
与传统的路径规划不同,机器人的通用导航不仅要求机器人能够在未知或动态环境中安全移动,还需要具备灵活的探索能力和跨场景、跨平台的适应性。
为了应对这些挑战,研究者们提出了多种学习型导航策略,其中两项极具代表性的工作:
NavDP 聚焦于基于策略和评价函数的高效路径规划与避障;
NoMaD 通过统一的目标条件扩散策略实现探索与目标导向行为的无缝结合。
它们虽路径不同,却共同指向一个核心 —— 用扩散模型打破 "探索与导航" 的界限,让机器人真正学会在复杂世界中 "自主思考"。从不同角度诠释了通用导航的可能性。

NavDP
第一篇来自上海AI Lab的工作NavDP,可以说直接放弃“真实世界”,全靠在虚拟世界训练。

这项工作直接零样本(zero-shot)把模拟学到的本事搬到真实世界,不仅能适配不同形态的机器人,还能在室内外各种复杂场景中活蹦乱跳。核心思路是——扩散模型负责生成候选轨迹,评论家(critic)负责挑选安全路线,这种组合确保机器人不仅能走,还走得稳妥。
背景
对于机器人来说,在动态开放世界中导航是一项基本但具有挑战性的技能。为了追求具身导航的通用性,我们希望模型能够跨本体和非结构化场景进行zero-shot。
随着3D资产的日益多样化和神经渲染算法的快速发展,长期存在的sim2real gap问题也可以很快得到缓解。
整体框架
研究提出了一个新的端到端的基于transformer的框架——NavDP。可以实现zero-shot、sim2real转移以及跨本体的泛化(仅利用仿真数据)。
1. 推理框架
NavDP 推理分两阶段:
第一个阶段:用 RGB-D 图像 + 导航目标,经策略 Transformer 编码后,通过扩散生成轨迹;
第二个阶段:将生成轨迹与 RGB-D token 融合,再经共享 Transformer 与 critic head,选择与目标无关的安全轨迹。
2. 模拟特权信息利用
生成器训练:利用模拟环境中的全局最优规划器指导轨迹生成。
Critic 训练:利用模拟环境的全局 ESDF,从负样本轨迹中学习精细空间理解。
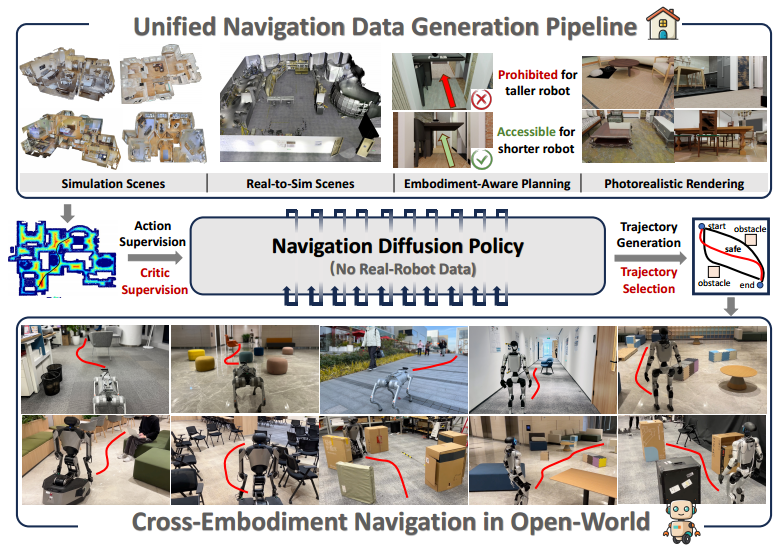
3. 数据规模与效率
模拟数据生成速度约 2,500 条轨迹/GPU/天,比真实采集快 20 倍;数据集覆盖 1244 个场景、总长度 363.2 km。
4. 跨形态泛化能力
仅用模拟数据训练,即可在四足、轮式、人形等不同机器人,以及室内外环境中实现零样本泛化,并在多种场景中优于已有方法。
5. 真实到模拟(Real-to-Sim)增强
采用 Gaussian Splatting 重建真实环境,提供更高真实感的训练与评测平台。通过实验发现,在训练集中加入 27% 的 real-to-sim 样本,可使目标场景成功率提升 30%,且不损害泛化能力。
数据生产
1. 机器人模型
模拟中建模为圆柱刚体 + 差速驱动,安全半径 0.25 m;顶部安装单目 RGB-D 相机,高度在 0.25–1.25 m 间随机,以模拟不同机器人视角;相机俯仰角随高度在 −30°~0° 间随机,HFOV/VFOV 分别为 69°/42°(与 RealSense D435i 一致)。
高于相机高度的物体不视为障碍物。
2. 轨迹生成

