点击下方卡片,关注“具身智能之心”公众号
作者丨Xiaofeng Han等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

想象这样一个场景:你让机器人在陌生的仓库里完成任务,“找到蓝色货箱,把它搬到出口处”。这意味着机器人不仅要识别货箱的位置,还要在光照复杂、物体遮挡、路径拥挤的环境中,实时规划路线并执行动作。过去的机器人往往依赖单一传感器(例如摄像头),一旦遇到光照变化或遮挡,就容易“失明”;而即便多加几个传感器,也常常因为信息割裂、缺乏统一融合而难以真正理解环境,更别说听懂人类的自然语言指令。
如今,多模态融合(Multimodal Fusion) 和 视觉语言模型(Vision-Language Models, VLMs) 正在改变这一切。多模态融合能整合 RGB 图像、深度信息、LiDAR 点云、语言、甚至触觉与位置信息,从而让机器人拥有更全面的“感知力”;而大型预训练 VLMs 则让机器人具备了跨模态对齐与语义理解能力,能够把“看见的”与“听到的”结合起来,转化为任务执行的逻辑。换句话说,它们正在让机器人从“单一感官的机械执行者”,进化为“具备理解力的智能伙伴”。
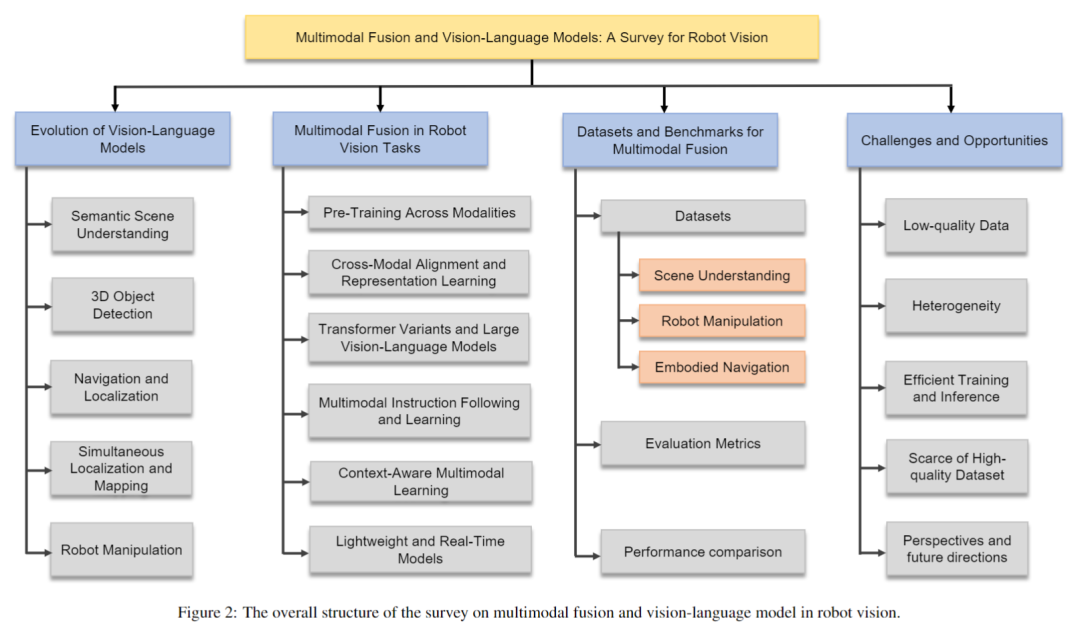
这篇综述《Multimodal Fusion and Vision-Language Models for Robot Vision》,由自动化所三维可视计算团队撰写,已被国际顶刊 Information Fusion正式接收。文章全面梳理了 VLM 与多模态融合在机器人视觉中的应用:从语义场景理解、三维目标检测,到 SLAM、具身导航和操作控制。同时,作者比较了传统方法与新兴大模型方法的优缺点,分析了相关数据集与基准测试,并提出未来的发展方向——包括跨模态自监督学习、轻量化融合架构、Transformer 驱动的统一范式,以及真实环境中的高效部署策略。
如果你想理解机器人如何突破感知与理解的局限,如何在复杂环境中实现更自主、更高效的交互,这篇综述无疑是一份值得深入研读的“领域地图”。
作者: Xiaofeng Han, Shunpeng Chen, Zenghuang Fu, Zhe Feng,Lue Fan,Dong An,Changwei Wang,Li Guo, Weiliang Meng, Xiaopeng Zhang,Rongtao Xu,Shibiao Xu
单位:中科院自动化所三维可视计算团队,北京邮电大学,山东省科学院
论文标题:Multimodal Fusion and Vision-Language Models: A Survey for Robot Vision
