“编者按:在激烈的中美AI竞赛中,我们常陷入对芯片性能的迷恋。然而,当硅谷为参数的胜利欢呼时,决定未来的战局已在芯片之外展开。
我们特地翻译这篇海外深度分析,旨在揭示美国指标陷阱的短视,并点明中国在能源、集群和开源三大领域布局的深远意义。
作者:Ignacio de Gregorio
发布日期:2025 年 8 月 2 日
美国总觉得自己,在人工智能芯片和基础设施上,已经把中国远远甩在身后。
这种自信不仅站不住脚,更是源于一系列错误的假设。
这种领先,纸面上看或许没错,但实践中却并非如此。说到底,这根本不重要。
让我们深入剖析人工智能硬件的真实格局,看看英伟达这类巨头所在的行业,你就会明白,美国为何在低估中国这个最可怕的对手时,犯下了几个致命的错误。
“本文用最根本的逻辑和最易懂的语言,为你解读人工智能。献给那些厌恶炒作、渴望真知的读者。
硬件的真实水平
一家叫 Epoch AI 的机构最近发布了份有趣的报告,对中美人工智能硬件竞赛给出了他们的看法。
长话短说,他们认为中国未来几年仍会处在追赶的位置。在图形处理器技术上,至少会比英伟达和 AMD 落后一代。
虽然这个结论在各方面都难以辩驳,但实际情况远比想象的复杂。而这种片面的认知,正让美国沉浸在一种虚假的安全感里。
人工智能硬件的核心
首先,我们必须明确,人工智能硬件有三个关键指标:
运算速度:即每秒能执行多少次浮点运算。 内存带宽:数据进出核心能有多快、有多少。 芯片间通信速度。
这三者为何如此关键?
简单来说,人工智能模型在训练时,是海量的矩阵乘法;在推理时,则是矩阵与向量的乘法。本质上,就是天文数字般的数学运算。
因此,芯片的运算速度越快,模型跑得就越快。
第二个关键是内存带宽和内存大小。后者之所以重要,是因为前沿模型动辄几百 GB,体积庞大,远超单个芯片的内存容量。
但前者,也就是带宽,甚至更为致命。
带宽决定了数据进出内存的流量。任何计算架构中,程序都存在内存里,而非固化在芯片上。芯片要工作,数据就必须从内存搬到芯片,算完再存回内存。
芯片边上的高速缓存极小,而模型又极大,所以模型必须被切分成小块处理。这意味着,哪怕只是简单跑一次「前向传播」(比如让聊天机器人读一段话、生成下个词),也需要无数次读写内存。
所以,数据传输的量和速度,就成了决定性的瓶颈。在我及许多专家看来,优化内存带宽,是避免内存墙问题的重中之重,其优先级甚至高于算力本身。
最后,也是英伟达最核心的护城河(即便对比 AMD 和谷歌,在拥有自家软件 CUDA 的加持下),无疑是其 GPU 之间的通信速度。
前面提到,模型要被拆分才能送入芯片。但这还不是全部,模型(有时甚至数据本身)除了拆分,还必须分布在多个加速器上,比如多个 GPU。
这意味着,通信不仅发生在单一 GPU 的计算和内存芯片之间,更发生在成百上千个 GPU 之间。如果说内部的内存带宽是瓶颈,那 GPU 之间的通信就是更大的瓶颈,因为速度会急剧下降。
说白了,任何一个 GPU 都可能在空转,不光等自己的内存,还要等其他 GPU 把数据传过来。
那我们怎么衡量这种复杂的数据流转效率呢?