整体流程为:场景网格 → 体素地图(0.05 m 分辨率) → 计算 ESDF
Step1:根据机器人高度设置导航阈值 h_nav 和障碍阈值 h_obs,截断低于安全半径的体素距离。
Step2:将 ESDF 下采样到 0.2 m 便于 A* 规划,随机选起点与终点生成初步路径。
Step3:对每个路径点用局部贪心搜索远离障碍物,再用三次样条平滑生成连续轨迹。
3. 场景与仿真
从 3D-Front 和 Matterport3D 中选取 1200+ 场景,每场景采样 100 对起终点。
用 BlenderProc 渲染真实感 RGB-D 图像,并保存相机与底盘位姿作为标签。数据集含 56k+ 轨迹、1,000 万张图像,总导航距离 >360 km。
NavDP 方法结构概述
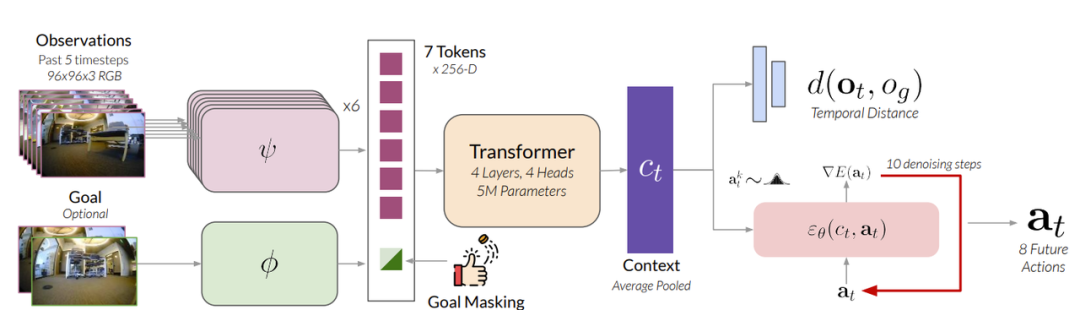
1. 多模态输入编码
输入:单帧 RGB-D 图像 + 导航目标(四种类型:点目标、图像目标、轨迹目标、无目标)。
深度数据:裁剪至 0.1–3.0 m,RGB 经预训练 DepthAnything ViT 编码,深度由自训练 ViT 编码,分别产生 256 个 patch token。
Transformer 解码器:将 512 个 RGB-D token 压缩为 16 个融合 token。
导航目标编码为单独 token,与融合 token 及轨迹 token 一起构成下游输入。
所有目标类型均可从原始轨迹自动生成,无需人工标注。
2. 扩散生成策略头(Diffusion Policy Head)
任务:生成未来 24 步相对位姿变化 (Δx, Δy, Δω)。
结构:条件 U-Net + DDPM 调度器。
条件上下文:由两层 Transformer 编码器处理的输入 token(前 16 位为 RGB-D token,接着 3 位为目标 token,最后 1 位为轨迹 token 占位符)。
生成过程不访问轨迹 token;多任务互不干扰,每次仅关注与当前任务相关的目标 token;无目标任务不关注任何目标 token。
特定索引的融合 token 作为条件输入 U-Net 进行轨迹生成。

3. Critic 安全评估头
作用:对扩散策略生成的多条轨迹进行安全性评估,选取最优安全轨迹,避免累积预测误差导致碰撞。
特点:与策略头共享 Transformer 及 RGB-D token 编码,但不使用目标 token;轨迹 token 置于最后索引,由 1D 卷积编码。
推理时批量生成候选轨迹,基于 Critic 预测分数选取执行轨迹。
4. 核心优势
扩散策略捕获多模态轨迹分布,Critic 实现目标无关的安全选择。
多模态编码支持多种导航目标形式,且自动标注成本为零。
架构设计可同时应对多任务且避免互扰,确保推理稳定与泛化能力。
模型训练
NavDP 的训练包括两个核心模块:扩散策略头和Critic 判别头,均使用仿真数据进行训练。