论文链接:https://arxiv.org/pdf/2504.02477v2
项目地址:https://github.com/Xiaofeng-Han-Res/MF-RV
作者知乎:https://www.zhihu.com/people/fengzhe_love

贡献
系统整合了传统多模态方法与新兴 VLM,从架构、功能、应用三个维度展开比较,揭示它们的互补性和融合潜力; 不同于以往只关注语义分割或目标检测的综述,我们还扩展到多模态 SLAM、机器人操作、具身导航等新兴任务,展示其在复杂推理和长时任务中的应用潜力; 总结了多模态系统相比单模态的优势,比如感知更鲁棒、语义更丰富、跨模态对齐更自然、推理层级更高,突出了它在动态、不确定或部分可观测环境中的实际价值; 深入分析当前主流的机器人多模态数据集,涵盖模态组合、任务覆盖、适用场景与局限,为未来基准构建和模型评测提供参考; 识别关键挑战,包括跨模态对齐技术、高效训练策略和实时性能优化,并据此提出面向未来的研究方向。
多模态融合在机器人视觉任务中的应用
语义场景理解:让机器人“看懂世界”
语义场景理解是视觉系统里的“硬核任务”,涉及物体识别、语义分割和关系建模。但如果只靠 RGB 图像,在复杂环境下就容易“翻车”:光照变化、物体遮挡、多目标重叠……哪一个都可能让模型瞬间迷路。于是,多模态融合就成了“救命稻草”,通过引入深度、LiDAR、语言等额外信息,大幅提升了场景理解的准确性和鲁棒性。
目前主流的融合策略主要分三类:
早期融合:在输入层直接拼接多模态数据,结构简单,但非常怕噪声,稍不小心就“乱套”; 中期融合:在特征层进行交互,常用注意力机制、GNN等方法,既保持模态独立,又能聪明地建模跨模态关系; 后期融合:各模态先“各干各的”,再整合决策,优点是扩展性强,想加新模态时不用“推倒重来”。
随着深度网络的发展,融合方式也在升级,从“显式拼接”走向了“隐式协作”。现代多模态模型往往在统一架构中同时完成特征提取、模态交互和任务预测,不仅减少了阶段设计的麻烦,还让不同模态之间的信息交换更加顺畅。
当前主流实现路径主要有三大类:
编码器-解码器架构(如 DeepLabv3+、HRNet),适合处理复杂多模态任务; 基于注意力的 Transformer(如 MRFTrans、DefFusion),善于建模长程跨模态依赖; 图神经网络(GNN)方法(如 MISSIONGNN、VQA-GNN),通过图结构捕捉模态之间更细腻的语义关系。
总的来看,这些方法正在一起努力,目标只有一个:让机器人在真实环境中看得更清、想得更深、少走弯路。毕竟,谁也不想让机器人一出门就迷路,对吧?
