编辑:冷猫
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。这是一个可实现大规模 LLM 强化学习的开源 SOTA 系统,使用该算法,该团队成功让 Qwen2.5-32B 模型在 AIME 2024 基准上获得了 50 分,我们也做了相关报道。

论文地址:https://dapo-sia.github.io/static/pdf/dapo_paper.pdf
代码地址:https://github.com/volcengine/verl/tree/gm-tyx/puffin/main/recipe/dapo
中国科学技术大学校友,伊利诺伊大学香槟分校博士,微软研究院的首席研究员刘力源、清华大学校友,加州大学圣地亚哥分校计算机科学与工程学院博士生姚峰团队在强化学习的研究中更进一步。
该团队发现,在 DAPO-32B 中,rollout 生成是强化学习训练的主要瓶颈,占据了约 70% 的总训练时间。因此,该团队从 rollout 阶段着手,将 8 bit 量化技术应用于 rollout 生成,并通过 TIS 技术在保持下游性能的同时实现了显著加速。
众所周知,FP8 能让强化学习运行得更快,但往往以性能下降为代价。
刘力源、姚峰团队推出 FlashRL,是首个开源且可用的强化学习实现方案,在推理执行(rollout)阶段应用 INT8/FP8,并且在性能上与 BF16 持平,没有性能损失。该团队在博客中完整发布了该方法的技术细节。

博客标题:FlashRL: 8Bit Rollouts, Full Power RL
博客地址:https://fengyao.notion.site/flash-rl
代码地址:https://github.com/yaof20/Flash-RL
Rollout 量化可能会降低性能
如图 1 和图 2 中 「⋅⋅⋅⋅⋅」 曲线所示,在未使用 TIS 技术的情况下,采用 FP8 或 INT8 进行 rollout 量化,相比 BF16 rollout 会带来显著的性能下降。
这一现象是预期中的,因为 rollout–训练之间的差异被放大了:rollout 是从量化策略 π_int8 采样的,但梯度却是基于高精度策略 π_bf16 计算的。
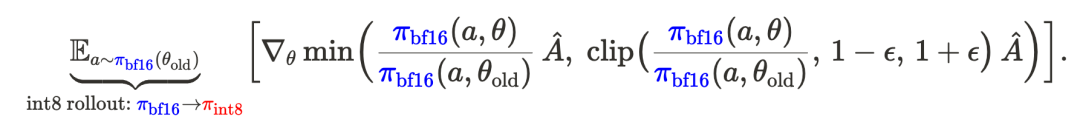
这种不匹配会使强化学习过程更加偏离策略,从而削弱强化学习训练的有效性。

图 1 左图:吞吐量加速比。FP8 结果在 H100 上测试;INT8 结果分别在 H100 和 A100 上测试。结果基于不同的响应长度和设备测得。右图:Qwen2.5-32B 模型在使用 BF16 rollout 与 INT8 rollout 时的 AIME 准确率对比。所有实验均采用 BF16 FSDP 训练后端。
FlashRL 的独门秘诀
FlashRL 是首个开源且可用的强化学习方案,能够在不牺牲下游性能的前提下使用量化 rollout。
那么,它的「独门秘诀」是什么呢?
解决 Rollout–训练不匹配问题
该团队引入了截断重要性采样(Truncated Importance Sampling,TIS)来减轻 rollout 与训练之间的差距。正如图 1 和图 2 中的实线所示,TIS 使量化 - rollout 训练的性能达到了与采用 TIS 的 BF16 rollout 训练相同的水平 —— 甚至超过了未使用 TIS 的朴素 BF16 rollout 训练。
作者团队之前发表过有关 TIS 的技术博客,感兴趣的读者可以参考:

博客标题:Your Efficient RL Framework Secretly Brings You Off-Policy RL Training
博客链接:https://fengyao.notion.site/off-policy-rl
在这里简单展示一下 TIS 的工作原理。

