点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
论文信息
标题:BridgeDepth: Bridging Monocular and Stereo Reasoning with Latent Alignment
作者:Tongfan Guan, Jiaxin Guo, Chen Wang, Yun-Hui Liu
机构:The Chinese University of Hong Kong、Spatial AI & Robotics Lab, University at Buffalo
原文链接:https://arxiv.org/abs/2508.04611
代码链接:https://github.com/aeolusguan/BridgeDepth
导读
单目和立体深度估计提供了互补的优势:单目方法捕获丰富的上下文先验,但缺乏几何精度,而立体方法利用透视几何,但在处理反射或无纹理表面等歧义时却感到困难。尽管事后有协同作用,这些范式在实践中仍然基本上是分离的。我们引入了一个统一的框架,通过迭代双向对齐它们的潜在表示来桥接两者。其核心是一种新颖的交叉注意力对齐机制,在立体推理过程中动态同步单目上下文线索与立体假设表示。这种相互对齐通过注入单目结构先验来解决立体歧义(例如,镜面表面),同时在单个网络内用立体几何来细化单目深度。广泛的实验展示了最先进的结果:它减少了零样本泛化误差。在Middlebury和ETH3D上,同时解决了透明和反射表面长期存在的问题。通过将多视图几何与单目上下文协调起来,我们的方法实现了超越特定模态限制的稳健3D感知。
效果展示
我们的方法通过隐式表示对齐,在单目几何推理和立体像素匹配之间架起桥梁,相较于单目模型(DepthAnythingV2),实现了卓越的深度准确性和更精细的细节。,同时超越了双目方法(NMRF)在处理无纹理表面和反射区域时具有更高的鲁棒性。
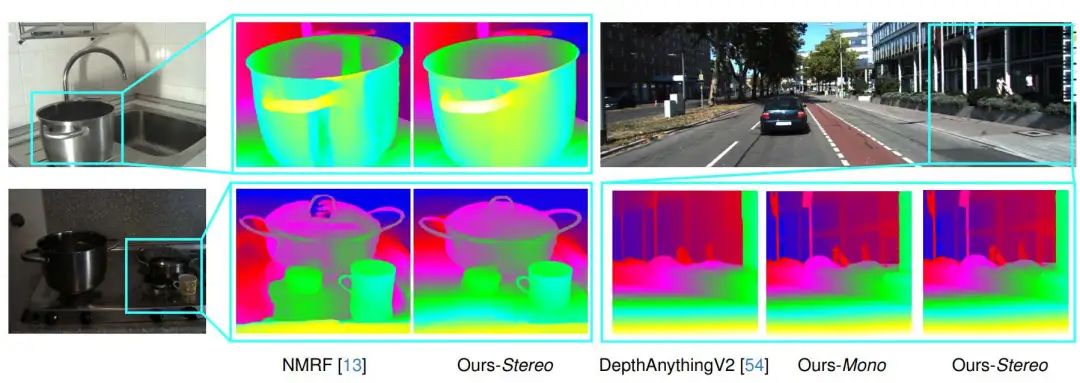
在KITTI上进行定性比较,使用针对混合KITTI2012/2015数据微调的模型。我们与领先的基准NMRF进行了比较。该模型在具有透明窗口和丰富细节的具有挑战性的区域中表现出高度的鲁棒性和准确性。

