
高质量数据是驱动大模型发展的基础。在预训练阶段,如何高效筛选出最优数据组合,正成为决定模型能力上限的关键变量。
近期,上海人工智能实验室(上海AI实验室)联合华东师范大学团队共同提出一种全新的数据筛选方法Meta-rater,首次利用小规模代理模型,在仅约为1B模型训练开销1%的成本下,预测最优数据组合,大幅提升了大模型预训练数据筛选的效率与精度,在降低算力消耗的同时显著提升了大模型训练的性价比。
Meta-rater证明了数据筛选不再是依赖大规模算力反复试错的“黑箱”工程,而是可以通过多维质量评估实现最优解。这一方法为构建『书生』科学多模态大模型Intern-S1的高质量预训练数据集提供了有力支撑。
在第63届国际计算语言学协会年会(ACL 2025)上,Meta-rater的相关研究荣获“最佳主题论文奖”。
论文链接:
https://aclanthology.org/2025.acl-long.533/
代码与数据集链接:
https://github.com/opendatalab/Meta-rater
创新多维数据选择框架,实现精准评估
Meta-rater的核心在于其多维度的评估框架。研究人员针对数据集中的每份文档,从25个维度进行打分,并创新性地引入专业性(Professionalism)、可读性(Readability)、推理能力(Reasoning)和清洁度(Cleanliness)四个评估维度,旨在更全面地评估数据的深层价值。
更为关键的是,研究团队通过训练"代理模型"构建了一套精巧的评估体系:他们随机生成数百种不同的"评分权重组合",针对每一种组合筛选出的数据子集,训练一个小规模的"代理模型"(参数规模仅18M)。通过观察这些代理模型在不同数据子集上的表现差异,研究人员建立起一个能够映射质量分数权重与模型性能的非线性关系模型。
这一方法的创新点在于,它将数据选择问题转化为回归建模问题。研究人员利用这个回归模型在庞大的权重空间中进行高效搜索,以识别出能够带来最低验证损失的最优权重组合。这种通过机器学习而非人工假设来整合不同质量维度的方法,使得Meta-rater能够自动发现最优的维度权重配置,从而显著超越传统的单一维度或简单多维度组合方法,实现更智能、更有效的预训练数据选择。
卓越的性能与计算效率,加速模型训练
Meta-rater在实证评估中展现了其强大的能力和可扩展性。实验证明,对于一个1.3B参数的模型,Meta-rater能够使其收敛速度加快一倍,并将下游任务的平均性能提高3.23%。这一优势并非仅限于小模型,在3.3B、7.2B等更大参数规模的模型上,Meta-rater的性能增益依然显著。例如,用Meta-rater训练的7.2B模型,其平均得分(55.24)比随机选择基线模型(52.12)高出3.12分。
