点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0 论文信息
作者:Songyan Zhang,Yongtao Ge,Jinyuan Tian,Guangkai Xu,Hao Chen,Chen Lv,Chunhua Shen
机构:Nanyang Technology University, Singapore | Zhejiang University, China | The University of Adelaide, Australia
原文链接:https://arxiv.org/pdf/2504.05692
代码链接:https://github.com/wyddmw/POMATO
1 导读
本研究提出了统一动态三维重建框架 POMATO,结合点云匹配与时序运动建模。通过在统一坐标系中将多视角 RGB 像素映射到三维点云,学习匹配关系,并引入时间运动模块以增强帧间尺度一致性,提升三维点追踪等任务的精度与稳定性。

2 效果展示
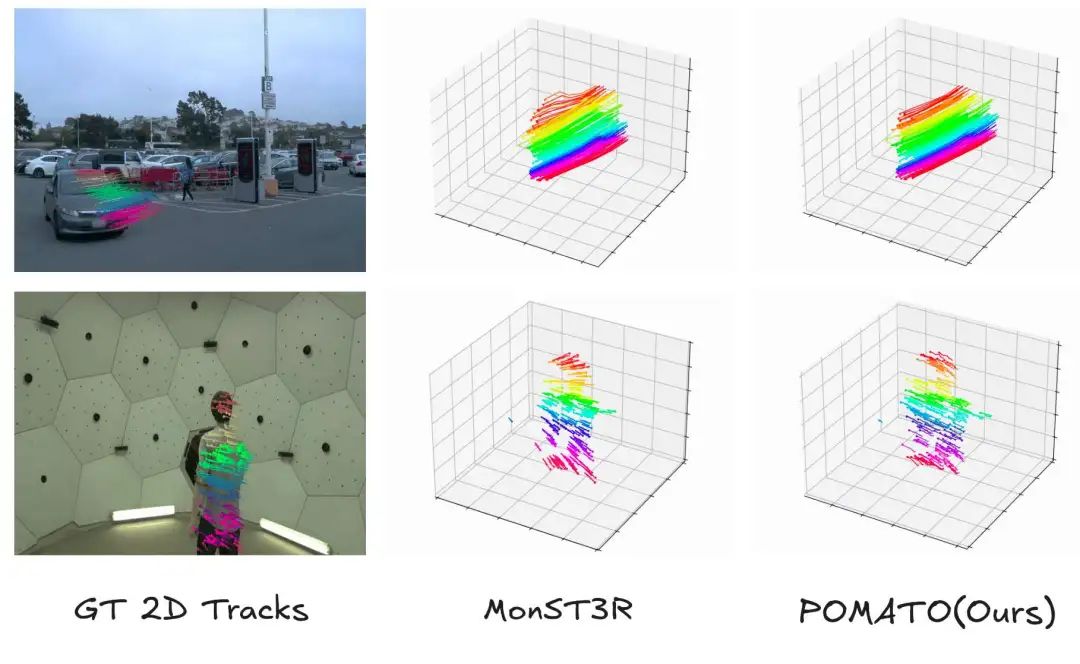
我们的模型能够得到一致的三维点云,以及相应的三维重建信息(深度、位姿和动态掩码),与MonST3R相比,结果更加鲁棒。
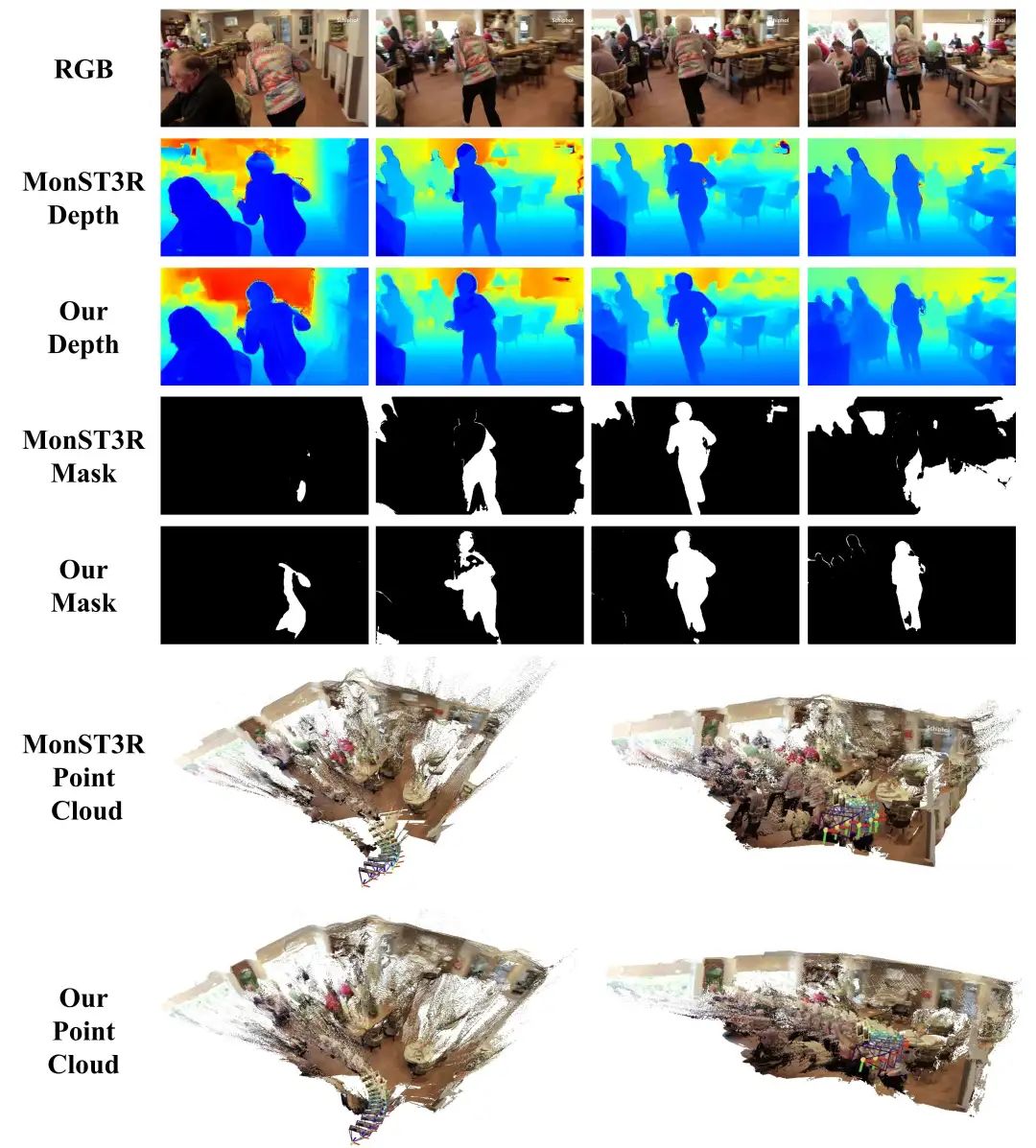
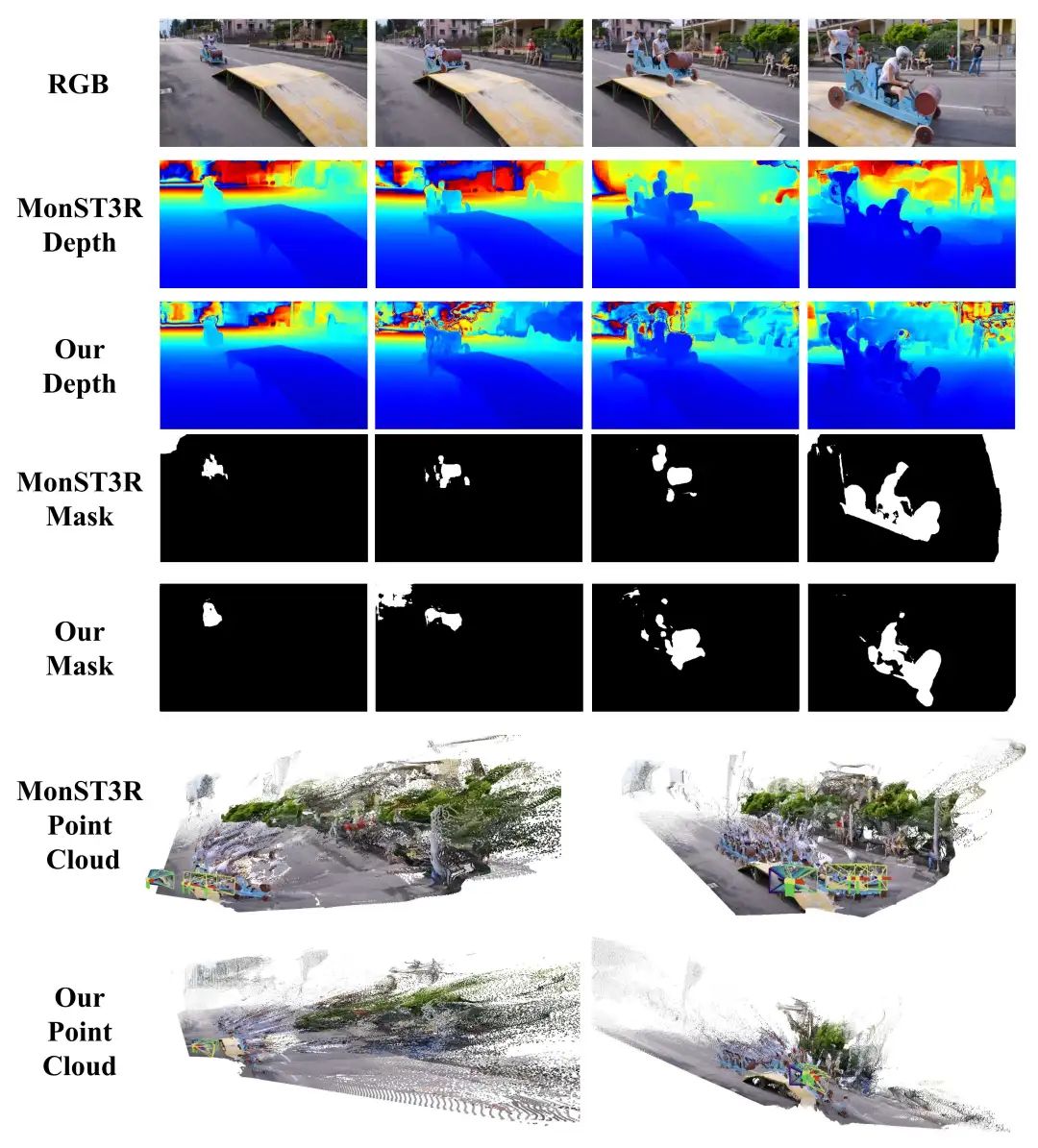
