、三维编辑和长视频生成等下游任务上都取得了良好的结果:

除了在一致性方面的提升外,高俊博士认为 3D 信息同样能够为视觉基础模型提供更精确的光照控制。基于这一观察,他们提出了 DiffusionRenderer,将 3D 信息与视频扩散模型相结合,以实现更高质量的逆向渲染与重打光。尽管此前的一些扩散模型也可以通过文本提示修改视频的光照,但这种方式缺乏对场景和光照的显式建模,生成结果可能不够准确。DiffusionRenderer 引入了 G-buffer:在给定输入视频的情况下,模型首先对每个像素估计场景的几何、光照和材质属性;在前向渲染过程中,这些三维信息作为 G-buffer 条件输入,用于生成高保真的图像,下图提供了模型的框架:
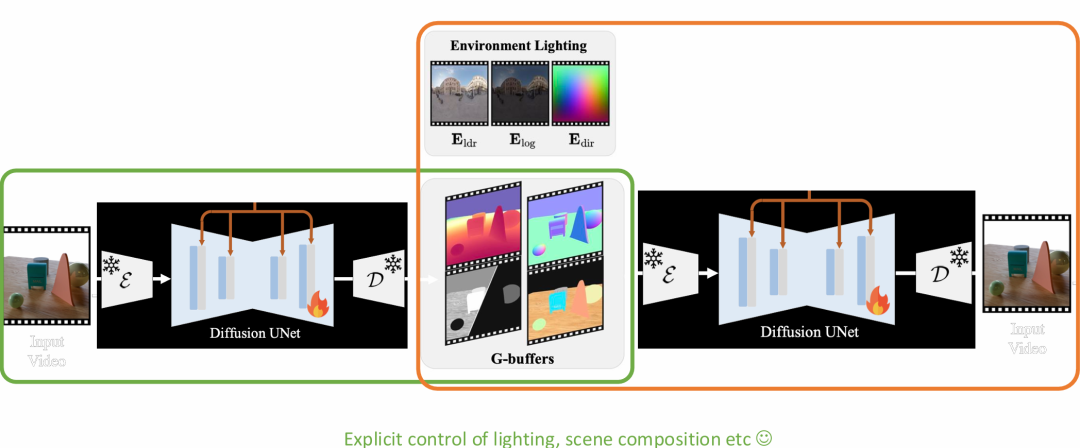
实验结果表明,DiffusionRenderer在逆渲染与前向渲染任务上表现出色,该模型支持从单个视频输入实现多种实际应用,包括重打光、材质编辑以及逼真的物体插入:

利用视觉基础模型提升3D场景理解
在介绍了 3D 表征对视觉基础模型的提升之后,高俊博士进一步探讨了视觉基础模型如何反过来促进 3D 任务的发展。他指出,视觉模型在 3D 领域可以充当高效的数据引擎。高俊博士提到,在他们近期一项名为Gen3D 的工作中,其团队利用视觉基础模型生成了大量可用数据,这些数据可用于训练各种3D重建模型,从而有效缓解了数据不足的问题。

此外,高俊博士还提到视觉基础模型能够为 3D 任务提供标注支持,他重点介绍了 PartField 工作,这是一种基于部件(parts)对 3D 物体进行分割的方法。3D 物体分割面临的主要挑战在于部件标注数据的缺乏,同时对部件的定义也缺乏严格标准。高俊博士认为,部件可以通过 3D 特征的相近性来定义。为此,他们提出了一种 3D 特征场方法,将物体表示为连续的特征场,并可通过聚类生成层级化的部件分割。

为解决标注稀缺的问题,PartField 利用 SAM 等二维感知模型的先验,通过 SAM2 对 3D 物体渲染图像生成二维部件标注,并蒸馏来自混合标注数据集的 2D 与 3D 部件信息,通过对比学习进行训练。最终,模型输出的连续特征场可用于聚类,从而生成层级化的部件分割结果:

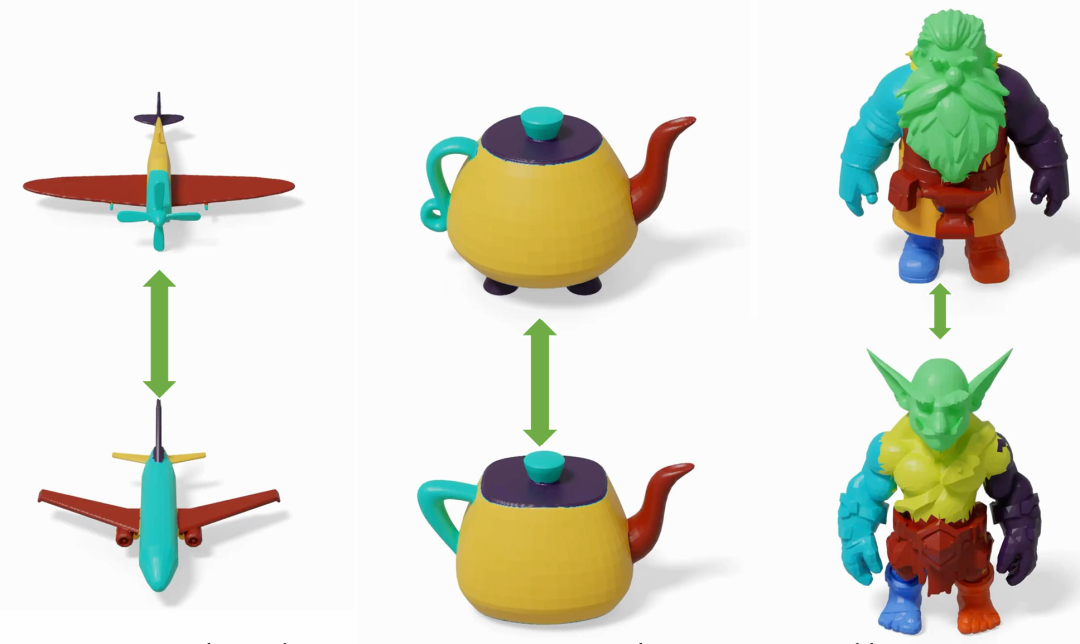
此外,高俊教授还观察到,在学习过程中会出现一种形状对应(Shape Correspondence)现象,即在不同形状之间形成一致的部件对应关系。如图所示,相同颜色表示上下两部分在分割上具有相同的对应关系:
在报告结尾,高俊博士总结了三维场景理解与视觉基础模型之间的协同优化: 3D能为视觉模型提供更精准的相机控制和一致性以及光照控制,而视觉模型则能为3D提供更多的数据和标注,将二者结合的探索推动我们迈向一种更加统一、具备 3D 感知能力的视觉理解与生成范式。
AIR长期招聘人工智能领域优秀科研人员
点这里关注我们
关于AIR