为了增强训练数据的多样性,研究通过随机采样轨迹的起点和终点,将轨迹拆分为子片段作为训练单元。每个子轨迹的中间帧动作以相对于起点的相对位姿表示,从而生成四类导航目标:
点目标:终点位姿作为导航目标;
图像目标:终点对应的 RGB 图像作为导航目标;
轨迹目标:子轨迹投影回第一视角形成轨迹目标;
无目标:掩蔽所有目标信息,模拟自由漫游任务。
通过调整输入掩码,策略头可以根据不同任务条件生成动作序列,实现多任务训练。
对于 Critic 判别头,希望模型能够区分安全和危险轨迹。由于训练数据本身全部为碰撞自由的轨迹,直接训练无法学习危险轨迹的特征,因此引入了数据增强:
(1)对原始轨迹进行随机旋转,并通过插值生成混合轨迹,增加轨迹多样性。
(2)增强轨迹经过编码后输入 Critic 模块进行安全性评分。
(3)利用全局 ESDF 地图,我们可以为每个轨迹点计算到障碍物的距离,从而生成判别标签,使 Critic 学会优先选择离障碍物更远或远离障碍物趋势更明显的轨迹。

通过这种方法,Critic 模块既可作为训练辅助,也可在推理时用于安全轨迹选择。
实验部分(五大核心问题)
Q1:跨机器人平台泛化能力
任务:No-goal(安全探索)+ Point-goal(路径规划)
对比对象:学习型方法(GNM, ViNT, NoMad, iPlanner, ViPlanner)+ 规划型方法(EgoPlanner)
结果:NavDP 在不同机器人(Dingo、Go2、Galaxea R1)上稳定高于基线。


Q2:模型组件贡献
Critic 模块:既是训练的辅助损失,又用于推理时轨迹选择;移除后性能显著下降。
任务设计:No-goal 训练目标对整体避障行为影响最大。
结论:Critic 是性能提升的关键模块,任务组合影响最终安全性。

Q3:零样本 Sim-to-Real 泛化
测试平台:Unitree Go2、Galaxea R1、Unitree G1
场景:室内 + 室外,含动态行人干扰
结果:在光照、视角、运动模糊等差异下仍能安全导航,显示出良好的零样本泛化能力。

Q4:Real-to-Sim 重建对迁移的作用
方法:用 Gaussian Splatting 重建真实实验室场景,生成 \~4k 轨迹数据,混入仿真数据训练
结果:真实场景成功率提高 30%
结论:real-to-sim 数据能显著提升 sim-to-real 成功率,但需平衡与多样化仿真数据的比例。
Q5:与规划型方法的对比优势
EgoPlanner 在轮式平台表现好,但易在四足平台卡住
原因:四足机动延迟 + 视野受限导致地图更新质量差
NavDP:>10Hz 推理,支持 2.0 m/s 高速避障,动态场景下优于传统地图规划方法
小结
NavDP 既能预测多种可能的轨迹,又能挑出最安全的一条,让机器人在复杂环境中优雅地穿行。
它用扩散策略捕捉导航的不确定性,用 Critic 判别保证安全。NavDP 可以轻松应对不同类型的机器人——四足的、轮式的、甚至人形机器人。
无需手动调参,就能零次训练地上手实际场景。
论文一作公开分享回放链接:https://www.shenlanxueyuan.com/open/course/285

NoMad
在复杂且未知的环境中,机器人往往需要同时具备探索能力和目标导向的导航能力。传统方法通常为探索和目标导航分别训练独立策略,导致模型复杂且泛化能力有限。
第二篇我们要介绍的是伯克利团队于 ICRA2024 获得的best paper:NoMaD(Navigation with Goal Masked Diffusion)。
这个工作提出了一种全新的通用导航架构:通过统一的扩散策略,同时建模任务特定和任务无关行为,使机器人能够在未知环境中自主探索,并在获得目标信息后迅速切换到目标导向导航。
背景
机器人多任务学习能够让单一策略在不同任务或目标条件下表现多样行为。
然而,在实际场景中,机器人经常面临环境未知、任务不明确或用户指示不完整的情况。
为此,需要一种能够同时执行探索(任务无关)和目标导向(任务特定)行为的统一策略,从而在复杂环境中高效寻找目标。
架构与创新
本文提出了一种统一的策略NoMaD(Navigation with Goal Masked Diffusion)。

改策略通过 Transformer 编码视觉观测并结合扩散模型生成未来动作序列,同时支持任务特定行为(目标导向)和任务无关行为(探索)。能够高效建模多模态动作分布,实现探索与目标追踪的无缝切换。
在室内外复杂环境中的实验表明,NoMaD 在无目标和目标条件导航任务上均超越现有方法,同时计算效率提升约 15 倍,是首个成功在物理机器人上部署的目标条件动作扩散模型。
方法解析
模型由两个关键组件组成:
1. 目标掩码(Goal Masking):通过一个二值掩码控制策略是否关注目标图像,实现任务条件的灵活切换。训练时目标掩码以 50% 概率随机设置,使模型同时学习目标导向行为和探索行为;推理时根据任务需要设置掩码。
2. 扩散策略(Diffusion Policy):利用扩散模型生成多模态、无碰撞的动作序列,从随机噪声逐步迭代生成预测动作序列。动作分布既可以在无目标条件下表达探索行为,也可以在提供目标条件下收敛到目标导向行为。
训练方面
NoMaD 使用大规模多样化数据集(GNM 和 SACSoN)进行端到端监督训练。
通过将真实动作序列加噪并预测噪声的方式优化扩散网络,同时结合目标图像和时间距离预测,提升策略的多任务表现和泛化能力。

