点击下方卡片,关注“具身智能之心”公众号
作者丨William Chen等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
标题:Training Strategies for Efficient Embodied Reasoning
相关链接:
主页:https://ecot-lite.github.io/
paper:https://arxiv.org/pdf/2505.08243
Ecot 解读:https://zhuanlan.zhihu.com/p/1941997417248583914
Libero-90 ECoT dataset: https://huggingface.co/datasets/Embodied-CoT/embodied_features_and_demos_libero
Libero 数据集:https://github.com/Lifelong-Robot-Learning/LIBERO
Motivation:
机器人必须能够在广泛的现实场景中进行泛化一直是机器人领域的一个长期关注点。RT-X、RT-1、Octo、CrossFormer 这些都是在大量多样化机器人数据集训练的,明显提高了泛化能力。
在这种数据驱动的框架下,提升 policy 泛化能力的标准方法是收集越来越多的机器人数据集,通常通过繁琐的人类遥控操作来完成,VLA 架构的灵活性最近催生了一种替代的、可叠加的泛化改进范式:具身思维链推理(ECoT)。
受大型语言模型推理工作的启发,这些方法训练 VLA 将机器人动作预测问题分解成一系列推理步骤,比如识别物体的位置和机器人末端执行器、规划子任务或预测物体的可操作性(affordances)
有大量证据表明,训练机器人 policy 执行这些推理步骤可以显著提高其对新场景、新物体和新任务指令的泛化能力,且无需收集额外的机器人演示数据。
尽管 ECoT 是提升 policy 泛化的一个有前景的方法,但现有的机器人推理方法也伴随着显著的成本:训练数据需要附带详细的推理指令,并且在推理过程中执行扩展的推理步骤可能会显著减慢 policy 推理速度,导致单次动作预测可能需要几秒钟的时间。
那么 CoT 是如何改进 policy 性能?能否针对性设计优化方案解决上述问题?
解决办法:
假设出三种可能的机制,解释 reasoning 如何改进 policy:
更好的表征学习 改进的学习进程 增强的表达能力
然后设计了几种简单的机器人 CoT 推理变体,来隔离并测试每一种机制。
结果发现学习生成 reasoning 确实能让 VLA 表征更好,而关注这些推理有助于利用这些特征来提高 aciton 预测的准确性。
并提出了两种简单且轻量的替代性 ECoT 方法,即 ECoT-Lite。如下图
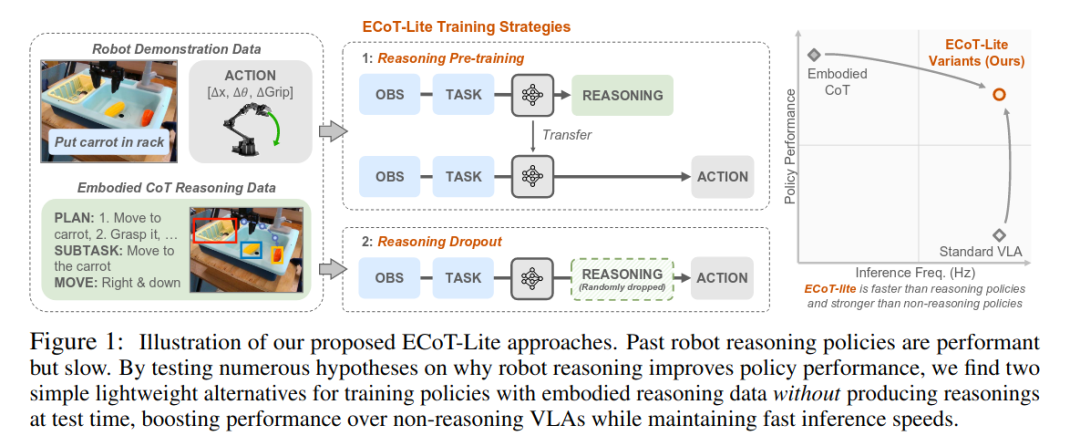
这些方法在避免了常规链式思维推理的缺点的同时,保留了大部分泛化的好处,使 ECoT-Lite 方法显著更为实用。
ECoT-Lite 在广泛使用的 LIBERO 模拟基准上取得了最先进的性能,并且在 BridgeData V2 评估中超越了最先进的传统 VLA 模型,提升了 10-19%,同时将推理速度从常规具身链式思维推理方法的 1-1.2Hz 提升至标准 VLA 的 3.5Hz 以上。
相关工作
Chain-of-thought in LLMs and VLMs
CoT 在大型语言模型(LLMs)和视觉-语言模型(VLMs)中的应用。许多研究表明,模型在给出查询的答案之前生成中间推理步骤,可以显著提高大型语言模型(LLMs)和视觉-语言模型(VLMs)的表现。直觉上,每一个中间步骤对于模型来说可能比直接生成正确答案更容易预测。 链式思维推理在涉及数学的任务中尤其成功,这种直觉在理论上是有依据的:固定大小的 transformer 架构的表现能力不足以解决诸如整数算术或动态规划等问题,但采用适当长度的链式思维推理可以使大型语言模型(LLM)解决这些问题。中间推理步骤增强了 transformer 的表达能力。
