机器之心编辑部
又一个真正轻量、快速、强悍的大语言模型闪亮登场!
Transformer 架构对计算和内存的巨大需求使得大模型效率的提升成为一大难题。为应对这一挑战,研究者们投入了大量精力来设计更高效的 LM 架构。
与此同时,大量工作致力于构建混合模型,将全注意力和线性注意力相结合,以在准确性和效率之间取得平衡。虽然这些模型比全注意力架构具有更高的效率,但其准确性仍明显落后于 SOTA 全注意力模型。
近日,来自英伟达的研究者提出了一种新的混合架构语言模型新系列 ——Jet-Nemotron。其在达到 SOTA 全注意力模型精度的同时,还具备卓越的效率。
具体来说,2B 版本的 Jet-Nemotron 性能就能赶超 Qwen3、Qwen2.5、Gemma3 和 Llama3.2 等最 SOTA 开源全注意力语言模型,同时实现了显著的效率提升。在 H100 GPU 上,其生成吞吐量实现了高达 53.6 倍的加速(上下文长度为 256K,最大 batch size)。
此外,在 MMLU 和 MMLU-Pro 基准上,Jet-Nemotron 的准确率也超过了近期一些先进的 MoE 全注意力模型(如 DeepSeek-V3-Small 和 Moonlight),尽管这些模型的参数规模更大。

论文标题:Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search
论文地址:https://www.arxiv.org/pdf/2508.15884
下图将 Jet-Nemotron 与之前的高效大语言模型进行了对比。

值得注意的是,Jet-Nemotron-2B 在 MMLU-Pro 上的准确率高于 Qwen3-1.7B-Base,并且在 64K 上下文长度下,在英伟达 H100 GPU 上的生成吞吐量是后者的 47 倍。
Jet-Nemotron 建立在两项核心创新之上:
后神经架构搜索 (Post Neural Architecture Search,PostNAS):一种高效的后训练架构探索与自适应 pipeline,可适用于任意预训练的 Transformer 模型。
JetBlock:一种新型的线性注意力模块,其性能显著优于 Mamba2 等先前的设计。
英伟达研究科学家 Han Cai 以及 MIT 副教授韩松都各自在推特上「安利」了这项研究,其中韩松表示「一个轻量级且可以快速运行的大语言模型来了。」


PostNAS —— 后训练架构探索与自适应
与以往从零开始训练模型、以探索新架构的方法不同,PostNAS 的思路是:在已有的预训练 Transformer 模型上,灵活尝试不同的注意力(attention)模块设计。这样不仅大大降低了开发新型大语言模型架构的成本和风险,还提高了研究效率。
当然,在这一框架下设计出的新架构,如果直接从零训练,可能并不能达到最优结果。但研究者认为,它们依然非常有价值:
立即带来收益 —— 如图 1 所示,这些架构能在现有全注意力模型的基础上,实现效率和精度的立刻提升,从而带来实际好处,例如服务质量改善和运维成本下降。
快速的创新试验场 —— 如果一个新设计在该框架下表现不佳,那么它在完整的预训练过程中成功的可能性也极低。这个「过滤机制」帮助研究人员避免在无望的架构上浪费大量算力和资源。
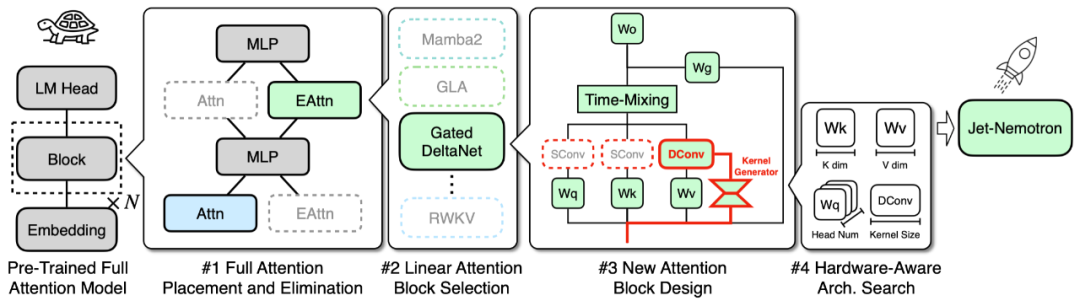
PostNAS 首先确定全注意力层的最佳位置,然后再搜索更优的注意力模块设计。
同时,研究者提出了一种自动化方法,用来高效确定全注意力层的放置位置。整体方法如下图 4 所示。通过在预训练的全注意力模型中加入可选的线性注意力路径,研究者构建了一个 once-for-all 超网络。训练练过程中的每一步都随机采样一条激活路径,从而形成一个子网络,并使用特征蒸馏损失进行训练。