方法很简单,就是看我们的计算任务,离一个叫「算术强度」的阈值有多近。这个阈值是计算能力和带宽速度的比值,我们得尽力贴近它。
举个例子,一块英伟达 Blackwell B200 芯片,在 FP8 精度下算力高达 9 PetaFLOPs,内存带宽为 8 TB/秒。二者相除,算术强度就是 1125。
这代表每传输 1 字节的数据,我能完成 1125 次运算。
如果你的任务算术强度高于 1125,你就受限于计算。这意味着你的算力核心在全力运转,一刻也没闲着。
如果低于这个值,你就受限于内存。这意味着 GPU 大部分时间都在搬运数据,而宝贵的计算核心却在摸鱼。
计算能创造收入,数据传输只是成本。所以,你的目标必须是让算力跑满,至少要接近那个算术强度阈值。当然,现实往往很残酷,大部分应用都严重受限于内存。

总而言之,一个 AI 计算集群的优劣,要看所有这些指标。那么,中国的芯片表现如何?第一眼看上去,确实不怎么样。
在这三个关键领域,中国的顶级芯片全面落后:
内存带宽:差两倍。 计算速度:差三倍。 GPU 间通信:差两倍(对比英伟达的 NVLink),如果用 PCIe4 连接,则差了十倍。
更糟的是,中国最大的芯片制造商中芯国际,其良率(能正常工作的芯片比例)还不到 50%,而为英伟达代工的台积电,良率则高达 90%。
所以,表面上看,这简直是云泥之别。但,本文的核心观点恰恰是:中国对此毫不在乎。
为什么?
问题的关键是视角
西方世界一直没弄明白,中国根本不关心利润、毛利率或者良率这些商业指标。因为他们会不惜一切代价,投入一切资源,来玩这场游戏,并且要赢。
这就是把一项技术视为国家安全问题和战略级技术,与将其看作赚钱机器之间的根本区别。
因此,中国的决策者们,虽然也希望芯片性能和生产良率能提升,但无论技术指标有多难看,他们都会动用国家力量,提供无限支持,直到胜利为止。
但这还没完。在所有数据中心、服务器和芯片的背后,最终的制约因素是能源和电力成本。
当美国和欧盟现在才后知后觉地意识到能源是关键时,中国早已在能源网络上布局了几十年,并且在能源部署上取得了碾压性的优势。
事后复盘总是容易的,但我很难想出比下面这张图更具冲击力的对比了。看看每条曲线的爬升斜率,这差距大到让人说不出话。
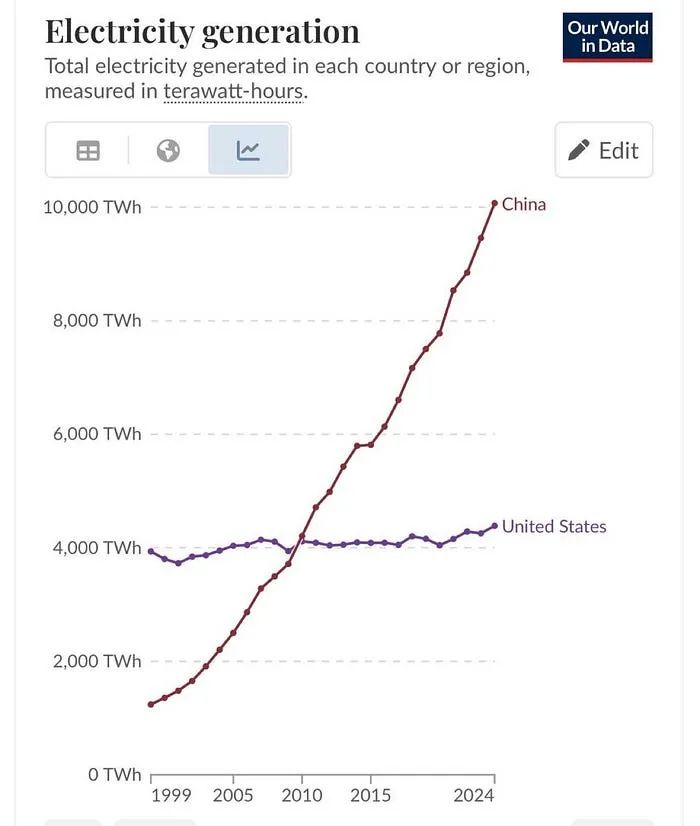
当我们还在纠结中美单块芯片的性能对比时,如果中国的能源成本趋近于零,这种对比就变得毫无意义。
到那时,他们根本不在乎华为芯片的能效比是高是低。既然电力近乎免费,他们只需要部署更多芯片就行了。
这并非预测,而是正在发生的事实。
美国的实验室还在为部署一台 130 千瓦的英伟达服务器而头疼时,中国已经开始部署高达 500 千瓦的华为昇腾 910C 服务器集群,其功耗足以供应 167 个欧洲家庭。
所以,我们该明白什么?
