研究概要:杜克大学与 Zoom 的研究者们推出了 LiveMCP-101,这是首个专门针对真实动态环境设计的 MCP-enabled Agent 评测基准。该基准包含 101 个精心设计的任务,涵盖旅行规划,体育娱乐,软件工程等多种不同场景,要求 Agent 在多步骤、多工具协同的场景下完成任务。实验结果显示,即使是最先进的模型在该基准上的成功率仍低于 60%,揭示了当前 LLM Agent 在实际部署中面临的关键挑战。通过细粒度的失败模式分析与 Token 效率分析,研究为提升 Agent 的 MCP 工具调用能力与 token 利用效率提供了明确的改进方向。第一作者是杜克大学的博士生 Ming Yin, 导师是 Yiran Chen 教授。该工作是在 zoom 实习期间完成。

论文链接:https://arxiv.org/pdf/2508.15760
1. 研究背景与动机
MCP 的兴起:外部工具交互能力已成为 AI Agent 的核心,使其能够超越静态知识,动态地与真实世界交互。Model Context Protocol (MCP) 的出现标准化了模型与工具的集成。
现有评测的局限:当前基准多聚焦于单步工具调用、合成环境或有限工具集,无法捕捉真实场景的复杂性和动态性。在实际应用中,代理必须与可能随时间变化响应的实用工具交互,跨越完全不同的领域。
用户查询的复杂性:现实中的用户查询往往带有细致的上下文和特定约束,需要跨越多次工具调用的精确推理才能完成任务。这要求代理不仅知道使用哪个工具,还要知道何时以及如何在不断演变的任务状态中组合这些工具。
评测挑战:理解代理在现实、时间演进的生产环境中为何失败,能够为改进相应的模型和系统架构提供宝贵见解。然而,现有基准无法完全揭示当前代理系统在真实生产环境部署时的差距。
2. 基准与方法
2.1 任务集
共 101 个高质量任务,经多轮 LLM 改写与人工审校;覆盖 41 个 MCP 服务器、260 个工具;分为 Easy, Medium, Hard 三档难度,涵盖从基础工具调用到复杂多步推理的任务。


2.2 执行计划生成与验证
Reference Agent 机制:Reference Agent(参考代理)是评测框架的核心组件,它是一个专门配置用于严格遵循预定义执行计划的代理。与被测代理需要自主决策不同,Reference Agent 被明确指示按照已验证的执行计划逐步执行,仅使用计划中指定的 MCP 工具和参数。这种设计确保了在动态环境中能够产生稳定、可重现的参考结果,为公平评测提供可靠基准。
金标执行链构建:针对真实环境中工具响应随时间变化的挑战,研究团队为每个任务创建了详细的执行计划。首先使用 o3 模型基于查询和工具规范起草计划,随后结合参考代理的执行轨迹和输出,通过 LLM 辅助编辑与人工调整相结合的方式,修正逻辑错误、工具选择、参数化和数据处理错误。
严格验证流程:整个修订过程耗费约 120 PhD hours,每个任务都经过多次试验验证,人工确认正确性。最终的执行计划能够确定性地产生参考输出,工具链长度分布平均为 5.4 次调用,最长达 15 次。
2.3 创新性并行双轨评测框架
时间漂移解决方案:为解决在线服务响应随时间变化的问题,研究提出并行双执行方案:
参考代理执行:参考代理严格按照已验证的执行计划,仅使用计划中指定的 MCP 工具产生参考输出
被测代理执行:被评估代理仅接收自然语言查询和预定义的任务工具池,必须独立分析查询、选择工具、调度调用并处理中间结果
工具池挑战设计:每个任务的工具池包含所有必需工具加上额外的 MCP 工具(单任务总共 76-125 个工具),模拟真实世界的选择广度,评估工具发现和在干扰项下的选择能力。
2.4 多维度评价指标体系
双重评分机制:采用 LLM-as-judge(GPT-4.1)对被测代理的结果和执行轨迹分别评分:
结果指标:任务成功率(TSR)- 得分为 1.0 的实例比例;平均结果分(ARS)- 所有实例得分的算术平均
轨迹指标:平均轨迹分(ATS)- 评估执行轨迹的逻辑一致性、完整性和正确性
效率指标:另外,还统计了平均 Token 消耗和平均工具调用数,衡量 Agent 的资源利用效率
人类一致性验证:通过对六个代表性模型进行分层抽样的盲评实验,验证 LLM 评审的可靠性,显示与人类专家的一致性在结果评审上达到 κ > 85%,轨迹评审上达到 κ > 78%。