尽管现有理论分析提供了关于如何用 CoT 解决逻辑问题的洞察,但这种观点是不完整的,因为它没有解释为什么推理在常识性问题求解中(如视觉问答(VQA)或机器人)能够起作用。这与数学问题不同,因为常识问题涉及的是将碎片化的或隐含的真实世界知识连接起来,而不是在抽象符号上的逻辑推导。
本文通过研究多个假设,探讨为什么 CoT 能够促进现实世界机器人问题的解决。特别关注依赖语义推理的任务,这与基于逻辑符号的推理(数学)不同,更类似于常识性问题求解。
Robot reasoning
与标准的视觉-语言-行动模型(VLA)将观察直接映射到机器人动作不同,机器人中的 CoT 首先生成机器人的“推理”步骤,再预测最终的动作。
常见的推理步骤包括将拆解为子任务;引导机器人目标或动作的基础特征;以及与任务相关的视觉-语义特征(物体的边界框或语义关键点)。
与仅依赖动作预测进行训练相比,预测这些中间推理步骤能够改善 policy 的泛化能力,但未能剖析为什么会出现这种情况。
与大型语言模型(LLMs)不同,机器人推理在 VLA 中通常无法仅通过提示(prompt)来引导。
相反,模型需要显式地进行训练,才能生成推理步骤,这就提出了一个问题:是链式思维推理(CoT)本身,还是额外的训练信号,导致了性能的提高?
本文将通过 CoT 在训练和推理阶段的不同方面,来探讨这个问题。
Robot representation learning
许多作者建议在具身数据或基础空间推理任务上对基础模型进行预训练,因为这些预训练得到的表征可能更有利于学习控制。
论文(What makes pre-trained visual representations successful for robust manipulation)表明空间-语义理解任务(例如分割)的表征,能提升机器人策略中的视觉稳定性。
VLA 的核心动机之一是,VLM 在预训练过程中学习到的可泛化的视觉-语言表征,即使是 frezze VLM 表征也可以用于学习 policy,如果包括 reasoning 的表征,性能还会进一步提高。
然而当分析更广泛的泛化维度时,论文(A taxonomy for evaluating generalist robot policies)发现,与 VLM 训练数据联合训练并不对所有类型的泛化都具有一致的好处。
Gemini Robotics Team 通过在具身数据上训练基础 VLM,并将其微调为推理机器人 policy,连接了具身表征学习和推理。
之前的工作要么集中于表征学习,要么是针对数学问题的链式思维推理(CoT)理论分析,要么仅仅表明 CoT 能提升机器人性能。本文是首个剖析在具身机器人环境中,为什么在训练和推理时使用链式思维推理(CoT)有益的研究,探讨了表征学习和推理时计算方面的内容。
ECoT 前置知识:
也可以看更详细的内容:Ecot 解读:https://zhuanlan.zhihu.com/p/1941997417248583914
具身链式思维推理(ECoT)为本研究中的一种代表性机器人推理方法。
ECoT 对 VLA 模型做了一个简单的修改:policy 首先生成推理文本,然后再预测动作 token。
可能的推理步骤包括高层次的规划(如子任务预测)和低层次的基础特征,如动作、夹爪位置和物体边界框(见图 2,实线是 Ecot 使用,虚线类似工作是 EMMA(解读可以看https://zhuanlan.zhihu.com/p/1907010877795865672)、Cot-VLA 方案使用的)。

获取训练推理数据的典型方法是通过使用不同的基础模型来标注机器人动作轨迹。
在训练时,这些推理文本会被 token 化,并附加到动作 token 前面,模型通过 next token 预测的方式来学习生成这些推理文本(与基础 VLM 的预训练方式相同)。每个推理步骤都涉及解码推理。
为什么 ECoT 可以提高性能?
