本文的第一作者为北京大学王选计算机研究所博士生雷廷,通讯作者为博士生导师刘洋。团队近年来在 TPAMI、CVPR、ICCV、ICML 等顶会上有多项代表性成果发表,多次荣获多模态感知和生成竞赛冠军,和国内外知名高校、科研机构广泛开展合作。
目前的 HOI 检测方法普遍依赖视觉语言模型(VLM),但受限于图像编码器的表现,难以有效捕捉细粒度的区域级交互信息。本文介绍了一种全新的开集人类-物体交互(HOI)检测方法——交互感知提示与概念校准(INP-CC)。
为了解决这些问题,INP-CC 提出了一种动态生成交互感知提示的策略,并通过优化语言模型引导的概念校准,提升了模型对开放世界中的交互关系理解,本方法在 HICO-DET 和 SWIG-HOI 等主流数据集上取得了当前最佳性能。

论文标题: Open-Vocabulary HOI Detection with Interaction-aware Prompt and Concept Calibration
论文链接:
https://arxiv.org/pdf/2508.03207 代码链接:
https://github.com/ltttpku/INP-CC 项目主页:
https://sites.google.com/view/inp-cc/%E9%A6%96%E9%A1%B5
目前该研究已被 ICCV 2025 正式接收,相关代码与模型已全部开源。
HOI 检测进入「开放词汇」时代
在我们的日常生活中,人与物体之间的互动无处不在。然而,目前大多数研究主要集中在封闭环境下的人物交互检测,这些方法通常无法识别新的交互类型,因此在实际应用中受到限制。
近年来,多模态大模型得到了快速发展,并在开放环境中展现出巨大的应用潜力。如何将这些模型应用于开放场景中的人物交互检测,已经成为一个备受关注的研究方向。
传统的 HOI(人体-物体交互)检测方法通常依赖于固定类别的训练数据,难以应对现实中不断变化的交互组合。尽管像 CLIP 这样的视觉语言模型(VLM)为开放词汇的建模提供了新机会,但由于这些模型通常是基于图像级别的预训练,它们在捕捉人物与物体之间细微的局部交互语义时存在困难。另外,如何更有效地编码交互的文本描述,也限制了模型对复杂 HOI 关系的理解。
为了解决这些问题,研究团队提出了 INP-CC 模型,并在其中提出了两项核心创新:交互感知式提示生成(Interaction-aware Prompting)和概念校准(Concept Calibration)。
下图 1 中,展示了交互感知提示词融合机制。该机制使得模型可以在具有相似语义或功能模式的交互之间,选择性地共享提示。例如,「骑摩托车」和「骑马」这两种交互在人体和物体接触动态上非常相似,因此共享提示有助于更高效地学习这些交互的表示。
图 2 则展示了现有基于 CLIP 的方法在处理细粒度、多样化的交互类型时的局限性。例如,图中展示了「hurling」(猛掷)对应的视觉编码(用三角形表示)和「pitching」(抛投)的文本编码(用橙色圆圈表示)。可以看出,如左图所示,CLIP 模型的视觉编码和文本编码在这两者之间过于接近,导致模型难以区分它们。而与此对比,如右图所示,我们的方法通过调整语义编码空间,帮助模型有效区分视觉上相似的概念,从而更加高效地建模模态内和模态间的关系。
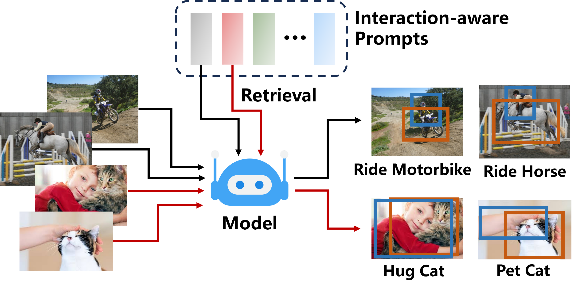
图 1 交互感知提示词融合