3D 目标检测

在自动驾驶系统中,3D 目标检测几乎可以算是最关键的感知任务之一。它的目标很直接:让车辆准确识别并定位周围的行人、车辆和障碍物,从而为后续的路径规划和决策提供可靠支持。常见的传感器包括相机、LiDAR、雷达和超声波。单一传感器各有短板:相机能捕捉丰富的纹理和颜色,但缺乏深度信息;LiDAR 提供精准的空间几何结构,却“看不懂”语义和纹理。把它们结合起来?优势互补,效果立竿见影,系统对环境的理解能力会显著提升。
三个核心问题:什么时候、融合什么、怎么融合?
在多模态融合的设计中,有三个绕不开的问题:When to fuse(何时融合)、What to fuse(融合什么)、How to fuse(如何融合)。
什么时候融合: 早期融合:在原始数据层面就直接拼接,例如把图像与点云直接“叠”在一起; 中期融合:先分别提取模态特征,再在特征空间中交互; 后期融合:各模态各算各的,最后再在决策层汇总结果。 融合什么: 相机数据可以是特征图、注意力图、伪点云等;LiDAR 数据可以是原始点云、体素化表示,或者是鸟瞰视图(BEV)。不同选择会直接影响融合的效果和计算开销。 怎么融合: 从最初的非注意力型方法(简单拼接、加权平均)到如今基于注意力的跨模态交互,方法论已经发生质变。Transformer 和跨模态注意力的引入,让模型学会了“有选择性”地关注不同模态中最有价值的特征,而不是一股脑儿地全收。
相机 vs LiDAR:互补才是正解
相机单模态方法通过 2D 图像去推理 3D 结构,优势是语义丰富、视觉直观,但一旦遇到遮挡、极端光照或雨雪天气,表现会明显下滑。LiDAR 单模态方法则完全反过来:三维几何结构拿捏得死死的,但在远距离或低反射物体上点云会很稀疏,而且缺少语义区分能力。
所以这几年,LiDAR 和相机的多模态融合逐渐成了主流方向。说白了,就是让模型既能“看到”世界的样子,又能“摸清”世界的形状。
方法演进:从简单拼接到智能交互
从最早的 MV3D、AVOD 到近年来的 TransFusion、BEVFusion 和 GAFusion,这条技术演进路线很清晰:
早期方法依赖直接拼接或统计操作,简单粗暴但效果有限; 随着深度学习的发展,逐渐演化出更复杂的点级、体素级、区域级融合策略; 直到 Transformer 的引入,多模态交互被彻底“点满”,模型终于学会了在不同模态中“挑肥拣瘦”,适应复杂环境的能力大幅提升。
一些代表性方法:
PointPainting:先对图像做语义分割,再把结果“涂”到点云上,给稀疏点云补上语义信息; TransFusion:用 Transformer 解码器建模跨模态依赖,在点云稀疏的场景下依然能保持高精度检测。
换句话说,这波进化就是从“硬拼”到“会聊”,信息交互越来越聪明。
融合更多模态:雷达和 4D 雷达的加入
除了 LiDAR+相机的组合,研究者还在探索雷达-相机和雷达-LiDAR的融合。雷达的优势在于可以直接测量速度,而且在雨雪雾等恶劣天气中依然表现稳定。比如 CenterFusion 就通过引入雷达信息,显著提升了动态环境下的检测性能。
