点击下方卡片,关注“具身智能之心”公众号
作者丨Zhichen Lou等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

研究背景与核心问题
随着具身智能的发展,机器人逐渐融入日常生活作为人类助手,这要求机器人能解读高层指令、感知动态环境并实时调整计划。视觉-语言模型(VLMs)因融合视觉理解与语言推理能力,成为机器人任务规划的重要方向,但其现有方法在三方面存在明显局限:
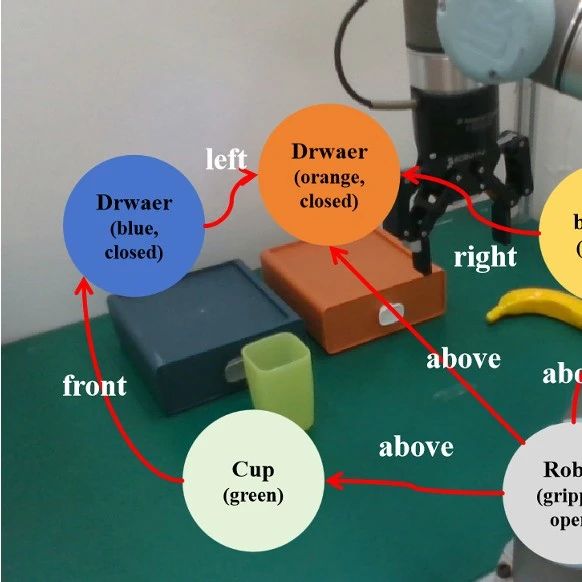
交互式探索能力不足,难以处理需要主动获取信息的场景(如确定哪个抽屉只放水果); 感知精度有限,对物体空间关系和动态变化的捕捉不够结构化; 计划适应性差,多为开环静态规划,无法基于实时反馈调整,易在复杂环境中失败(figure 1)。

为此,本文提出ExploreVLM框架,通过闭环设计整合感知、规划与执行验证,解决上述问题。
核心框架设计
ExploreVLM以“感知-规划-执行-验证”的闭环为核心,整体流程如下(figure 2):
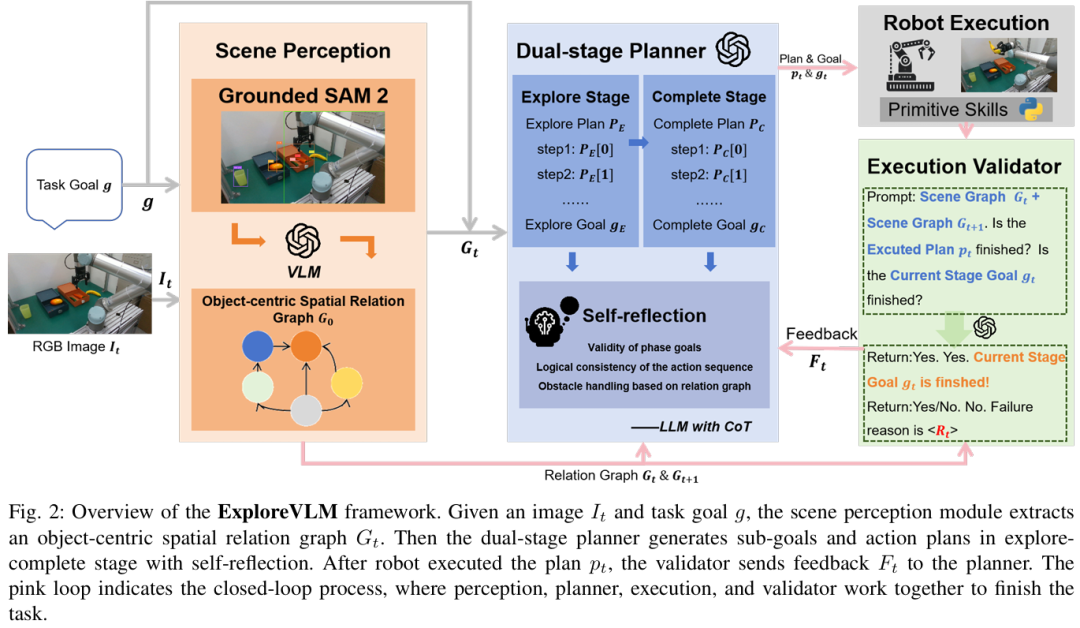
输入初始RGB图像和任务目标(如“将水果放入只装水果的抽屉”); 场景感知模块提取目标中心空间关系图,结构化描述物体类别、属性及空间关系; 双阶段规划器基于和目标,生成探索阶段()和完成阶段()的子目标与动作序列,并通过自反思优化; 机器人执行当前步骤后,执行验证器对比执行前后的和,生成反馈; 规划器基于动态调整计划,重复闭环直至任务完成。
关键模块解析
1. 目标中心空间关系图(场景感知)
传统场景感知多为零散的物体检测,难以支撑复杂推理。该模块构建结构化图表示:
节点:标注语义属性的物体(如“抽屉(蓝色,关闭)”“香蕉(黄色)”); 有向边:物体间空间关系(如“上方”“前方”“左侧”)(figure 3)。
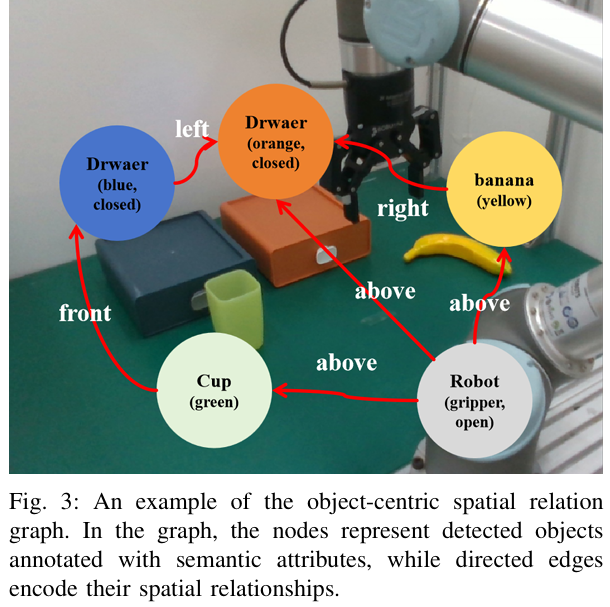
构建流程分两步:先用GroundedSAM2分割图像并标注物体类别,再结合任务指令,通过VLM推理空间关系,将2D图像转化为语言可理解的3D空间结构,为规划提供明确的“环境语法”。
2. 双阶段自反思规划器
针对任务中“未知信息探索”与“目标达成”的分离需求,设计两阶段规划:
探索阶段():当关键信息缺失时(如不确定哪个抽屉装水果),生成探索子目标(如“检查所有抽屉内容”)及对应动作(如“打开橙色抽屉”“打开蓝色抽屉”); 完成阶段():基于探索结果,生成达成最终目标的动作序列(如“将香蕉放入蓝色抽屉”)。
自反思机制通过链-of-thought(CoT)推理修正计划,解决LLM幻觉问题:
验证阶段目标有效性(如探索结果是否能支撑完成阶段); 检查动作逻辑一致性(如“抓取”需在“放置”前,“打开”需先移除前方障碍物); 处理障碍物(基于空间关系图识别前方物体,优先移开)(figure 4)。