根据POMATO得到的点云匹配关系,可以得到三维点追踪的结果,这是MonST3R框架不具有的能力。
3 引言
动态场景下的三维重建主要依赖于几何估计与匹配模块的结合,其中匹配任务对于区分动态区域至关重要,这有助于减轻由于相机或物体运动带来的干扰。此外,匹配模块还能显式建模物体运动,使得对特定目标的追踪成为可能,从而推动复杂场景下的运动理解。近期,DUSt3R 提出了PointMap表示方式,为在三维空间中统一几何估计与匹配提供了潜在解决方案。然而,该方法在处理动态区域的模糊匹配时仍存在困难,限制了进一步的性能提升。
在本研究中,我们提出了 POMATO,一个统一的动态三维重建框架,通过结合点云匹配(POintmap MAtching)与时序运动(Temporal mOtion)来实现。具体而言,我们的方法首先通过在统一坐标系中将来自不同视角的 RGB 像素(涵盖动态与静态区域)映射到三维点云,学习明确的匹配关系。此外,我们还引入了一个面向动态运动的时间运动模块,以确保不同帧之间的尺度一致性,并提升对几何精度和匹配可靠性要求较高任务(尤其是三维点追踪)的表现。
我们通过在多个下游任务中的卓越表现验证了所提出的点云匹配与时间融合范式的有效性,包括视频深度估计、三维点追踪和姿态估计等任务。
4 主要贡献
首先,我们提出了一种新颖的方法,将动态三维重建中的基本几何估计与运动理解统一到一个网络中,通过引入点云匹配的表示来实现这一融合。