训练完成后,研究者采用束搜索来确定给定约束条件下(例如仅允许 2 层全注意力层)的最优放置方式。
搜索目标与任务相关:对于 MMLU,研究者选择在正确答案上损失最低的配置(即最大化−loss);而对于数学与检索类任务,研究者则选择准确率最高的配置。如下图 5 (b) 所示,PostNAS 在精度上显著优于均匀放置策略。

在预训练的 Transformer 模型中,并非所有注意力层都具有同等贡献。PostNAS 揭示了其中最关键的注意力层。

PostNAS 精度提升分解。通过将 PostNAS 应用于基线模型,论文在所有基准测试上都取得了显著的精度提升。
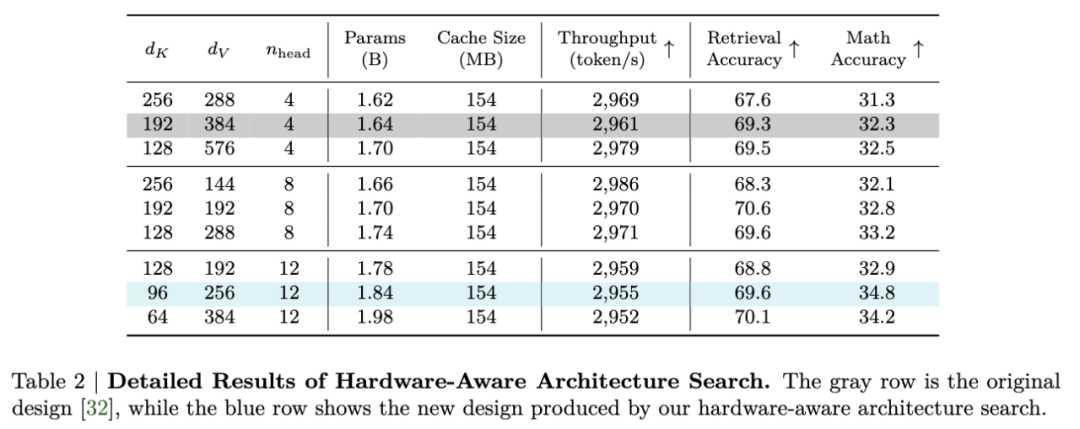
此外,KV 缓存大小是影响长上下文和长文本生成吞吐量的最关键因素。PostNAS 的硬件感知搜索能够发掘这样的架构:在保持相似生成吞吐量的同时,拥有更多参数并取得更高精度。下表 2 为硬件感知架构搜索的详细结果。
JetBlock —— 具备SOTA 精度的全新线性注意力模块
借助 PostNAS,研究者提出了 JetBlock。这是一种新颖的线性注意力模块,可以将动态卷积与硬件感知的架构搜索相结合,从而增强线性注意力。
结果显示,在保持与现有设计相近训练与推理吞吐量的同时,JetBlock 在精度上实现了显著提升。在相同训练数据与训练方案情况下,下图对 Mamba2 Block 与 JetBlock 的各性能指标(包括通用知识、数学、常识和检索)进行了比较。

主要结果如下图所示:在全面的基准测试套件中,Jet-Nemotron-2B 和 Jet-Nemotron-4B 的精度能够媲美甚至超越领先的高效语言模型(例如 Qwen3),同时运行速度显著更快,它们分别比 Qwen3-1.7B-Base 快了 21 倍和 47 倍。

更多技术细节与实验结果请参阅原论文。
参考链接:https://hanlab.mit.edu/projects/jet-nemotron

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