3. 主要发现
3.1 模型性能分层明显
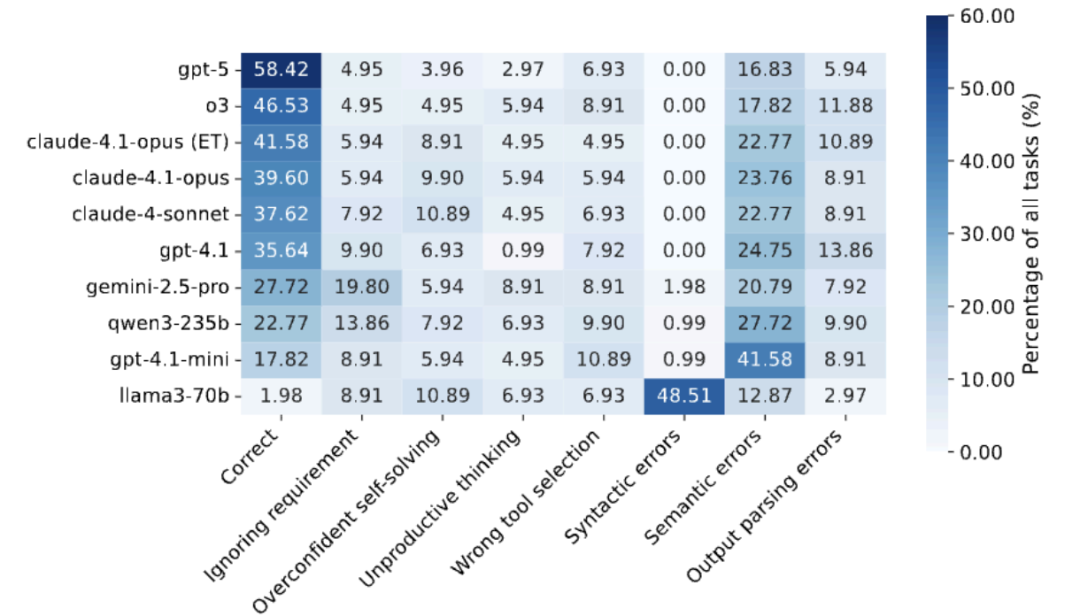
整体表现:在 18 个评测模型中,GPT-5 以 58.42% 的总体成功率领先,其次是 o3 (46.53%)、GPT-5-mini (43.56%) 和开启扩展思考的 Claude-4.1-Opus (41.58%)。这表明即使是最先进的模型,在复杂多步工具编排任务上仍有很大提升空间。
难度梯度影响:随着任务难度提升,所有模型性能显著下降。在 Easy 任务上,GPT-5 达到 86.67% 成功率,但在 Hard 任务上仅为 39.02%。这种急剧下降揭示了当前模型在处理复杂约束和长链推理时的局限性。开源与闭源差距:开源模型明显落后,最好的 Qwen3-235B-A22B 仅达到 22.77% 成功率,而 Llama 系列表现尤其不佳(Llama-3.3-70B 仅 1.98%),暴露出在 MCP 工具调用训练上的不足。

3.2 执行质量与结果的强相关性
研究发现轨迹质量(ATS)与任务成功率(TSR)和平均结果分(ARS)呈现显著正相关。这一发现强调了 "过程正确性" 对最终结果的决定性影响。
3.3 Token 效率的对数规律
闭源模型的效率曲线:研究发现闭源模型展现出独特的对数型 Token 效率模式 —— 在低 Token 预算下任务成功率快速提升,随后迅速进入平台期。这表明早期 Token 主要用于高价值操作(规划、关键工具探测、约束验证),而额外的 Token 多带来冗余(更长的解释、重复的自检)而非新的有效证据。
开源模型的效率困境:相比之下,开源模型即使使用相当或更多的 Token,成功率提升依然有限。Llama 系列倾向于过早停止探索,而部分 Qwen 模型虽然产生更长输出和更多工具调用,但未能转化为相应的性能提升。
扩展思考的价值:启用扩展思考(Extended Thinking)的 Claude 系列模型在相似 Token 预算下持续展现更好的性能,表明改进来自更好的规划和错误恢复,而非简单的输出冗长。

3.4 系统性失败模式分析
通过对执行日志的深入分析,研究识别出三大类七种具体失败模式:
工具规划与编排错误(占比最高):
忽略需求:完全错过任务中的明确要求,未调用相关工具
过度自信自解:依赖内部知识而非调用必要工具
无效循环:识别到需要工具但陷入无产出的思考循环,未调用相关工具
错误工具选择:调用了不适当的工具导致错误结果
参数错误(核心瓶颈):
语法错误(参数格式错误):在 Llama-3.3-70B-Instruct 中高达 48%,显示 MCP 特定训练的缺失
语义错误(参数内容错误):即使强模型也有 16-25% 的语义参数错误率。
输出处理错误:工具返回正确结果但在解析或转换时出错
5. 与既有工作的差异
更贴近生产实况:更大工具池与干扰工具设置,充分暴露长上下文与选择噪声下的鲁棒性问题。
更高难度与更细金标:平均 5.4 次调用(最长 15),显著区分模型层级;金标执行链包含详细参数与步骤,评分更一致、更接近人工判断。
更强诊断性:并行得到 “参考轨迹 vs. 被测轨迹”,可精确定位 “错在计划、参数还是后处理”,可以指导工程优化。
6. 总结与展望
LiveMCP-101 为评测 AI Agent 在真实动态环境中的多步工具使用能力建立了严格且可扩展的评测框架。通过 101 个涵盖多领域的精心设计任务,配合基于执行计划的创新评测方法,研究揭示了即使是最先进的大语言模型在工具编排、参数推理和 Token 效率方面仍面临重大挑战。不仅诊断了当前系统的不足,更为开发更强大的 AI Agent 指明了改进方向。
投递 0 限制:简历可多次投递,心仪岗位大胆冲!
100+ 职位,赛道超丰富,细分方向任你选!
顶级科研平台与资源:超大规模算力集群,PB 级数据,亿级研发投入! 清晰的职业发展通道:由实验室出题,为你链接顶尖高校、科研机构和行业企业!
扫描下方二维码即可投递简历。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com