图 2 在 CLIP 原始空间(左侧)和我们修正后的空间(右侧)中模态内和模态间相似度。
模型架构:从「看图说话」到「聚焦交互」

图 3 INP-CC 方法框架
INP-CC 模型首先通过一个交互适应式提示生成器(图 3 灰色区域),结合输入图片特性,动态构造与场景相关的提示集合。这些提示被分为通用提示和可共享的交互提示,使得像「抱猫」和「抚摸猫」这样的相似动作可以共享同一个提示,从而提升模型对局部区域的感知能力。
在语言建模方面(图 3 浅蓝色区域),INP-CC 利用 GPT 生成各种交互的详细视觉描述,同时结合 T5 构建的 Instructor Embedding(指导嵌入)对交互语义进行嵌入和聚类,从而形成一个更细粒度的概念结构空间。这种方式帮助模型更好地理解复杂的交互语义,并将其映射到合适的语义空间中。
此外,INP-CC 在训练过程中引入了「困难负样本采样」策略,这一策略使得模型能够学会区分那些视觉上相似但语义不同的动作,例如「猛掷」和「抛投」。这一方法有效提升了模型在细粒度交互类型上的识别能力,帮助其更准确地理解和处理复杂的人物交互场景。
交互感知提示生成(Interaction-aware Prompt Generation)
为了弥合图像级预训练和细粒度区域交互检测之间的差距,INP-CC 提出了交互感知提示生成机制,通过动态生成适应不同交互模式的提示,指导视觉编码器更好地聚焦于关键的交互区域。具体来说,模型通过以下两个核心组成部分来实现这一目标:
通用提示: 该提示捕获所有交互类别共享的基本知识,适用于所有交互类型。
交互特定提示: 这些提示专门针对某些交互类型,采用低秩分解技术高效编码交互特征,从而在不增加计算负担的前提下增强模型的泛化能力。
通过将这些交互提示与通用提示结合,INP-CC 能够有效捕捉多种交互的共同特征,并通过自适应选择机制动态调整每张输入图像所需的提示,优化交互区域的聚焦能力。
交互概念校准(HOI Concept Calibration)
面对现有视觉-语言模型(VLM)在处理多样交互概念时的局限性,INP-CC 进一步引入了交互概念校准机制。该机制通过结合大规模语言模型对视觉描述进行生成与校准,提升了模型对语义细节的捕捉能力。
内模关系建模(Intra-modal Relation Modeling): INP-CC 首先为每种交互类型生成细粒度的视觉描述,并利用 T5 语言模型将这些描述转化为嵌入向量。通过这一过程,模型能够精确区分视觉上相似但语义不同的动作类别。
负类别采样(Negative Category Sampling): 为了解决视觉上相似但概念上不同的动作难以区分的问题,INP-CC 引入了基于语义相似度的负样本采样策略,在训练过程中从视觉描述相似的类别中采样负样本,帮助模型更好地分辨细粒度的动作差异。
实验表现:全面超越 SOTA
在 HICO-DET 和 SWIG-HOI 两大开放词汇 HOI 数据集上,INP-CC 在所有指标上均优于现有主流方法。其中,在 SWIG-HOI 全量测试集上取得了 16.74% 的 mAP,相较前一方法 CMD-SE 相对提升了近 10%,在「阅读」、「浏览」等细粒度交互中亦展现出较强的识别能力。

图 4 HICO-DET 实验结果

图 5 SWIG-HOI 实验结果
此外,可视化分析结果表明我们的模型表现出了强大的注意力集中能力,能够聚焦于关键的交互区域,以下是几个例子。例如,在图 6(a) 中,它准确地突出了阅读时的眼部区域。同样,在图 6(b) 中,模型强调了冲浪时人伸展的双臂。此外,我们的模型还能够检测到与相对较小物体的交互,比如在图 6(d) 中的相机和在图 6(a) 中部分遮挡的书籍。

图 6 可视化结果
总结:VLM + LLM 的深度融合路径
INP-CC 不仅打破了预训练视觉语言模型(VLM)在区域感知与概念理解上的瓶颈,还展现出将语言模型(LLM)知识引入计算机视觉任务的巨大潜力。通过构建「交互感知」与「语义修正」的双重引导机制,INP-CC 精准引导了 CLIP 的感知能力,为开放词汇场景下的 HOI 检测开辟了新路径。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com