我们首先提出假设,探讨 reasoning 为何能够改善 policy 表现。利用这些假设,开发多个新颖且轻量的推理 policy 训练方法,并实证测试。
假设 1:Embodied reasoning 改善 VLA 表征学习
推理能够带来好处的一种可能解释是,通过推理步骤提供给模型的额外知识,影响了模型的表征。例如,推理轨迹可以表明某个特定物体的位置是相关的。如果改善表征是提升 policy 性能的主要原因,我们会认为,实际上在测试时生成推理步骤的重要性低于通过推理步骤中的信息来监督模型,这样它的内部表征就会关注推理步骤要求它预测的特征。
如果这个假设成立,可以设计一种方法:在训练过程中使用推理以改善表征学习,但在测试时推理简化,以保持较低的 policy 延迟。
假设 2:Embodied reasoning 提供了学习过程
另一种假设是,Embodied reasoning 特征为 policy 提供了一个 implicit learning curriculum,在这个 curriculum 中,模型可以首先学习相对简单的推理任务,例如从低级 movement primitives(动作原语) 到机器人动作的映射,然后逐步提高,最终完成完整的从观察到动作的预测任务。
因此,模型可能学到一种更加具有泛化能力的从图像到动作的映射,而不是从一开始就面临端到端的预测任务并依赖于记忆化解决方案。在大型语言模型(LLM)训练中也观察到类似的效果(论文:What do learning dynamics reveal about generalization in llm reasoning?)。
如果这个假设成立,可以设计一种训练方法:在训练时将具身推理作为“支架”使用,但在推理时完全去除,以简化并加速 policy 推理。
假设 3:Embodied reasoning 增加了模型的有效表达能力。
Embodied reasoning 扩展了 VLA 操作的 token 序列的长度。因此,模型在训练和推理过程中使用了比常规 VLA policy 更多的计算资源,从而有效地增加了它的表达能力。语言和视觉-语言建模领域的多个研究观察到,仅仅增加标记的数量,即使不添加新的信息,也能改善模型的表现。
类似地,可以设计一种简化的训练方法,通过引入额外的 token,而无需提前在数据上进行大量推理标注。
ECoT-Lite: Practical Training Recipes for Embodied Reasoning Policies
用上一节的假设设计一些简化版的 ECoT 训练方法。
目标是保留原始 ECoT 方法的大部分泛化能力,同时减少对大量数据标注或高延迟推理的需求。图 3 中提供了提出的方法的概述。
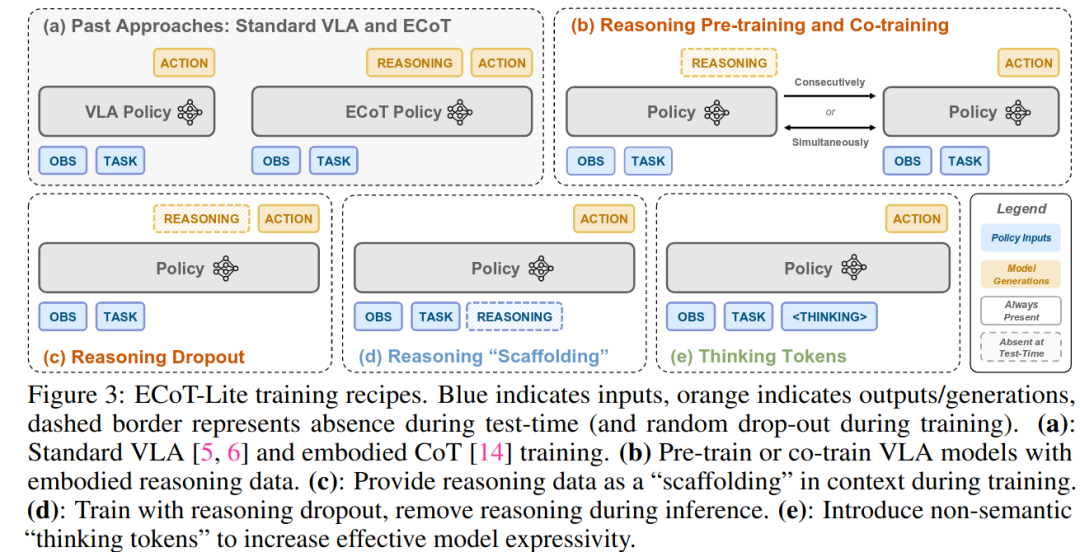
(b)Reasoning pre-training or co-training:
根据假设 1,可以通过在推理数据上进行预训练或共同训练来塑造 policy 的表征,这种方法在其他领域也常被使用。
对于预训练,基础视觉-语言模型(VLM)首先训练生成推理步骤,然后再训练生成动作。
对于共同训练,VLM 同时训练两个目标——训练数据的一半将观察映射到推理步骤,另一半则将观察映射到动作。
这将推理视为一个辅助损失。
在推理阶段,无论是预训练还是共同训练的策略,都作为标准的 VLA 模型运行,不涉及显式推理,因此具有较低的延迟。
(c)推理丢弃(dropout):
与上述方法类似,主要目标是使用具身推理数据来塑造 policy 的表征(假设 1)。这种方法训练模型明确地使用推理信息来预测动作,通过将推理和动作 token 序列化。重要的是,这种方法在推理步骤上进行丢弃处理,使得部分训练样本不包含推理信息。
这样,可以在推理时再次使用不进行推理预测的 policy,而在训练过程中明确使用推理进行动作预测,可能比简单的预训练或共同训练更能促进表征的迁移。
(d)推理“支架”
假设 2 所述,可能只想将推理作为学习过程中的支架,而不要求 policy 去学习实际的推理预测。因此在训练时提供推理示例,但不会对它们产生损失。可以再次在推理步骤上应用丢弃,使得部分训练样本不包含推理支架,即训练策略执行直接的从观察到动作的映射。在推理时,可以像使用标准 VLA 模型一样使用该策略,具有低延迟。
(e)think token
通过在训练和推理过程中引入空的“**think **token”,可以在没有语义推理的情况下增加策略的有效容量(假设 3)
通过这种方式,人为地增加了 token 序列的长度,从而增加了 VLA 可用的计算资源。在大型语言模型(LLM)训练中也探索过类似的方法
实验
测试提出的轻量化具身推理方法,与标准的 VLA 和 ECoT 推理的性能进行比较。
回答以下问题:
(1)ECoT-Lite policy 的表现与常规 VLA 和 ECoT 相比如何?