其次,我们设计了一个时序运动模块,用于促进运动特征在时间维度上的交互,从而在需要同时进行精确几何估计和匹配的任务中(尤其是视频序列输入下的三维点追踪)显著提升性能。
第三,我们在多个三维视觉任务中展示了有前景的性能表现,包括动态场景下的视频深度估计、三维点追踪以及相机位姿估计等。
5 方法
5.1 点云匹配
该方法基于 DUSt3R 模型,并通过引入新的模块和训练阶段对其进行了改进,旨在更精确地处理动态场景下的点云匹配。
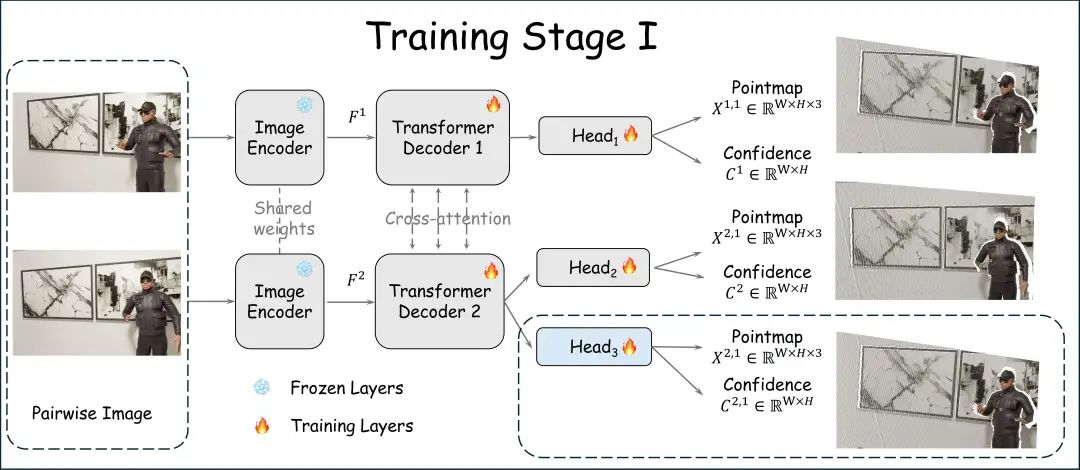
该方法的核心是在DUSt3R模型的双分支结构基础上,增加了一个专门用于显式点云匹配的新分支(Head)。
原始的 DUSt3R 模型使用一个共享权重的 ViT 编码器,并采用两个并行的解码器-回归头分支。 分支1 (Head):负责从第一张图像 估计其自身相机坐标系下的 3D 点云 。这等同于单目深度估计,用于理解场景的几何结构。 分支2 (Head):负责从第二张图像 估计其在第一张相机坐标系下的 3D 点云 。这反映了模型对相机位姿变换的理解。 改进之处——引入显式点云匹配(Head): 为了解决动态场景下定义的模糊性(即无法区分运动物体的前后位置),引入了 Head。 Head 与 Head 并行,也接收解码器2的特征,其目标是进行显式的点云匹配 。 定义: 显式点云匹配将图像 中的像素 映射到其在中对应的像素点 所对应的3D坐标。简单来说,它让两张图片中对应的点在同一个相机坐标系下具有相同的3D坐标,即在第一张相机坐标系下,像素 的点云匹配结果等于素点 的三维坐标。