随着 4D 雷达的发展,模型甚至可以同时获取三维空间位置和目标速度,大幅增强对动态物体的感知能力。与此同时,跨注意力机制和自监督融合方法也在不断被引入,以进一步提升精度和泛化性。

具身导航
具身导航的核心思想,是让机器人像“真的身处环境中一样”去探索、感知和行动,而不是只依赖预定义地图或单一传感器。换句话说,它不仅关注“怎么走”,还关注“为什么走”,强调在真实环境中自主决策与动态适应的能力。
在现有研究中,具身导航主要可以分为三类代表性方法:目标导向导航、指令跟随导航 和 基于对话的导航。这三类方法可以看作是从“感知驱动”到“语言理解”再到“交互感知”的逐步演进。

目标导向导航
这是最直观、最基础的一类方法。机器人接收一个明确的目标,例如“去找到椅子”,然后依赖视觉语义和空间先验知识,完成以下几个关键步骤:
自主感知周围环境 建立空间表示 规划合理路径 执行动作直到到达目标
这一类方法在 Habitat 平台上的 ObjectNav 等任务中得到了广泛验证。研究结果表明,机器人可以在没有先验地图的情况下,基于视觉和语义信息,在未知环境中完成目标检索和导航。这类任务通常考验感知能力与空间推理能力的结合,是具身导航的基础。
指令跟随导航
相比单纯的目标导向,这一类方法进一步引入了自然语言理解。机器人不仅要“看到环境”,还需要“听懂人类说什么”,并将语言信息与视觉感知结合起来。
例如,当机器人接收到“走到厨房左边的桌子”这样的指令时,它需要同时完成以下两件事:
视觉层面:识别出厨房、桌子等语义实体; 语言层面:理解“左边”的空间约束,并结合视觉地图执行。
近年来,研究者提出了不少具有代表性的系统:
InstructNav:通过多源价值映射(multi-source value mapping),实现了跨任务的零样本规划,能在没有特定训练的情况下适应新任务。 NaVid:利用视频驱动的视觉-语言模型,在室内与室外导航任务中均表现出更强的泛化能力。
这一类方法的核心突破在于让机器人不仅“看得见”,还“听得懂”,极大拓展了机器人在复杂环境中的交互和适应能力。
基于对话的导航
在这类方法中,机器人不再是被动执行命令,而是能够主动发问、实时交互,从而显著提升任务的灵活性。
例如,当机器人接到模糊的指令“去那个房间”时,它不会盲目行动,而是可以主动追问:“是指有沙发的房间吗?”在拿到更明确的信息后,机器人会动态调整路径,并在执行过程中不断修正错误。
这种交互式导航范式让机器人在不确定环境中拥有更高的适应性,特别适合长时序、多步骤的复杂任务。它不仅需要多模态融合(视觉、语言、空间),还要求系统具备在线推理与自我校正的能力。
视觉定位
如果说导航是回答“怎么去”,那视觉定位的任务就是先搞清楚“我在哪”。这个问题看似简单,其实在机器人系统里是个大难题。特别是在光照变化、遮挡严重、环境动态频繁的现实场景中,光靠一个传感器——比如相机或者 IMU(惯性单元)——往往会力不从心。
好在近年来深度学习带来的多模态融合思路,实实在在把这个老问题往前推进了一大步。比如 DeepVO 和 D3VO 这类方法,把卷积网络(提特征)和循环网络(建时间关系)结合起来,实现了端到端的自运动估计和深度估计。这些方法在标注丰富的数据集上表现不错,但也暴露出另一个问题:数据哪里来?