(2)第四节中的哪个假设最能通过实证结果得到支持,并解释为什么具身推理能够改善策略的泛化能力?
(3)在给定情境下,如何决定使用哪种具身推理策略?
环境与任务:
在两个环境中评估:
广泛使用的仿真 LIBERO robot manipulatio benchmark
在 VLA 和机器人推理研究中使用的 BridgeData V2 环境相似的评估任务分布。
在这两个环境中,在多样化的任务集上进行测试,要求策略能够超越训练数据进行泛化:在 LIBERO 环境中,引入了多种初始物体位置和干扰物体的随机化;在 BridgeData V2 评估中,参考 OpenVLA 方法,评估了任务分布内的泛化能力、运动泛化、空间关系和未见物体。
在这两个环境中,使用公开的 LIBERO 和 Bridge V2 训练数据集来训练 policy。关于机器人设置、数据集和任务的更多细节,请参见附录 B 或图 4 中的推理示例。在附录 C 中提供了关于如何创建具身推理标注的详细信息。

Policy training
采用两种 OpenVLA 和 MiniVLA
OpenVLA(用于真机实验)被训练生成离散化的 7 维机器人操控动作(表示笛卡尔位置变化、旋转和夹爪开/关状态),通过将每个维度均匀地分成 256 个区间来表示。
基础视觉-语言模型(VLM)是一个 7B 参数的 PrismaticVLM,使用 DINOv2 和 SigLIP 作为视觉编码器,使用 Llama2 作为其语言 backbone。在推理时,VLA 同样会自回归地生成七个动作标记,但随后 VQ-VAE 将这些标记解码成指定大小的完整动作块。
Bridge OpenVLA 策略训练了 80k 步梯度更新,batch size 为 2563,大致达到 95% 的动作标记准确率。
MiniVLA(用于大规模仿真实验)则通过将一个时域长度为 10 的 action chunk 传入一个学习的 VQ-VAE(codebook 大小为 256),将其离散化为七个 token。
VQ-VAE Action Chunking: MiniVLA 代码库支持使用 VQ-VA 对动作进行 token 化来训练策略。是一种 action chunking 变体 使用该代码训练 tokenizer,将十个 7 维的动作(共 70 个元素)转换为七个离散的 token,这些 token 从大小为 256 的 codebook 中抽取。 然后,这些 token 会被解码回原始动作块,因此 VQ-VAE 有效地提供了一个压缩的、离散化的动作序列表示。
这七个 token 就是 MiniVLApolicy 预测的内容。在推理时,自回归生成这些 token 后,它们会通过 VQ-VAE 解码器,将其转换回一个 10 步的 action chunk。 在原始 MiniVLA 论文 LIBERO 比较中显示,动作块比标准的单步动作生成更有效。然而,他们只将其视为一种表征学习方法,因为他们将动作块以“closed loop”的方式运行(生成多个动作,执行第一个动作,再生成下一个)。
然而,发现,在重新查询 VLA 之前先执行所有十个动作在所有情况下都能更好地工作(同时将 VLA 查询次数减少了十倍!),因此所有 LIBERO 实验都按照这种方式进行。
MiniVLA 使用一个较小的基础 VLM,将 Llama2 backbone 替换为 Qwen2.5,使得完整的 VLA 拥有 10 亿参数。
LIBERO MiniVLA 策略训练了 200k 步梯度更新,batch size 为 128,这大致是 VQ-VAE 动作块策略达到 85% teacher-forced 动作 token 准确率所需的时间。测试的某些 policy 经过 100k 步训练后,达到了几乎相同的性能(没有观察到过度训练的性能下降),但为了公平起见,所有报告的 LIBERO 策略都使用 200k 步训练。