引言
深度估计是三维场景理解中的一项基础任务,在自动驾驶系统到增强现实等多样化应用中发挥着关键作用。深度神经网络的进展催生了两种主要估计范式:单目深度估计(MDE)与立体匹配。单目方法通过利用丰富的上下文先验(如物体语义、场景布局)从单张图像预测深度。相比之下,立体方法基于极线几何原理,通过标定图像对间的像素对应关系恢复度量几何结构。
这两种范式依赖不同线索并呈现互补优势。单目深度估计擅长整体推理,即使在低纹理或反射区域也能生成合理的深度预测,但由于单视图推断的病态本质,存在固有几何不准确性。立体方法通过双视图匹配实现高度量精度,但容易因遮挡、低纹理区域或镜面反射导致对应关系模糊。关键的是,尽管两者具有互补性,现有解决方案却将这两个任务孤立处理,采用独立的处理流程,未能将上下文推理与几何匹配统一起来。这种割裂从根本上限制了无约束场景下的鲁棒性——在此类场景中,上下文先验与几何保真度均不可或缺。推荐课程:单目深度估计方法:算法梳理与代码实现。
为弥合这一鸿沟,我们提出BridgeDepth框架。该框架通过迭代潜在表示对齐,将上下文推理与几何匹配协调统一。核心模块是一个交叉注意力Transformer模块,可动态同步单目上下文特征(编码物体语义和场景结构)与立体假设体积(表示对应概率)。这种双向交互使单目先验能够通过学习的结构约束,在挑战性条件下(如镜面或低纹理表面)消除立体匹配的歧义;同时立体几何信息注入度量约束,修正单目深度的不确定性。不同于依赖后处理融合启发式方法的现有工作,BridgeDepth直接将对齐过程嵌入立体代价聚合阶段,使两种范式能够相互优化表示,而非简单互补。我们的方法不仅在处理反射表面时相比立体方法NMRF实现稳定提升,还通过深度修正比单目DepthAnythingV2(DAv2)模型恢复更多精细细节。
我们的框架分两个阶段融合单目与立体推理。在预对齐阶段,单目分支提取参考立体图像的上下文特征,立体分支则利用视差提议网络(DPN)将视差搜索空间从40候选压缩至2候选,以实现高效跨模态交互。关键在于潜在对齐阶段采用交叉注意力Transformer,迭代对齐单目与立体表示:首先通过上下文特征引导假设聚合,随后利用聚合的几何约束更新单目表示,实现双向优化。推理时,BridgeDepth生成两种输出:基于优化后上下文特征的相对深度和基于立体假设表示的度量视差。综合实验表明,我们的方法在多个基准测试上达到最优性能,尤其在Middlebury和ETH3D数据集上,零样本误差相比领先立体基线NMRF分别降低41.3%和65.8%。通过协调单目上下文与立体匹配,该方法超越了模态特有的局限性,实现了鲁棒的三维感知与强泛化能力。
主要贡献
我们的贡献可总结如下:
BridgeDepth框架:通过潜在对齐联合预测相对深度与度量视差的统一模型,融合上下文推理与几何匹配。
新型交叉注意力Transformer:实现单目上下文特征与立体假设体积的迭代双向对齐,促进相互优化。
在多个基准(KITTI、Middlebury、ETH3D等)上取得最优性能,兼具效率、鲁棒性与泛化性,例如在挑战性数据集上零样本误差降低超过40%。
方法
如图2所示,我们的方法分两阶段运行:(1)预对齐阶段准备模态专用表示;(2)双向潜在对齐阶段实现跨模态同步。预对齐阶段中,单目分支从参考图像提取上下文特征,立体分支通过视差提议网络(DPN)将视差假设空间从40候选压缩至2候选,以提升跨模态交互效率。核心的双向对齐阶段随后迭代同步单目上下文特征与立体假设嵌入,穿插神经消息传递进行假设聚合。最终,对齐后的单目与立体表示分别解码为相对深度与度量视差。

实验结果

总结&未来工作
我们提出的潜在对齐框架动态耦合了几何匹配与单目上下文先验,解决了精确对应估计与可泛化上下文推理之间的根本矛盾。通过广泛的立体匹配实验验证,双向对齐机制显著提升了零样本泛化能力(如Middlebury数据集提升42.7%),并增强了对反射表面等模糊区域的鲁棒性。尽管在高分辨率(≥2K)场景下,由于视差提议网络中Top-k假设选择受限于大视差范围,实现精度可能受限,但未来可通过引入立体特征交互模块进一步优化。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001







![会议邀请[上海] :西门子EDA年度大会-AI EDA|3DIC|IC设计及验证|物理设计及验证|制造与测试](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-08-14/689d3f02e8a69.jpeg)