于是,自监督学习成了救场英雄。它不靠人工标注,而是通过光度一致性和几何一致性这些物理约束进行学习。换句话说,它让模型“自己悟”,效果还真不差。
更进一步的工作开始尝试将传统几何建模和深度神经网络混合使用,试图解决视觉里程计常见的尺度歧义和累积漂移问题。比如 D3VO 就引入了不确定性估计机制,让系统在面对动态物体或遮挡时不再那么“慌”。
而更激进的路线则直接采用神经隐式表示,比如火出圈的 NeRF,以及带语义扩展的 Semantic-NeRF。这类方法的目标很明确:把整个场景的几何和语义信息压缩进一个神经网络,让机器人哪怕是在完全陌生的环境中也能靠“记忆”来定位,听起来有点像把地图装进了大脑。
同步定位与建图
SLAM(Simultaneous Localization and Mapping)算是机器人视觉中的“老牌任务”了。自 1986 年提出以来,它一直是机器人自主探索的基石:一边在未知环境中“打怪升级”,一边绘制地图,同时还得精确知道自己在哪。简单说,就是让机器人边走边画,还得画得准、走得稳。
传统 SLAM 主要分两大阵营:
基于 LiDAR:测距精准、稳定性高,但缺乏语义,远距离点云还容易稀疏; 基于视觉(V-SLAM):通过相机提取与跟踪特征点,语义丰富,但在低光、无纹理或强遮挡环境下很容易“掉链子”。
说白了,LiDAR“看得准”,相机“看得懂”,但两者各自“看不全”。
为了弥补单一模态的不足,多模态 SLAM 顺势登场。通过融合 LiDAR、相机、IMU、GPS、雷达等多源信息,系统变得更稳、更聪明、更适应环境变化。
一些代表性工作:
V-LOAM:最早把视觉与 LiDAR“绑”在一起,利用几何与纹理的互补性,大幅提升精度。 LIMO:引入 IMU,让系统在动态场景下依然稳定。 LIC-Fusion & LIC-Fusion 2.0:通过紧耦合优化框架深度整合多源数据,在大规模场景中兼顾高精度与实时性。
换句话说,SLAM 终于从“单打独斗”变成了“抱团取暖”。
近年来,SLAM 也迎来了“神经化”浪潮。Transformer 等深度学习技术被引入,用来建模时序关系与跨模态依赖:
UVIO:用 Transformer 主干联合建模视觉和 IMU,大幅提升动态场景下的位姿估计。 RD-VIO:融合雷达信息,在恶劣天气中依然稳如老狗。 ConceptFusion:更“激进”,把视觉、语言、音频等模态融合,迈向了语义级理解。
这意味着 SLAM 系统不只是“知道我在哪”,还开始能理解“我周围有什么”,甚至“我应该怎么走”。
整体来看,SLAM 正在从“几何驱动”向“语义驱动”演进。未来的发展方向很可能是:
多模态轻量化:在保证精度的同时降低计算开销,让 SLAM 跑得起、飞得快。 自监督与大模型结合:减少对昂贵标注数据的依赖,提升泛化能力。 感知与决策一体化:不只是定位和建图,还能进行高层语义理解,辅助路径规划和任务执行。
视觉-语言-动作模型
在机器人操作任务中,多模态特征融合几乎是从“能看见”到“会行动”的关键一环。视觉-语言-动作(VLA)模型正是为此而生:它结合视觉感知、语言理解和动作规划,让机器人在面对复杂任务时,不再只是被动感知,而是能基于多源信息主动决策和执行。
VLA 的核心:模态互补 + 动作生成
VLA 模型的核心思路很直接:
从视觉模态中获取世界状态:物体的位置、形状、姿态和布局; 通过语言模态理解任务语义:解析自然语言指令,将“人话”翻译成“机器人能懂的话”; 将多模态信息融合到统一表示,再一步映射成具体的动作序列。
一些代表性方法:
RT-2:通过大规模预训练把视觉和语言表示对齐,让机器人能直接把自然语言指令翻译成低层控制命令。 RoboMamba:在融合框架中显式引入动作动态建模,提升操作规划的合理性。 3D-VLA:结合三维点云与深度图,让视觉表征更丰富,从而在语言指导下实现更精准、更鲁棒的操作。