使用 MiniVLA 代码库提供的默认超参数来训练时域长度为 10 的 VQ-VAE 动作块标记器,使用最终的检查点(经过 200 个 epoch)。
所有 policy 均在 8 台 A100 显卡上进行训练,除了共同训练的 LIBERO policy,它是在 8 台 H200 显卡上训练的(由于批量大小翻倍,H200 显卡需要更高的 GPU 内存,如附录 E.2 所述)。
还有其他核心 VLA 方法的变体,例如 PI0 使用 diffusion head 生成动作,或使用 OpenVLA-OFT(https://arxiv.org/pdf/2502.19645)并行化动作 token 标记。
选择的 policy 架构只是试图模仿先前在相应环境中的最先进 policy,但具身推理训练方法与底层 VLA 的选择无关,可以轻松地应用于其他 VLA 架构。
对比:
将 ECoT-Lite 训练方法与标准的(无推理的)VLA 训练,以及之前的 Ecot 进行比较。
确保所有方法都在相同的机器人演示和推理数据上进行训练,使用相同的计算资源,并在可比的初始状态、光照条件和相机角度下进行评估。
结果包含了 121,500 次模拟实验和 444 次真实机器人实验。(具身的实验做起来真的成本太高了)
ECoT-Lite 的综合实验结果
在图 5(上方)中展示了 LIBERO policy 的表现。
ECoT 和 reasoning dropout 都显著提高了在所有三个 LIBERO-90 数据集上的表现,相较于等效的标准 MiniVLA 策略。两者在标准的 LIBERO-90 数据集上均达到约 90% 的准确率,超过之前的 LIBERO-90 最先进的结果(QueST 方案)(88.6%)。
关键是,推理丢弃不生成测试时的推理步骤,因此比完整的 ECoT 要快得多。
推理预训练策略在标准 VLA 基础上带来了第二大性能提升(+5.4%),而共同训练和推理支架则带来了较小的改进。
thinking token 未能超过 baseline 表现。
由于推理丢弃和推理预训练在 LIBERO 实验中最为有效,在 Bridge 任务中验证了它们的现实应用性,如图 5(下方)所示。两种方法都显著提升了标准 VLA 基线的性能,ECoT 仍然是最优的,但 ECoT-lite 的创新方法速度提升约 3 倍。
与 LIBERO 不同,发现推理丢弃在 Bridge 任务中的效果不如推理预训练。
★太经典了,仿真和真机实验的矛盾结果,这就导致最好还是在真机验证,但是真机的验证成本的太高了。且提升微弱



表征学习(假设 1)结果分析
所有的表征学习策略都相较于无推理的 VLA 有所改进,这支持了假设 1。
发现推理共同训练仅对 baseline 性能有小幅提升(+1.9%),而推理预训练则带来了更显著的提升(+5.4%)。
Gao 等人[70]同样注意到 co-training 对动作和视觉问答(VQA)数据的混合影响。
本文结果或许更令人惊讶,因为在与动作预测任务来自同一领域的数据上进行共同训练,而 VQA 数据通常与机器人数据有很大不同。
推理预训练、推理丢弃或标准 ECoT 显著提升性能,这表明从推理数据中学习对于改善动作预测是有帮助的;co-training 似乎是一种无效的方式。
★Reasoning 数据和 action 数据联合训练效果不佳,这个本质上我认为就是多任务所需的特征不同,联合训练会导致梯度优化不一致,数据量大的时候,这个之前自驾也遇到过类似问题。但是切换成预训练又会导致过程变成冗长,拖延自驾模型迭代
为什么预训练优于 baseline 方法?
推理预训练使得模型的内部表征能够捕捉对稳定动作预测有帮助的推理特征。
相比之下,在标准 VLA 方法中调优基础 VLM 以预测动作,可能会导致生成的 policy 学习到不良的映射,因为它必须依赖从一般视觉-语言数据中学到的表征(这些数据对动作预测的适应性较差,因为缺乏机器人动作数据)。
这反过来导致了较低的性能。类似的论点常常用于适应大型语言模型(LLMs)。
为什么联合训练不如预训练?
