鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
随手拍的一张图,就能秒变3A级游戏大作?!
刚刚,腾讯全新开源游戏视频生成框架Hunyuan-GameCraft,专为游戏环境设计,让任何人都能轻松搞定游戏制作。
无论是水墨风:

抑或是古希腊:

只要你想,统统都能满足。
基于腾讯混元视频生成HunyuanVideo搭建,可以实时生成流畅画面。
操作也很so easy,只需要:单张场景图+文字描述+动作指令=高清动态游戏视频。

所以下面让我们一起Game start!
实机演示
先来康康几个生成案例尝尝鲜:
首先做一个中世纪的乡村风格场景,画面流畅自然,镜头随第一视角动态移动。
Prompt:A picturesque village scene featuring quaint houses, a windmill, lush greenery, and a serene mountain backdrop under a bright blue sky.
或者试试多动作场景,可以在转换视角的同时完成行走动作。
Prompt:A sunlit courtyard features white adobe buildings with arched doorways and windows, surrounded by lush greenery and palm trees, creating a serene Mediterranean ambiance.
还能保持历史一致性,移开镜头回来之后,场景不会出现变形情况。
Prompt:A medieval stone castle stands tall under a dark sky, its glowing windows contrasting with the surrounding snow-covered landscape.
除了第一视角,也可以进行第三人称视角生成。
Prompt:A dark, sleek car is driving down a winding road at night, its headlights illuminating the path ahead.
除了视角切换、场景转换这类基础生成能力,例如动态天气(云层移动、雪花飘落)以及NPC互动等复杂内容,也能被Hunyuan-GameCraft一一实现。
那么具体是怎么做到的呢?
个人生产3A级动态内容
要知道,传统的游戏视频生成工具长期面临三大瓶颈:
- 动作僵硬、场景静态
角色移动机械单一,只能够简单的平移或转身,且二者不能同时完成,整个运动范围也都局限在非常小的区域。
场景依赖预渲染,一旦完成静态3D场景构建,再对其进行改动,后续场景将失去动态能力。
- 长期一致性差
在切换视角后,原来的场景会改变甚至消失,历史帧信息保留不足,缺乏记忆性。
- 生成成本高
由于使用人工建模完成,需要专业的3D人工建模团队以及高端显卡支持,成本昂贵,不利于普通消费者创作。

而Hunyuan-GameCraft凭借技术创新逐个击破,三大核心优势全覆盖:
自由流畅:基于统一连续动作空间设计,支持高精度控制(如角度、速度),也能完成边跑动边转换视角的复杂操作,动态内容生成(例如NPC互动、天气变化、水流运动等)也不在话下,画面相当流畅自然。
记忆增强:借助混合历史条件建模,系统可以精准记忆历史帧,确保长视频内容一致性。
成本骤降:由于对推理步数进行压缩,且实现量化13B模型,该架构仅需消费级显卡RTX 4090即可运行,制作成本得以降低。另外相比现有的游戏模型闭源方案,其泛化能力更强。
Hunyuan-GameCraft的低门槛和开放性,让它在各个领域都能广泛适用,无论你是想游戏开发、视频创作还是3D设计,自己一个人就能包圆整个3A级动态内容制作过程,而无需专业建模和渲染知识。
从离散用户动作到连贯游戏视频
Hunyuan-GameCraft在架构搭建过程中,精选上百款3A级游戏,如《刺客信条》、《荒野大镖客:救赎》、《赛博朋克 2077》,作为游戏场景数据来源。
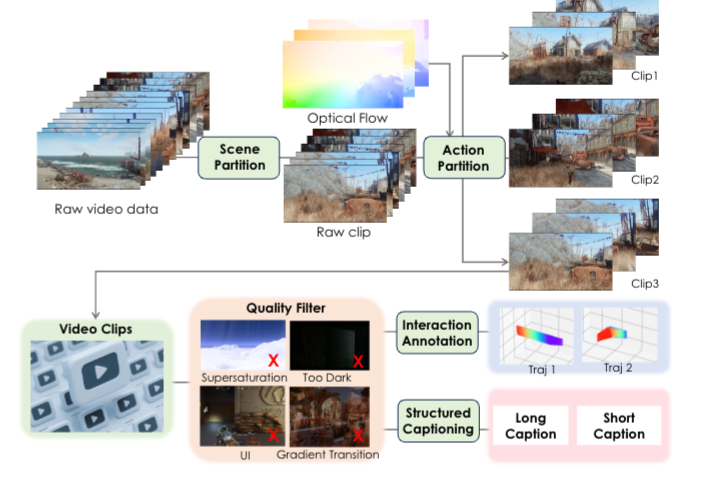
另外从已有的3D资源中渲染了约3000个高质量运动序列,系统重新采样并构建合成数据,以弥补真实世界样本的不足。
然后一方面对起始结束向量进行分层采样,另一方面进行时间反转增强,结合渲染数据微调,综合提升控制信号的泛化能力和训练稳定性。

整体模型以HunyuanVideo为基础,通过四个关键技术模块实现对用户交互动作的精准响应和长序列视频生成:
- 交互信号统一与编码
模型将键盘(如W/A/S/D控制移动)和鼠标(如视角旋转)等操作,通过6自由度相机参数(位置、方向、视野)量化为动作信号,再经过多层感知器(MLP)编码,映射到共享的相机表示空间。
- 混合历史条件建模
选取最近的关键帧作为条件输入,保留场景细节(如物体位置、环境状态),同时通过自回归方式传递前序生成的隐向量,捕捉时间动态(如运动轨迹、速度变化)。
- 模型蒸馏与效率优化
采用知识蒸馏技术,以大模型(教师模型)的输出分布为监督,训练轻量级模型(学生模型),在减少参数量和计算量的同时,保持长时序一致性和生成质量。
- 扩散过程中的动作控制
将编码后的交互信号与文本特征、历史条件特征融合,通过交叉注意力机制注入每一时间步,确保生成的视频帧严格响应操作指令。
然后在大规模真实游戏数据集上预训练,再在合成数据集上微调,同时通过分布平衡策略优化数据分布。
将模型与当前视频生成领域的主流模型进行多维度性能对比,实验证明Hunyuan-GameCraft 的光流一致性得分比次优模型高18.3%,动作响应延迟低至87ms,PSNR/SSIM则在复杂场景中领先5%-12%。
主观评估中,其真实感和可控性评分分别达到4.2/5和4.1/5,显著高于其他模型(最高3.5/5),“愿意持续交互” 的比例达78%,是对比模型的1.5-2倍。

在细粒度控制任务中,能准确响应92%的离散动作输入(如连续按 “左方向键” 实现平滑视角左转),而基线模型平均准确率仅65%。

长时序生成中,10分钟视频的时空一致性误差(物体位置偏移、场景突变)比对比模型低60%以上。

复杂动态场景 (如战斗爆炸、快速追逐)生成中,视觉细节完整度和动作逻辑连贯性评分领先30%。
项目官网:https://hunyuan-gamecraft.github.io/
代码:https://github.com/Tencent-Hunyuan/Hunyuan-GameCraft-1.0
技术报告:https://arxiv.org/abs/2506.17201
Hugging Face:https://huggingface.co/tencent/Hunyuan-GameCraft-1.0
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟



![[8.19 杭州]诚邀参会:芯片测试、LabVIEW+全新开源大模型、前沿射频测试等](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-08-08/68957dcfb3887.jpeg)