一句话总结:视觉让机器人“看得见”,语言让它“听得懂”,而 VLA 则让它“动得准”。
高效化与智能化:让 VLA 更轻、更快、更聪明
VLA 模型的强大性能,常常伴随着高昂的计算代价,因此研究者开始探索轻量化与高效推理:
OpenVLA:引入 LoRA(低秩适配)实现参数高效的模态对齐,训练成本大幅下降。 DeeR-VLA:通过动态提前退出机制,在保证精度的同时显著降低计算开销。 VoxPoser:更“野心勃勃”,它通过语言驱动的可供性推理(affordance inference),在 3D 空间中生成价值图,让机器人在动态环境中可以实时调整策略,做到“见招拆招”。
这种趋势很明显:不仅要让机器人更聪明,还要让它更快、更轻、更能落地。
总体来看,基于 VLA 的多模态融合,让机器人在操作任务中实现了三重跃迁:
感知更强:能同时理解空间布局、物体属性和语义信息; 理解更深:语言与视觉对齐后,机器人能“听懂”复杂任务; 执行更准:融合多模态信息后,动作规划更加合理高效。
视觉 + 触觉:让机器人“摸得准、抓得稳”
在机器人抓取与操作中,视觉负责给出全局信息(物体位置、形态、姿态),而触觉则提供局部反馈(接触力、摩擦、滑动等)。两者结合,让机器人不仅“看得见”,还能“摸得准”,操作的精度与稳定性会大幅提升。
抓取生成:先“看清”,再“摸准”
在抓取生成阶段,视觉帮助确定物体的空间姿态和位置,而触觉则补充表面特性和受力信息,用于选择最优抓取点。
FusionNet-A:将视觉与触觉特征通过三维池化和全局平均池化融合,用于物体识别与抓取规划。 VITO-Transformer:基于 Vision Transformer,把触觉信号引入自注意力机制,实现动态适应的抓取点预测。
一句话总结:视觉负责“发现目标”,触觉负责“挑最稳的下手点”。
抓取规划与执行:触觉让机器人“更稳”
到了抓取规划与执行阶段,触觉反馈的重要性进一步放大:
RotateIt:融合视觉、触觉和本体感知(proprioception),在多轴旋转任务中实现最优力闭合。 Sparsh:提出大规模触觉预训练方法,学习到通用触觉表征,有效提升滑动检测和抓取稳定性。
这里触觉的作用有点像“安全气囊”,实时调整,让机器人不至于“手滑”。
抓取稳定性评估:多模态的真正价值
在抓取稳定性预测中,视觉-触觉融合展现出了巨大优势:
Li 等人:通过时空注意力机制动态分配模态权重,既关注空间关键区域,又跟踪时间变化。 MimicTouch:模仿人类触觉策略,结合自监督学习和强化学习,显著优化抓取稳定性。 Octopi:利用 GelSight 传感器收集高分辨率表面数据,并通过 CLIP 模型对齐视觉与触觉特征,实现更强的策略泛化。 TAVI:结合视觉空间推理与多指触觉反馈,实现翻转等复杂操作任务。
这些方法让机器人从“只会抓”升级为“会思考怎么抓”。
Vision-Language Models 演进

预训练:跨模态理解的起点
在多模态学习中,预训练几乎是整个系统的起点。通过在大规模图像-文本数据上进行联合训练,模型能够学会视觉与语言之间的深层语义关联。这样一来,它不仅能在图文匹配、图像描述、视觉问答等常见任务上表现出色,还能在标注稀缺的情况下依靠已有知识完成迁移,展现出极强的泛化能力。
核心思想其实很直接:把不同模态的数据(图像、文本、语音等)映射到同一个共享表示空间中,让模型理解“这张图片”和“这段文字”在语义上的对应关系。为了实现这一点,研究者通常会为不同模态设计专门的编码器,比如用 CNN 处理视觉、用 Transformer 处理文本,然后通过对比学习或自监督方法对齐它们。
其中最典型的例子是 CLIP:它通过大规模图像-文本对的对比学习,让模型学会在同一向量空间中把相关图像和文本拉近、不相关的推远。这种方式不仅让 CLIP 在零样本任务中“开挂”,还能轻松迁移到下游的多模态任务中,几乎成为跨模态预训练的标配方案。
