点击下方卡片,关注“具身智能之心”公众号
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

传统 Vision-Language-Action(VLA)世界模型依赖 “下一帧直接预测” 范式,常因混淆静态外观与动态运动陷入 “像素复制陷阱”—— 不仅长时程预测出现机械臂消失、物体运动异常等物理失真问题,还因预训练 “被动观测知识” 与策略学习 “主动控制知识” 脱节,导致下游任务收敛慢、样本效率低。
针对这一核心痛点,FlowVLA 基于 视觉思维链(Visual CoT) 原则,在单自回归 Transformer 中实现外观与运动的统一推理:先从当前帧预测中间光流编码运动动态,再基于光流生成未来帧,通过 “帧→流→帧” 的结构化推理解耦动态与外观学习。
两阶段训练范式进一步强化性能:预训练阶段从无动作视频学通用物理规律,微调阶段适配机器人控制任务。实验显示,FlowVLA 在 LIBERO 全任务集(尤其长时程任务)、SimplerEnv 视觉偏移场景中均达 SOTA,低数据场景下样本效率优势更显著,消融实验验证 Visual CoT 结构、光流监督等设计是性能关键。

图 1:FlowVLA 两阶段训练范式概念图。
作者: Zhide Zhong, Haodong Yan, Junfeng Li, Xiangchen Liu, Xin Gong, Wenxuan Song, Jiayi Chen, and Haoang Li
单位:香港科技大学(广州)
论文标题:FlowVLA: Thinking in Motion with a Visual Chain of Thought
论文链接:https://arxiv.org/pdf/2508.18269
项目主页:https://irpn-lab.github.io/FlowVLA/
一、问题背景
1.1 VLA模型现状与价值
视觉-语言-动作(VLA)模型,尤其是以世界模型形式预训练的模型(如UniVLA、WorldVLA),在构建通用机器人领域展现出显著潜力。其主流实现方式是训练大型自回归Transformer,通过“下一帧预测”从海量视频数据中学习环境动态特征,随后将该世界模型作为基础,用于下游动作策略的微调。
1.2 现有模型核心缺陷
任务混淆导致预测失效:将物理推理与简单像素预测任务混为一谈,易陷入“像素复制陷阱”——模型仅学习复制静态背景,无法深度理解时空动态,进而导致长时程预测结果模糊、不一致且不符合物理规律,例如出现机器人臂突然消失、物体运动轨迹混乱等情况。
知识迁移存在领域差距:预训练阶段获取的“被动观测知识”,与策略学习所需的“主动控制知识”之间存在显著领域差距,导致知识迁移效率低下,下游任务需大量微调才能收敛,且收敛速度缓慢。
动态与外观学习相互纠缠:直接预测下一帧 的模式,迫使单个网络同时处理两种截然不同的任务——理解静态场景属性(如外观、纹理、光照)与建模复杂物理动态(如运动、交互、因果关系),最终造成学习效率低下。
二、主要贡献
2.1 提出新的学习框架
针对VLA世界模型中“下一帧预测”方法的根本性局限,提出视觉思维链(Visual CoT) 这一全新学习原则。该原则要求模型在预测未来帧之前,先显式推理场景的运动动态,将学习目标从单纯的模式识别转变为结构化的物理推理任务。
2.2 设计并实现FlowVLA模型
作为Visual CoT原则的首个具体实例,FlowVLA通过共享分词机制,在单个自回归Transformer中统一外观与运动推理过程。其设计无需引入专用架构组件,在保证参数效率(无需额外运动专用分词器)和架构简洁性(维持单一端到端自回归流水线)的同时,实现了对动态与外观特征的有效学习。
2.3 实验验证性能优势
通过在多个机器人操作基准测试中的实验,验证了FlowVLA的优越性:不仅在挑战性任务上实现了最先进的性能,还显著提升了样本效率,有力证明了显式运动推理在弥合“预训练-策略微调”差距方面的关键作用。
三、研究内容
3.1 核心设计:
Visual CoT推理流程:打破传统直接预测下一帧的模式,将帧预测过程分解为“当前帧→光流→未来帧”的因果推理链。即模型先预测编码运动动态的中间光流表示(),再基于该光流预测未来帧,以此引导模型解耦动态与外观学习。