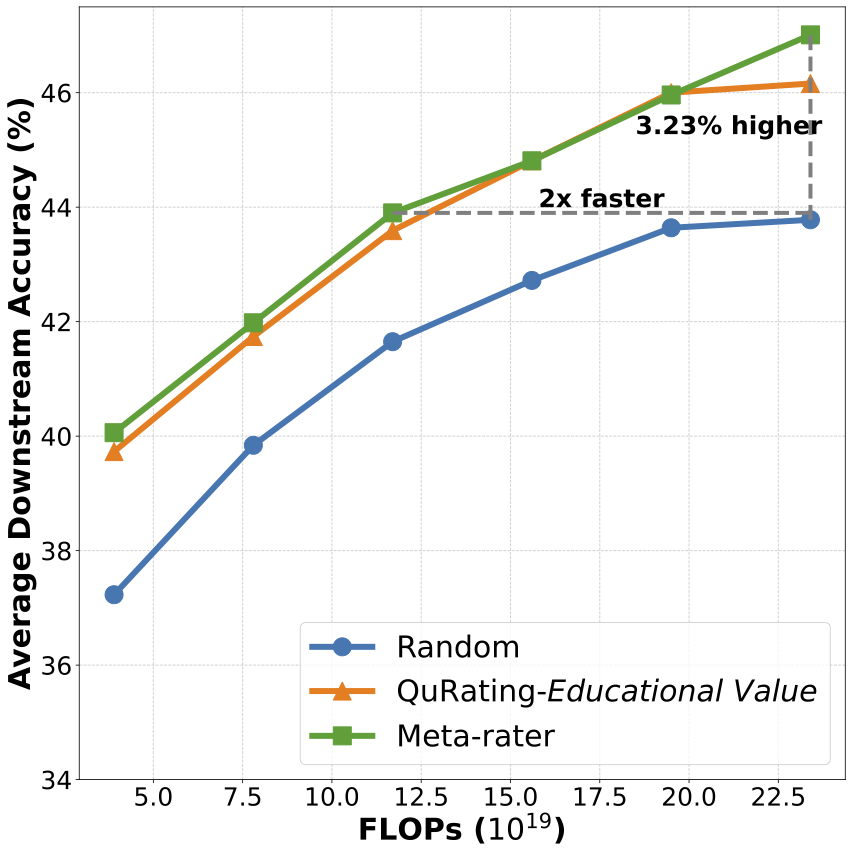
Meta-rater与随机选择基线、SOTA基线(QuRating-Educational Value)在1.3B模型预训练上的性能对比
Meta-rater也是一项具有成本效益的技术——构建该框架本身的FLOPS仅占一个1.3B模型预训练所需FLOPS的0.7%。此外,数据打标成本随着预训练规模的增大而变得越来越低,例如在预训练一个3.3B模型时,打标成本仅占总FLOPS的17%。
上述实验结果均证明了Meta-rater在提高预训练效率和模型能力方面的显著优势。
重新定义高质量数据,指导科学训练
Meta-rater优于简单的平均或交集组合策略,关键在于它能够动态地调整不同评级维度的贡献。通过对25个质量指标权重的分析,研究人员发现“教育价值”是最具影响力的指标,而“写作风格”的影响则微乎其微。这一发现证明了Meta-rater能够精准地识别和利用不同质量指标对模型性能的真实影响。

Meta-rater为每一个数据质量评估指标(rater)所分配到的权重
此外,本项研究还强调了数据领域多样性的重要价值。实验表明,将预训练数据限制在单一领域(如CommonCrawl)会导致模型在所有任务类别上的性能下降,其中在常识推理任务中的下降最为明显。这说明除了数据质量外,数据领域多样性也是构建强大LLM的重要支柱。
Meta-rater通过其多维整合的框架,为通过科学方法优化数据,从而构建更强大、更高效的人工智能应用提供了良好的技术支撑。
从实际需求出发,开展有组织的科研
Meta-rater的研发起点并非源于抽象的理论构想,而是基于服务大语言模型“书生·浦语”的实际需求。针对如何在有限的计算资源与时间条件下,从海量原始数据中精准筛选出高价值样本这一问题,研究团队突破了传统依赖人工经验或单一维度评分的局限,提出并构建了多维度融合的数据筛选框架,有效提升预训练数据的质量与利用效率。这一方法为构建『书生』科学多模态大模型Intern-S1的高质量预训练数据集也提供了有力支撑。
通过布局通专融合技术路线,并依托在AI-Ready数据领域的长期技术积累,上海AI实验室已形成覆盖从获取、清洗、再到质量评估、可视化等数据全流程体系化能力,并陆续推出OpenDataLab开放数据平台、MinerU文档智能解析工具等具有广泛影响力的开源成果。这些能力为Meta-rater的快速研发与稳定运行提供了坚实支撑,也为其跨任务、跨领域的适配推广奠定了基础。
未来,上海AI实验室将持续深化高质量数据体系建设,面向全球科研与产业需求,推动Meta-rater在多模态、多语种及专项任务等多类场景中的应用落地,助力人工智能技术高质量发展。