支持在线量化
现有的推理引擎(如 vLLM)针对大语言模型推理服务进行了优化,但在支持带参数更新的模型量化方面能力有限。该团队提供了 Flash-LLM-RL 包,对 vLLM 进行了补丁,使其能够支持这一功能。
如图所示,FlashRL 的 INT8 可带来高达 1.7 倍的吞吐量提升,同时保持 RL 的优势。此外,如果不使用 TIS 而使用 naive FP8/INT8 ,性能将显著下降。

图 2 左图与中图:在使用量化 rollout 生成的强化学习大语言模型训练中,GSM8K 的准确率表现。请注意,TIS 对缓解分布差异至关重要。右图:π_fsdp 与 π_vllm 之间的 KL 散度。需要注意的是,INT8 rollout 的 KL 散度大于 FP8 rollout 的 KL 散度。
FlashRL 能有多快?
比较在强化学习训练中采用不同 rollout 精度的吞吐量并不简单,因为模型会不断更新,对于同一个查询,不同的量化策略在经过一定的 RL 训练迭代后可能会生成长度不同的回复。
这里将探讨 FlashRL 所实现的加速效果及其对训练效果的影响。
Rollout 加速表现
常规环境下的加速:
研究团队记录了在 7B、14B 和 32B Deepseek-R1-Distill-Qwen 模型上使用 INT8、FP8 和 BF16 精度的 rollout 吞吐量。
图 1 显示了 8 位量化模型相对于 BF16 的加速比。对于较小的 7B 模型,加速比不足 1.2×;而在 32B 模型上,加速比可达 1.75×。这表明量化对大模型的收益远高于小模型。基于分析结果,团队建议仅在模型规模超过 140 亿参数时使用量化。
内存受限环境下的加速:
研究团队还评估了在标准推理场景(不涉及 RL)下,采用 8 位量化所能带来的吞吐量提升。具体而言,团队测量了 INT8 的加速比,作为压力测试,用于验证其在 A100/A6000 和 H100 GPU 上的适用性。
使用 vLLM 在相同数据集上分别服务 BF16 与 INT8 量化版本的 Deepseek-R1-Distill-Qwen-32B 模型,并在 A100/A6000 和 H100 GPU 上记录其吞吐量。

图 3 在 4 种仅推理配置下,INT8 量化的 Deepseek-R1-Distill-Qwen-32B 相对于 BF16 的吞吐量加速比,测量结果涵盖不同回复长度。
如图 3 所示,当 GPU 内存成为瓶颈时,量化能够带来极高的加速比 —— 在 TP2-A6000 配置下生成速度提升超过 3 倍,在 TP1-A100 配置下提升甚至超过 5 倍。这突显了量化在 GPU 内存受限场景(如服务更大规模模型)中的巨大潜力。
端到端加速与效果验证
研究团队将 FlashRL 部署于 DAPO-32B 的训练中,以验证所提方法的有效性。由于在图 2 中 FP8 相比 INT8 拥有更小的分布差距,特意选择 INT8 作为更具挑战性的测试场景。
图 4 展示了在 BF16 与 INT8 rollout 下的下游性能与训练加速效果。两种配置在 AIME 基准上的准确率相当,但 INT8 显著提高了训练速度。
这些结果证明,FlashRL 能在不牺牲训练效果的前提下,实现显著的训练加速。

图 4. 左图:使用 BF16 与 INT8 rollout 精度进行强化学习训练的下游性能对比。右图:BF16 与 INT8 rollout 在单位小时内可完成的更新步数。所有实验均基于 DAPO 配方,在 Qwen2.5-32B 模型上进行,训练 250 步,硬件配置为 4 个节点、每节点配备 8 张 H100 GPU。
快速使用
使用 FlashRL 只需一条命令! 使用 pip install flash-llm-rl 进行安装,并将其应用于你自己的 RL 训练,无需修改你的代码。
FlashRL 方法支持 INT8 和 FP8 量化,兼容最新的 H100 GPU 以及较老的 A100 GPU。

更多方法细节,请参阅原博客。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com

![[8.19 杭州]诚邀参会:NI测试测量技术研讨会 | 晶圆/光电器件/芯片测试、LabVIEW+全新开源大模型等](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-08-07/68941e4d009dd.jpeg)