3. 执行验证器
为避免误差累积,采用逐步验证机制:
对比执行前后的和,判断动作是否成功(如“是否真的打开了抽屉”); 验证当前子目标是否达成(如“是否确认了目标抽屉”); 若失败,返回具体原因(如“抓取失败”“存在未移除的障碍物”),触发重新规划。
该模块确保每一步反馈实时接入闭环,支撑动态调整。
实验验证
1. 实验设置
在真实机器人平台(UR5机械臂+Robotiq夹爪+Intel RealSense相机)上,设计5个递增复杂度的任务:
基础执行与反馈(Task 1:将桌上物体放入纸箱,含隐藏物体); 任务逻辑推理(Task 2:只将面包放在盘子上,需先移开茄子); 探索与识别(Task 3:找到百事可乐,需区分雪碧); 探索与常识推理(Task 4:将需冷藏的物体放入冰箱); 复杂交互(Task 5:将水果放入只装水果的抽屉,含障碍物)。
对比基线方法ReplanVLM和VILA,均使用GPT-4o作为VLM,注入50%的动作失败率以测试鲁棒性。
2. 核心结果
平均成功率:ExploreVLM达94%,远超ReplanVLM(22%)和VILA(30%)(table 1);

优势原因: 空间关系图提升场景理解精度(如准确识别Task 5中阻碍抽屉的杯子); 双阶段规划解决探索性任务困境(如Task 3中ReplanVLM陷入死循环,而ExploreVLM通过探索准确定位百事); 自反思修正逻辑错误(如避免“抓取后直接打开”的不合理序列); 逐步验证增强抗噪声能力(如及时检测抓取失败并重试)。
3. 消融实验
在最复杂的Task 5中移除核心模块后,性能大幅下降(table 2):

移除空间关系图:无法识别障碍物、误判物体(如把杯子当香蕉); 移除双阶段自反思:无法通过探索确定目标抽屉,动作逻辑混乱(如握香蕉时试图开抽屉); 移除执行验证器:失去闭环反馈,无法利用探索信息,难以从动作失败中恢复。
结果证明三模块协同是框架成功的关键。
相关工作对比
传统任务与运动规划(TAMP):侧重符号或优化规划,缺乏自然语言与视觉整合,适应性有限; 现有VLM方法: VILA:直接用GPT-4V生成计划,但缺乏结构化感知,探索与执行脱节; ReplanVLM:虽支持重规划,但依赖阶段末反馈,误差易累积; RoboExp:需依赖先验物体知识,探索步骤冗余。
ExploreVLM通过结构化感知、双阶段规划与逐步闭环,弥补了上述缺陷。
参考
[1]ExploreVLM: Closed-Loop Robot Exploration Task Planning with Vision-Language Models