谷歌新推出的 Gemini 2.5 Flash 模型代表了图像编辑领域的一大步飞跃。
核心亮点
在多个提示词和多张图片中保持角色的一致性。 使用自然语言进行定向编辑或替换物体。 通过单个提示词将多张图片合成为一张。 在图片内精确渲染文本。 每 100 万输出 token 定价 30 美元(1 张图片 ≈ 1290 token,约合 0.039 美元)。
可用性
您现在就可以在 Google AI Studio 上进行试用。
试用地址:https://aistudio.google.com/app
该模型已部署于 Gemini 应用及开发者平台中。可用范围覆盖 Gemini 应用、Gemini API、Google AI Studio 以及 Vertex AI。其定价为每 100 万输出 token 收费 30.00 美元,每张图片计为 1290 token,换算后约合每张图片 0.039 美元。
功能特性
拥有更佳的视觉质量、更强的指令遵循能力,以及能在编辑过程中保持人脸和物体稳定性的特性。

通过纯文本提示词即可实现定向的局部编辑。例如,移除某个人物、修复污点、模糊背景、改变姿势或为单个物体重新上色,而这一切都不会破坏画面的其余部分。

角色一致性:能够在不同镜头间保持同一个人或产品的稳定性,保留其发型、服装和标志等特征。也就是说,它可以在多张图片中维持一个角色的身份标识,即便改变其服装、姿势和场景,其核心外观也能保持不变。

创意构图:将最多三张不同图片的元素无缝融合成一个统一协调的杰作。这为超现实主义艺术和独特构图创作带来了无限可能。

多图融合功能可以将多个输入合并为一个输出,例如将一盏选定的台灯放入卧室照片中,或者用一套指定的调色板重新设计客厅风格。

模板遵循功能可以为批量生产(如房地产卡片或公司徽章)固定布局,同时替换其中的主体内容。

Gemini 融入了世界知识,这意味着该模型对日常事物有着普遍的理解。因此,它知道什么是沙发、窗户或落地灯,以及它们通常如何组合在一起。
因此,该图像模型能够读取草图或图表,理解物体的语义,并一步到位地遵循复合指令。
也就是说,它可以看懂一张粗略的草图或带有标签的布局图,并判断出哪些形状对应真实物体以及它们应该被放置在什么位置。 这减少了反复调校提示词的繁琐工作,因为模型能够直接响应像“将画面调暗两个色度,并将沙发居中放置在窗下”这样的请求。
该编辑器支持多轮对话,因此您可以通过简短的追问进行迭代式修改。
谷歌在 AI Studio 中增加了构建模式(build mode)的更新,提供了可混合搭配的模板应用,以便进行快速测试、部署或导出代码。
输出的图片带有一个不可见的 SynthID 水印,并添加了元数据标识符以供平台检测。
被禁止的用例包括未经同意的私密图像,而日常的创意编辑功能则保持可用。
像 OpenRouter 这样的合作伙伴将其覆盖范围扩大到超过 300 万开发者,而 fal.ai 则提供了另一条通往生产环境的路径。
开发者应预见到,在早期预览版中可能存在一些弱点,例如在图片上渲染长文本或处理非常精细的真实细节。
下面是一个运行它的简单代码。