在联合训练时,策略仍然学习生成推理步骤,因此其表征也应该得到改进。然而,关键在于,它是在同时学习推理步骤的同时,也在学习从观察到动作的映射。
我们推测,一旦推理学习促使了良好的表征,VLA 就学会了从图像到动作的糟糕映射;即,模型学习使用不同的参数来预测动作和推理步骤(几乎没有重叠)。
到了这个阶段,动作预测可能很难“切换”到基于良好的推理表征。
相比之下,通过将推理作为唯一的预训练目标,模型将所有参数都用于建模推理所需的特征;当动作微调开始时,模型必须调整用于推理的参数。
过去的研究(How to prepare your task head for finetuning)也提出了类似的论点,在附录 A.1 中进行了更详细的讨论。
A.1:
我们提供了一个(高度抽象的)可视化图示,来阐述我们关于为什么推理协同训练相对于预训练效果较差的论点,如图 7 所示。

回顾过去的 LLM 文献,在任务领域数据上进行预训练和协同训练已被实证证明可以提升模型性能。
在这些协同训练工作中,协同训练数据集通常相当庞大,而机器人具身推理数据集则不然。
如果假设成立,即协同训练导致模型在 LIBERO 上分别学习动作预测和推理,那么扩大推理数据规模(例如,引入更多具身任务或更多机器人形态)可能会强制两个任务之间更多参数共享,从而带来更好的知识迁移。
虽然不是在协同训练 vs. 预训练的语境下,但几项过去的工作已经调查了微调何时有效。
例如,虽然论文(How to prepare your task head for finetuning,)调查了如何在预训练 backbone 之上最佳初始化模型 head 的设置,但他们给出了类似的论点具体来说,他们假设如果在预训练 backbone 冻结的情况下过度调整模型 head(即调整到接近最小损失),这可能会降低下游微调和性能,这与我们的论点平行,即同时学习动作预测和推理会导致陷入低性能解决方案。
本文的论点也以一种细微的方式与论文(Fine-tuning can distort pretrained features and underperform out-of-distribution)的工作相关联。作者展示了,如果模型的预训练表示对下游任务“良好”,过度微调可能会破坏这些表示,从而降低其在分布外输入上的性能。他们发现一个有效的替代方案是仅在感兴趣的任务上微调任务特定的线性 head,从而(1)在适应时强制简单偏差,以及(2)更好地保留基础模型的表示(两者都导致更好的性能)。
将此与本文的结果联系起来,协同训练在整个训练过程中“保留”了推理表示,而推理预训练后跟动作微调则不然。
仅预训练推理的策略在大多数语义泛化任务上与完整 ECoT 相当或更好。这表明 fine-tuning 动作时对预训练特征的轻微改变不会显著影响性能,重点在于整合而非完美保留。
相反,重要的是动作预测要根植于推理表示——如果动作一开始就不强烈依赖它们,保留它们也就无关紧要。
什么时候生成 test-time reasonings 很重要?
无论是否生成测试时的推理,推理丢弃策略在 LIBERO-90 数据集上表现最好。我们怀疑这是因为 LIBERO-90 数据集较小(包含 90 个任务,而像 Bridge 或 DROID 这样的真实机器人数据集则包含数千个任务)。
因此,LIBERO 数据集中的推理步骤并不多样化;例如计划、子任务和对象标签等特征在任何给定的任务中变化较小。因此,模型很容易将推理步骤完全记住并“内化”,使得在测试时生成推理变得多余。
这一点在对更为多样化的 Bridge 数据集的评估中得到了证实,在该数据集中,启用测试时推理确实比禁用时能提高性能。
定性分析表明,这一性能差距主要来源于推理丢弃策略在选择错误对象或与障碍物碰撞时的失败模式,这些问题直观上可以通过在测试时生成边界框或运动推理来缓解(参见图 8 中的示例)。

进一步讨论:丢弃推理与完整 ECoT:
在图 8 中提供了启用推理能够带来更好性能的示例。这些示例来自于在 Bridge 评估中的运动泛化和语义泛化分割(表 2)。这些推理步骤直观地帮助机器人选择合适的行动。当推理被禁用(在推理丢弃中)或完全缺失(在标准 VLA 方案中)时,policy 往往会在这些任务中失败。
禁用 reasoning 似乎不会影响空间泛化任务(这些任务测试 policy 理解空间关系的能力,列为表 2 中的第四个 split)。猜测这是因为 Bridge 包含了大量任务标签中的左右方向引用,允许不使用推理的策略“内化”这些概念。
奇怪的是,发现推理丢弃在语义泛化任务中表现得非常好(除了到达任务)
学习进程(假设 2)结果分析
推理支架方法比基线表现略好(提高了 2.9%),与推理共同训练的效果相当。这在某种程度上支持假设 2:即使在测试时没有推理,训练过程中将推理纳入上下文也能改善学习到的观察与行动映射。
值得注意的是,这种方法与推理丢弃(reasoning dropout)方法的区别在于,后者还会对推理标记分配 loss;因此,是支架方法与学习推理的结合,带来了 LIBERO 表现的显著提升。
表达能力提升(假设 3)结果:
发现,相比于基线,增加思考标记(thinking tokens)会降低性能(平均下降 3.8%)。这与假设 3 以及语言建模中的实证结果相悖,在语言建模中,思考标记能够在多个领域提高性能。
这表明,机器人推理的主要好处不是增强策略的表达能力,而是实际学习生成语义上有意义的推理步骤。
这些实验使用的 MiniVLA 要小于其他流行的 VLA(例如 RT-2 的规模为 1B,OpenVLA 为 55B,π0 为 7B,且这些都是基于更大的模型进行的实验)。尽管如此,我们的结果仍然表明,表达能力并不是 MiniVLA 的瓶颈
哪种 Robot Reasoning 方法最适合本文要解决的问题?