“这里的核心是,要用服务器集群的视角,而不是单块芯片的视角来看问题。
没错,一块英伟达 Blackwell 芯片能完爆一块华为昇腾芯片。但一个华为的服务器集群,同样能完爆一个英伟达的服务器集群。
尽管华为方案的单位能耗性能更高,但当能源在中国几乎免费,且利润可以被忽略数十年时,这种劣势就显得微不足道了。这在美国是不可想象的。
总而言之,尽管中国的芯片较差,但华为这样的公司,只需建造规模庞大的数据中心,就能完全弥补单点技术的不足。如果你的芯片快三倍,我就把价格降到你的三分之一;如果你的集群吞吐量高两倍,我就把集群建到你的两倍大。
当然,良率是个问题。美国在部署数据中心的速度上,或许仍有优势。
中国的制造商每生产一个单位的有效算力,需要消耗近两倍的晶圆。这意味着,这个限制因素确实存在,但具体影响多大,目前还缺乏数据支撑,我们只能推测。
所以,当我们把视角从芯片转向服务器集群时,能源成本就成了一个被严重低估的决定性因素。
在这种模式下,中国企业能获得巨额补贴甚至免费的能源,以及建设超大规模数据中心所需的一切土地,从而完全抵消其芯片层面的短板。
你可能会反驳:「既然如此,中国的实验室为什么还在拼命求购英伟达的芯片?」
这很正常,因为在同等成本下,英伟达芯片确实能提供更高的效率,中国的实验室也需要考虑成本优化。
但问题的关键是,他们并不会因为买不到英伟达芯片就停下脚步。他们受到的影响远比我们想象的小,并且总能通过其他方式,哪怕效率低一些,来达到同样的目的。
让我再强调一次核心观点:
“中国在乎的是最终能否到达目的地,而美国在乎的是一路上有没有钱赚。
除此之外,还有一个更令人担忧的方面:美国正在输掉开源之战。
开源:芯片生态的胜负手
很多人不理解,为什么要将耗资巨大的模型和技术免费开源。
“把这么贵的东西白送出去,图什么?
在公司层面,这或许很难解释。但在国家安全层面,这却是最基本的常识。美国政府理应强力鼓励本国顶尖实验室,尽可能地拥抱开源。
原因很简单:在中美竞争的棋局中,胜利不仅取决于谁的模型最强,更取决于全球的算力,是用谁家的货币来支付的。
换句话说,模型能推动一国技术的普及,但更重要的是,它能激励全球用户,采用这个国家的基础设施。
随着服务器架构日趋复杂和定制化,模型将变得越来越依赖特定的芯片。
比如,传闻 OpenAI 下一个开源模型,将只能在英伟达最新的 Blackwell 芯片上运行。这就是开源的威力所在。
“谁在开源上领先,谁就能主导模型的生态。而当模型与芯片深度绑定时,你就能把全世界的开发者和客户,都吸引到你真正的金矿上:芯片。
美国的宏大战略,理应是将美元与人工智能算力挂钩。如果算力是新时代的石油,你最好确保它是用美元来结算的。
但现在的问题是,在开源模型领域,中国正以惊人的势头碾压美国,目前排名前五的开源模型均来自中国。
美国的官方人工智能行动计划,反复强调开源的至关重要性。
然而,现实却极具讽刺意味:当美国还在高谈阔论时,中国反而在默默践行美国自己设定的战略路径,而美国的顶尖实验室们,却在做着完全相反的事情。
原文地址:https://medium.com/@ignacio.de.gregorio.noblejas/what-china-gets-the-us-doesnt-f12059d0613d
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!