第一阶段训练冻住Encoder,打开Decoder和Head进行训练。
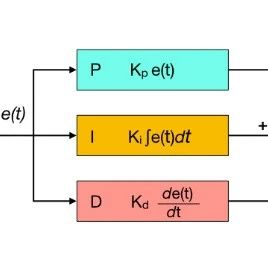
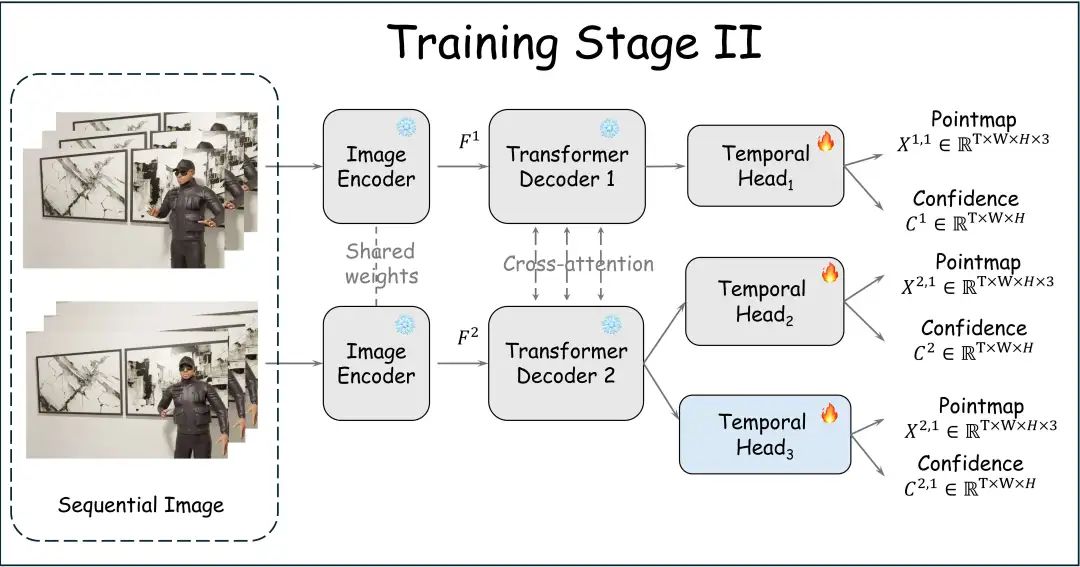
5.2 时序融合模块
核心思想:在原有的 DUSt3R 模型基础上,在 DPT(Dense Prediction Transformer)回归头中集成了一个基于 Transformer 的时序运动模块。 功能:该模块通过在时间维度上进行自注意力(self-attention)计算,实现对多帧视频特征的聚合和信息增强,从而提升帧与帧之间的一致性。 模块架构: 模块由两个标准的多头自注意力模块和前馈网络块组成。 为节省显存,该模块被策略性地应用于低分辨率的解码器特征上。 输入处理:对于一组解码器特征 (B: batch size, T: 帧数, N: 特征数量, C: 特征维度),为了能在时间维度 T 上进行处理,首先将特征维度 C 合并到 batch 维度 B 中,得到形如 (B∗N,T,C) 的张量,再送入模块。

二阶段训练引入时序融合模块,冻住Encoder和Decoder,打开Head训练。两阶段训练数据相同。
6 实验结果