实验部分(三大核心问题)
Q1:NoMaD 与现有方法在探索和目标导航上的表现如何?
实验在 6 个复杂的室内外环境中进行,比较了 6 个基线方法,包括 VIB、Masked ViNT、Autoregressive、Random Subgoals、Subgoal Diffusion。

在探索未知环境中,NoMaD 成功率达到 98%,平均碰撞数仅 0.2,超过了最优基线 Subgoal Diffusion 约 25%,且参数量仅为其 1/15;
在已知环境的目标导航任务中,NoMaD 成功率与最优基线相当,但计算资源需求更少,实时性更好。

Q2:联合训练的任务无关与任务专属策略与独立策略相比表现如何?
将 NoMaD 的统一策略与单独训练的扩散策略(任务无关)和 ViNT(任务专属)对比。结果显示,统一策略在探索和目标导航任务上均可达到或超过独立策略表现。
联合训练能够学习共享表示和环境可操作性(affordances),单一策略即可胜任多种行为。

Q3:视觉编码器和目标掩码的选择对性能影响大吗?
研究测试了 CNN(早/晚融合)和 ViT 编码器,以及不同目标掩码策略。
结果发现 NoMaD 的 ViNT 编码器配合注意力目标掩码效果最佳,成功率 98%,碰撞数最少。
CNN 编码器表现次优,ViT 尽管容量大,但训练优化难度高,效果不理想。
视觉编码器与目标掩码策略对模型性能至关重要,直接影响任务执行效果和安全性。

小结
总的来说,NoMaD 的秘诀有三点:
目标掩码:如果想让机器人进行探索,只要把目标信息 “掩盖” 起来,它就会自主地在环境中四处移动;要是想让它朝着指定目标前进,去掉这个掩码,它就能立刻明确方向,朝着目标行动。
扩散策略:遇到分岔路口,能同时考虑多种可能的行动方向,比如向左拐或者向右拐,还能巧妙地避开障碍物。
视觉大脑:采用 ViNT 编码器来 “观察” 周围环境,能把实时的观察信息和目标信息有效结合起来,学习效率高,而且判断准确。

全篇总结
在机器人导航的世界里,传统方法常常分工明确:有的只会精确到目标,有的只会随便探索。NavDP 和 NoMaD 则更像是“双面特工”,既能定点精确,又能随机探索,效率与安全兼备。
NavDP 通用导航:能在复杂、紧凑的非结构化环境中平稳操控。它懂得“前方未动,先看路径”,用 critic 值量化安全,确保即使环境复杂也不出事故。
NoMaD 视觉导航和环境探索:它用目标掩码控制探索与目标导向行为的切换,用扩散策略预测多种可行动作,还配备强大的视觉编码器,使机器人在陌生环境中既不会迷路,也能快速锁定目标。
两者的共同点在于:既能执行明确任务,又能探索未知环境。
NavDP 通过 critic 和 ESDF 避撞,NoMaD 通过扩散策略和目标掩码避障。都是利用多任务训练和高维感知,学习共享的策略表示,提高泛化能力。
可以形象地说:NavDP 是精于“路线策略”的智者,而 NoMaD 是擅长“探索寻宝”的多面手探险家。两者结合,就是既懂方向又敢闯的机器人导航全能组合。
编辑|无意
审编|具身君
Ref
1. NavDP: Learning Sim-to-Real Navigation Diffusion Policy with Privileged Information Guidance
2. NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration
>>>现在成为星友,特享99元/年<<<

我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

商务合作扫码咨询

机器人、自动驾驶、无人机等研发硬件

关于我们:深蓝学院北京总部于2017年成立,2024年成立杭州分公司,2025年成立上海分公司。
学院课程涵盖人工智能、机器人、自动驾驶等各大领域,开设近100门线上课程。拥有多个实训基地助力教学与科研,多台科研平台硬件设备可供开展算法测试与验证。
服务专业用户数达11万+(人工智能全产业链垂直领域的高净值用户),硕博学历用户占比高达70%。已与多家头部机器人企业、头部高校建立深度合作,深度赋能教育 、企业端人才培养与匹配。
工作投稿|商务合作|转载:SL13126828869


点击❤收藏并推荐本文