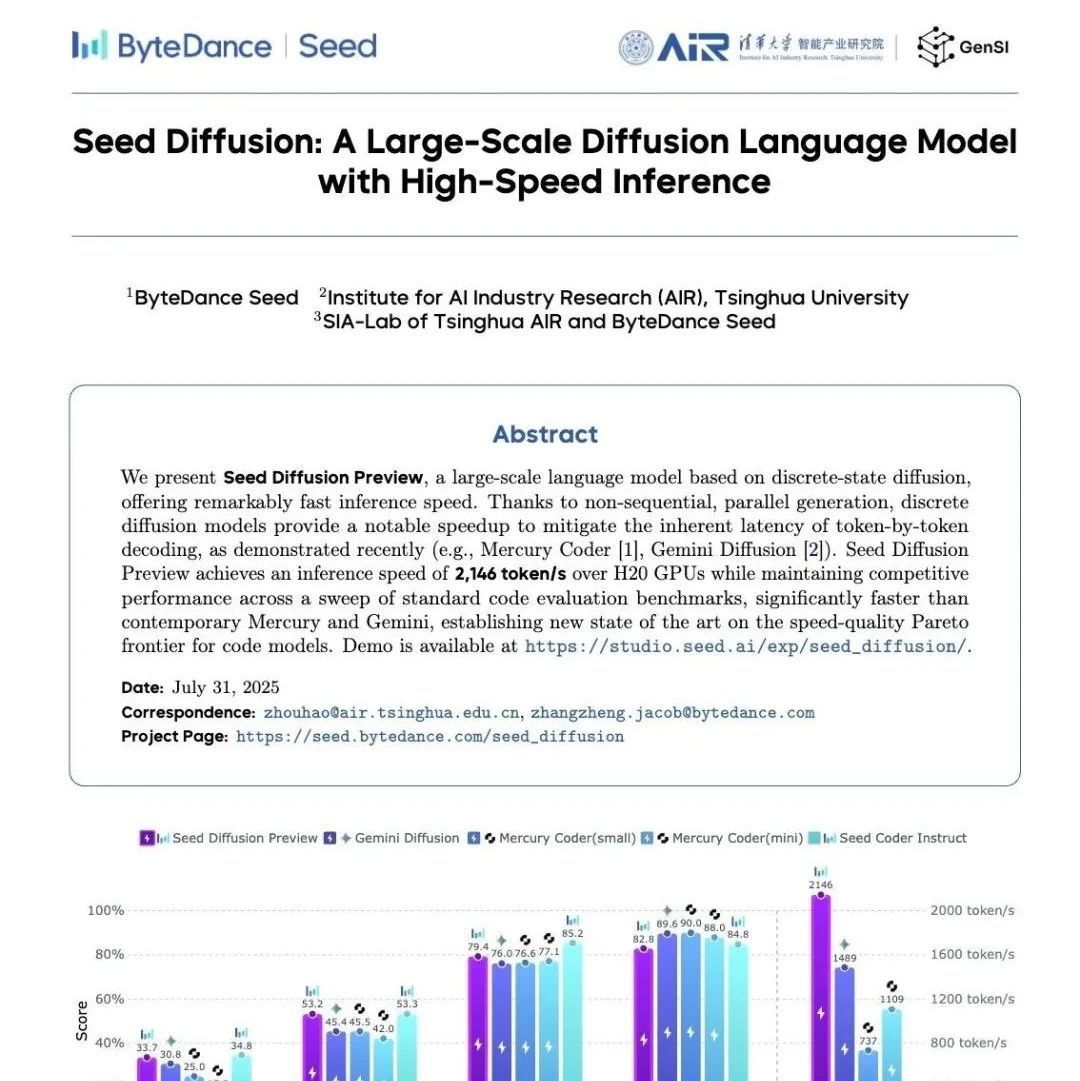
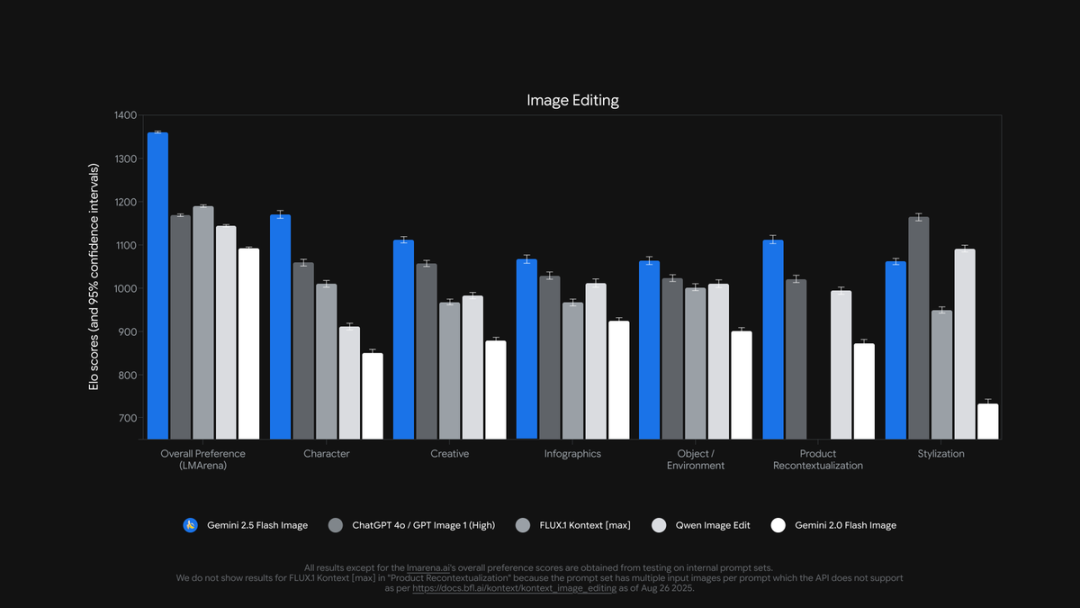
在 Artificial Analysis 图像编辑竞技场中,谷歌的 Gemini 2.5 Flash Image (Nano-Banana) 击败了 GPT-4o 和 Qwen-Image-Edit,摘得顶尖图像编辑模型的桂冠!

Gemini-2.5-Flash-Image-Preview (“nano-banana”) 在图像编辑竞技场 (Image Edit Arena) 中排名第一。

一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!