图2:FlowVLA框架架构。模型遵循两阶段范式。(左)阶段1:基于视觉思维链(Visual CoT)的世界模型预训练。输入帧被编码为外观令牌(橙色),随后模型以自回归方式预测运动令牌(青色,代表光流)与未来外观令牌的交错序列。这种结构化的“当前帧→光流→未来帧”()预测过程,迫使模型在预测未来之前先对动态特征进行推理。(右)阶段2:策略微调。将预训练好的世界模型适配至控制任务,模型以文本指令(绿色)和当前观测(橙色)为条件,通过自回归方式预测动作令牌(蓝色),这些令牌经解码后可转化为机器人指令。
3.2 两阶段训练范式
3.2.1 阶段1:世界模型预训练(核心阶段)
统一分词方案:为实现外观(图像)与运动(光流)在单个模型中的统一表示,将2通道光流场转换为标准RGB类图像(运动方向映射为颜色的色相,运动速度映射为颜色的饱和度与明度,同时对光流模长进行归一化处理以保留细微运动、避免大幅运动饱和)。随后,光流图像与原始RGB帧通过完全相同的预训练VQ-GAN分词器处理,生成来自共享词汇表的令牌序列。
自回归学习目标:采用标准的“仅解码器Transformer”,以“下一个令牌预测”为目标训练模型。输入序列包含语言指令、帧令牌与光流令牌,模型需最大化该交错序列的对数似然,训练损失综合考虑光流令牌与下一帧令牌的预测误差,强制模型执行“先推理、再预测”的流程。
3.2.2 阶段2:策略微调
模型初始化与输入构造:策略模型以预训练FlowVLA的权重初始化,输入序列调整为“语言指令+视觉观测+动作”的交错结构,其中动作以令牌形式呈现。
动作处理与损失计算:参照FAST方法将机器人动作离散化为令牌,微调阶段的损失仅针对动作令牌计算,确保模型将已学到的视觉与动态知识聚焦于“做出正确动作决策”这一核心目标。
四、实验分析
4.1 实验设置
4.1.1 基准测试数据集
LIBERO数据集:作为评估多维度泛化能力的主要基准,包含四个核心任务集,分别测试模型对“ novel 空间布局”“ novel 物体”“ novel 任务目标”及“长时程组合任务”的适应能力,采用标准行为克隆设置。
SimplerEnv数据集:用于评估模型对视觉领域偏移的鲁棒性,通过引入光照、纹理、相机视角等多样化变化模拟真实世界复杂度,重点测试策略迁移能力。
4.1.2 模型与训练细节
模型基础:基于85亿参数的Emu3和UniVLA架构构建,核心改进是加入通过RAFT方法预计算的光流作为额外输入以表示运动特征。
训练参数:针对不同基准采用差异化设置,LIBERO数据集上,世界模型预训练5000步(批次大小16)、策略微调5000步(批次大小96);SimplerEnv数据集上,世界模型预训练12000步(批次大小32)、策略微调20000步(批次大小128)。
4.2 核心实验结果(围绕四大关键问题验证)
4.2.1 性能优越性验证(Q1:是否达最先进性能)
LIBERO数据集结果:FlowVLA在所有四个任务集中均持续优于现有方法,尤其在“长时程任务”上性能提升最为显著,凸显其对物理动态的稳健理解在长时程规划中的优势。
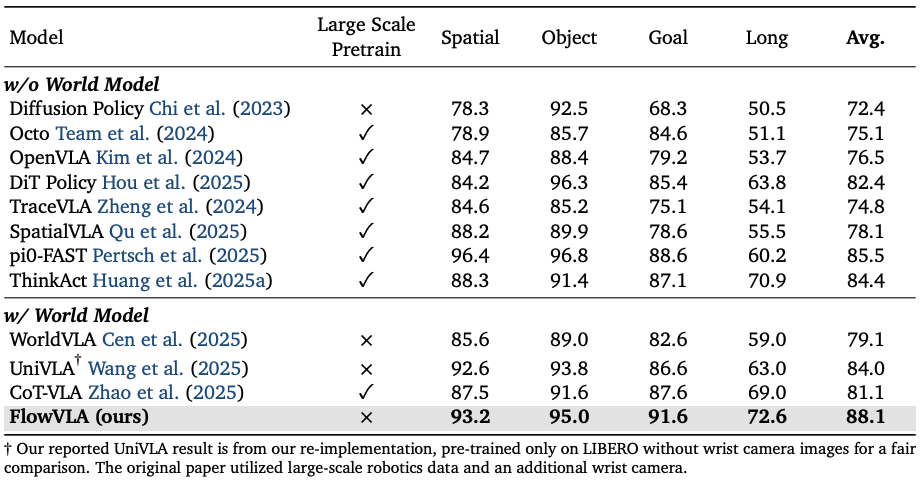
图3:LIBERO基准测试结果(最终的任务成功率(%))。将 FlowVLA 与当前最先进的方法进行对比,并按这些方法的核心方法论对其进行分组。重点对比对象是 “带世界模型(w/ World Model)” 组别,在该组别中,基于视觉思维链(Visual CoT)的预训练方法展现出了更优异的性能。
SimplerEnv数据集结果:面对显著的视觉领域偏移,FlowVLA仍实现大幅性能提升,在“堆叠积木”等其他模型表现不佳的任务上依旧出色,验证了其对真实环境中视觉与物理变化的强适应性。