我们分别从视频深度,位姿估计,三维点追踪进行了评估,在视频深度估计、三维点跟踪和相机位姿估计等任务上均取得了领先性能。它在 Sintel、BONN、KITTI 等数据集上表现优异,速度较基于全局对齐的方法大幅提升;在 PointOdyssey 和 ADT 数据集上显著提高了三维点跟踪精度;在 TUM 和 Bonn 数据集上大幅降低了相机位姿估计误差。系统采用按序列的尺度与偏移对齐、动态掩码以及点图匹配投影等技术,兼顾了精度与效率。



7 总结
POMATO 是一个结合点云匹配与时序运动建模的统一动态三维重建框架,通过在统一坐标系中将多视角 RGB 像素映射到三维点云并引入时序运动模块,提升了帧间尺度一致性与动态场景下的匹配精度。方法在 DUSt3R 的基础上增加显式点云匹配分支以更好区分动态区域,并在回归头中集成 Transformer 时序模块以增强多帧信息交互。两阶段训练策略先优化几何与匹配,再引入时序融合。实验表明,POMATO 在视频深度估计、三维点跟踪和相机位姿估计任务上均取得领先性能,在多个数据集上显著优于现有方法,同时具备更高的重建速度与鲁棒性。
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001



![[8.19 杭州]诚邀参会:NI测试测量技术研讨会 | 晶圆/光电器件/芯片测试、LabVIEW+全新开源大模型等](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-08-07/68941e4d009dd.jpeg)