如图 5 所示,当在相同的示范数据上进行训练时,标准的 VLA 在所有情况下都被 ECoT 和两种 ECoT-Lite 变体超越,这表明三者都成功地利用相同的体现推理数据集来提高策略性能。
为了确定哪个方法最合适,现在考虑它们在计算、推理和性能之间的权衡,然后提出何时使用每种方法的建议。
首先,发现 ECoT 是性能最优的方法。然而,它也是最慢的:使用 H100 GPU 上的 TensorRT-LLM FP8 编译(大部分编译速度的提升来自 FP8,它必须在 Hopper GPU 上运行(在 4090 上不支持)。还发现,TensorRT-LLM 编译对非 reasoning policy 的加速效果不大),该 policy** 的控制频率仅达到大约 1-1.2 赫兹(或者在没有编译的 4090 上为 0.3-0.5 赫兹),**相比之下,同架构的 VLAs 则能达到 3-4 赫兹(没有编译的 4090 上)。
由于两种 ECoT-Lite 变体也将观察直接映射到行动,它们共享更快的推理速度。
在这些变体中,推理丢弃(reasoning dropout)在“少任务”任务领域中似乎表现得更好,在所有 LIBERO 数据集变体上与完整的 ECoT 达到了最先进的性能(如图 5,顶部所示)。
因为推理丢弃与 ECoT 的训练方式相同(只是偶尔丢弃推理步骤),它的资源需求与 ECoT 相同,并且还为用户提供了在测试时“开启”推理步骤的灵活性。
最后,推理预训练在 Bridge 数据集上的表现优于推理丢弃,除了一个 split(如图 5,底部所示)。它的缺点是需要更多的梯度步骤来连续学习推理和行动预测(而 ECoT 和推理丢弃是同时学习的)
然而,这也意味着它不需要成对的推理步骤和行动数据。最后,由于它避免了在同一上下文窗口中对推理和 action 进行训练,因此每个训练数据点所需的内存较少,特别是在 action 以多个 token 表示时,这一点尤为显著。
我们的建议是:使用完整的 ECoT 以最大化性能,代价是推理速度较慢;在较少的任务领域中或需要在测试时“开启”推理步骤的情况下,使用推理丢弃;在更为多样化的任务领域中,或如果有未配对的体现推理数据可用(并且可以接受更多的训练步骤),使用推理预训练。
局限性:
并没有解决所有机器人推理的局限性。结果表明,policy 表达能力可能不是 VLAs 的瓶颈,thinking token 方法未能改善性能。虽然这并不令人惊讶,但这意味着为了享受机器人推理的好处,用户需要有机器人推理的训练数据,而这些数据的提取可能是困难且昂贵的。
将推理对实际模型学习动态的影响的研究留给未来的工作。这种细粒度的分析可能有助于理解为什么某些训练方案比其他方案能够更好地进行表示转移或基础建立。
最后,作为分析的一部分,保持许多设计选择(例如策略架构、训练超参数和推理语料库)不变,以使我们的比较更加可控和公平。尽管展示了 ECoT-Lite 性能提升的实证证据,但仍然可以进行进一步优化——例如,对于推理预训练,可以研究这种方法是否能够更好地支持跨本体 reasoning transfer,,这样该方法不需要成对的 reasoning-action 数据。
附录:Embodied Reasoning Datasets
按照 ECoT,训练策略预测自然语言子任务、自然语言子任务解释、物体边界框、末端执行器位置和原始动作(如“向左移动”,“向上移动”)。
对于 BridgeData V2,直接 ECoT 使用发布代码进行推理标注。
对于 Libero,使用模拟器状态(用于边界框、抓取器位置和动作)的推理标注生成过程,并采用类似 ECoT 基于 LLM 的合成数据生成 pipeline(plans, subtasks, and subtask or motion reasonings)
LIBERO-90 ECoT Pipeline and Dataset Details:
与原始 Bridge pipeline 相同,提取以下推理特征:完成整体任务的高层次子任务列表(PLAN),当前应遵循的子任务的自然语言理由(SUBTASK REASON, SUBTASK),执行何种低层语言动作(向左移动,关闭抓手等)的等效理由(MOVE REASON, MOVE),物体边界框(OBJECTS)和夹爪像素坐标(GRIPPER)。
这些大致与原始 ECoT 工作中使用的内容相同,只是在提取方式上做了一些小改动,以更好地适应 LIBERO。