图4:SimplerEnv-WidowX 基准测试(最终的任务成功率(%))。FlowVLA 显著优于以往的方法,展现出对该基准测试中存在的视觉领域偏移更强的稳健性。
4.2.2 世界模型能力验证(Q2:显式运动推理是否提升世界模型性能)
在真实世界Bridge V2数据集上的定性分析显示: 传统基线模型存在两大失效模式:一是物理合理性缺失(如机器人臂消失、物体运动不连续),二是语义不一致(预测动作与语言指令脱节)。

图 5:Bridge V2 基准测试中的物理合理性分析。重点展示了基准模型中常见的物理合理性失效问题。在两个示例中,基准模型(中间行)难以维持物理一致性,从而导致不合理的结果,例如机械臂消失或物体运动异常。与之相反,FlowVLA( bottom 行)在 “运动优先” 推理机制的引导下,生成了稳定且符合物理规律的预测结果,能够准确反映场景的动态变化。
FlowVLA通过先推理光流的显式运动推理,生成的预测结果既符合物理规律,又能与任务指令在语义上保持对齐,充分证明其世界模型的稳健性与泛化能力。

图 6:Bridge V2 基准测试中的语义对齐分析。该图展示了基准模型在 “预测结果与语言指令对齐” 方面的失效问题。尽管基准模型(中间行)生成的预测帧初看之下在视觉上似乎合理,但其所呈现的运动却与指定任务不相符(例如,将物体向错误方向移动)。与之形成对比的是,FlowVLA(下方行)再次展现出更优异的性能:它能正确理解语言指令,并生成与之对应的视觉轨迹。这一结果凸显了我们提出的视觉思维链(Visual CoT)不仅提升了预测结果的物理真实性,还增强了模型将语言与动作关联起来的能力。
4.2.3 样本效率验证(Q3:是否提升策略微调样本效率)
全数据场景:FlowVLA样本效率远超基线模型,仅用1/3的训练步数就达到基线的峰值性能,且最终成功率更高。
低数据场景:性能差距进一步扩大,FlowVLA的峰值成功率比基线高55%,且仅用1000步就超越基线的峰值性能,验证了显式运动推理带来的强大归纳偏置,使其在数据有限时仍能高效学习。

图 7:全数据与低数据场景下的训练效率对比。该图展示了 FlowVLA 与基准模型的 “成功率 - 训练步数” 关系。无论是在全数据集场景(图 a)还是数据稀缺场景(图 b)中,所提方法(FlowVLA)收敛速度都显著更快,且能达到更高的峰值性能。在数据有限的情况下,两者的性能差距大幅扩大,这凸显了该方法在样本效率方面的优越性。
4.2.4 关键组件有效性验证(Q4:哪些设计组件最关键)
在LIBERO-10基准上的消融实验结果如下:
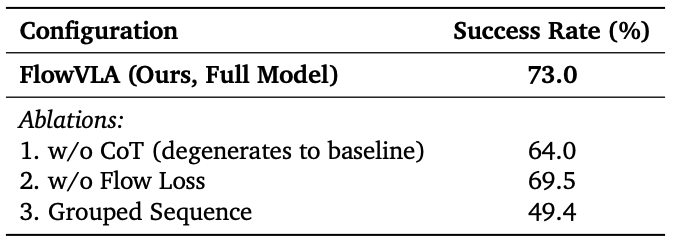
图8:LIBERO-10 基准测试的消融实验结果。针对关键设计选择的重要性展开评估,这些设计包括视觉思维链(Visual CoT)结构、光流监督损失以及交错序列格式。
4.3 相关工作对比
与传统VLA模型对比:传统VLA模型多将环境动态视为“黑箱”,以端到端方式直接学习“视觉-动作”映射;FlowVLA则以“动态优先”为理念,先构建稳健的世界模型理解环境物理规律,再适配控制任务,奠定更扎实的物理知识基础。
与其他世界模型对比:其他世界模型多采用直接预测下一帧的模式,导致动态与外观学习纠缠;FlowVLA通过Visual CoT解耦两者,避免学习低效与物理失真问题。
与具身推理方法对比:现有具身推理多聚焦高层语义推理(如生成文本子目标)或中层几何推理(如生成深度图);FlowVLA则专注于低层物理推理(像素级光流预测),提供通用、任务无关的世界动态理解,可作为高层控制的基础。
五、结论
原则有效性:提出的视觉思维链(Visual CoT)原则有效解决了传统VLA世界模型“下一帧预测”的局限,通过“先推理运动、后预测外观”的流程,将世界模型学习转变为结构化物理推理,为相关研究提供新方向。
模型价值:FlowVLA作为Visual CoT的首个实例,在单个自回归Transformer中实现了外观与运动推理的统一,既能生成符合物理规律的视觉预测,又能支持高效的策略学习,兼顾性能与架构简洁性。
实践意义:实验充分验证了FlowVLA在机器人操作任务中的领先性能与高样本效率,证明显式运动推理是弥合“感知-控制”差距的关键,为VLA模型的发展提供了更具原则性的理论与实践基础。