首先,排除了 ECoT 使用的 TASK 步骤;因为 LIBERO-90 中的任务比 Bridge 少得多,而且评估指令总是训练期间见过的,因此我们认为这个步骤是多余的。
接下来,为了提取物体边界框和 gripper 位置,使用模拟器提供的真实分割掩码和物体名称(边界框只是每个掩码的最大和最小高度和宽度坐标,而 gripper 位置是其边界框的中心)。
最后,使用 Molmo 和 Llama2 来生成并产生子任务、子任务理由和动作理由。
这些与 ECoT 原始 pipeline 的差异导致了 LIBERO 和 Bridge 推理之间的风格差异(例如,Molmo 的合成推理更加冗长)。请参见图 12、图 13、图 14 和图 15,了解在 LIBERO 推理数据生成 pipeline 中使用的提示。
在演示数据集中的所有 3917 条轨迹上运行了这个 pipeline,为大约 90% 的轨迹生成了标签。



附录:Thinking Tokens
Thinking Tokens 理论
这种方法在生成答案之前处理一定数量的填充 Thinking Tokens,从而通过 Transformer 提高表达能力(因为这些 Tokens 现在可以支持额外的计算)。然而,这并没有改善 Transformer 的复杂度类别,Transformer 被认为属于 TC0 类(在常数时间内通过并行计算解决的问题);它仅仅在该类内增加了固定大小网络的表达能力。这与真正的链式思维推理不同,后者中 Transformer 自回归地生成不同的 Transformer。
在这种情况下,通过生成合适的长序列标记,Transformer 可以在 NC1 类(通过对数深度的并行电路来解决,意味着电路在输入规模增大时,只需要对数级别的深度,而不是线性深度。它比 TC0 类的计算能力要强,但仍然保持高效的并行计算能力)中表示计算,而这种计算无法通过直接查询 Transformer 生成答案(没有中间计算)来解决。直观地说,能够自回归地生成由适当的不同 Tokens 组成的推理,允许 Transformer“锁定”中间计算,以便所有后续计算都可以关注这些中间步骤。Feng 等人[42]讨论了整数算术的情况,其中正确的中间步骤是在 CoT 中编码长加法(从右到左加对应的数字,将进位加到下一个数字)。
相比之下,均匀的(或非均匀但低复杂度的)Thinking Tokens 序列没有这种好处。由于每个思维标记是均匀的,它们不会“锁定”前一个 Token 的计算;它们的初始嵌入不依赖于任何过去的计算,而在 CoT 中,由于该标记是自回归地生成并反馈到 Transformer 中,因此情况不同。
值得注意的是,目前尚不清楚这个论点在机器人推理等问题中适用的程度,或者在其他问题中,训练 CoT 以精确表示解决问题所需的顺序计算是不可行的。因此,虽然通过控制标记的数量来诱导 Thinking Token 和 ECoT 策略中相似的表达能力,但指出,它们并不完全相同。
Thinking Token Policies 实现细节:
为了训练 Thinking Token policy,用类似数量的 Thinking Token 替代 ECoT 中的推理。
继 VLAs 中使用罕见标记来表示模型动作的做法,选择“ .”(空格后跟句点)作为专用的 Thinking Token,因为它在训练数据中从未出现,并且直观上与我们的机器人任务没有任何语义上的关联。
实现方面,对于每个数据点,从 50 到 350 之间均匀地采样一个数字,然后将相应数量的思维标记作为提示的一部分(即不为它们分配损失)。
因此,这在功能上与标准 VLA 训练过程完全相同,只是输入提示被修改并附加了 Thinking Token – 请注意图 3 中(a)和(e)中标准 VLA 与 Thinking Token 策略的相似性。
使用的 VLA 具有仅解码器的 LLM backbone,这意味着提示和生成的 token 被视为相同(仅在训练过程中分配损失的标记不同)。
对于某些 VLA 架构(如基于 PaliGemma 的架构),情况并非如此,因为它仅对提示 token 应用非因果注意力。
在测试时,将不同数量的 Thinking Token 附加到提示中,然后是动作前缀。该策略因此只生成七个动作 token,但可以关注策略输入和所有中间 Thinking Token 的表示(从而扩展其表达能力)。