跨模态对齐与表示学习
要让视觉和语言真正“对话”,光有一个共享空间还不够,跨模态对齐才是关键。这意味着模型必须学会在不同模态之间建立精确对应关系:一张图上的视觉区域要能和一句话里的词语对齐。但问题在于,图像是高维连续信号,文本是离散符号,如何让它们在同一空间高效交互,是跨模态研究的核心挑战。
目前,主流方法大致可以分为三类:
对比学习通过拉近正样本(同一图像和它的描述),推远负样本(不同图片与无关描述),模型能够学会“哪些是相关的,哪些不是”。代表方法有 CLIP、ALIGN,它们用大规模图文对训练出了极具泛化性的语义空间。 自监督学习借助掩码预测、图像修复或跨模态一致性等任务,让模型在没有人工标注的情况下,自动学到模态间的互补信息。例如 BLIP-2 通过图像-文本双向掩码任务,显著提升了跨模态理解能力。 跨模态生成让模型从一种模态生成另一种模态,比如根据文字生成图像(如 DALL·E、Imagen),或者根据图像生成描述和问答。这类方法不仅提高了模型的跨模态理解能力,也催生了许多创造性应用。
这三类方法相互补充,让模型不仅能“看懂”图文关系,还能推理、联想、生成。换句话说,模型从“懂得对应”进化到“学会表达”,为视觉语言的深度融合打下了基础。
视觉-语言模型的演进:从“小助手”到“全能选手”
自 2022 年以来,视觉-语言模型(VLM)的发展速度可以说是“卷”出新高度。最早的 Flamingo、PaLM-E 主要聚焦少样本学习和跨模态推理,让模型学会“看图说话”这件事。随后,MiniGPT-4 和 LLaVA 更进一步,不仅在视觉与语言的深度对齐上做了加强,还通过指令微调让模型更懂人话,泛化能力直接起飞。而到了 Gemini、Llama-3.2 这一代,事情就更热闹了:多模态范围扩展到图像、文本、音频甚至跨语言,俨然一副“想做通用智能”的架势。
核心创新点:它们变强的秘密
大规模图文预训练先“喂饱”模型海量图文对,让它先学会“看懂”和“说对”,为跨模态推理打下坚实基础。 指令微调用自然语言告诉模型“我要什么”,结果发现它真能学会举一反三,甚至偶尔还能“猜”到你没说出口的需求。 结构优化新一代模型疯狂上“黑科技”,比如 MoE(专家混合)、稀疏注意力,一边变聪明,一边还想省算力,简直又要当学霸又要省电。

结论
这篇论文系统性地探讨了视觉语言模型(Vision-Language Models, VLMs)在机器人视觉中的“江湖地位”,算是一次全景式的盘点。我们聚焦于语义理解、三维目标检测、具身导航和机器人操作等核心任务,梳理了各种多模态融合方法是如何把视觉、语言、深度信息和点云“拉到一张桌子上”聊合作的。论文细致总结了几条主流技术路线,包括编码器-解码器框架、跨模态注意力机制、图神经网络等,并分析了它们在不同任务上的优缺点。与此同时,我们也拿传统方法和大模型驱动的新方法做了横向对比,看看“老江湖”和“新贵”各自的招式。除此之外,论文还系统整理了常用的数据集和评测基准,并不留情面地指出现有研究在方法、数据和任务维度上有点“不均衡”,堪称业内“真相局”。
在全面分析的基础上,总结了三个关键发现: 第一,跨模态对齐策略几乎决定了机器人感知能力的上限,但现实是——不同模态之间常常“不说同一种语言”,语义粒度差异和特征对不上号仍是硬伤; 第二,在算力有限的机器人平台上部署大规模 VLM,可不是“模型一丢就完事”,还得靠轻量化与多阶段自适应机制“精打细算”,否则 GPU 会先罢工; 第三,任务导向与在线自适应的融合方法逐渐走红,让机器人能在动态环境中实时“见招拆招”,像玩游戏开了“自动战斗”一样灵活。
当然,虽然 VLM 在标准化任务上表现得像“学霸”,可一旦放到真实机器人平台上,问题立刻暴露:传感器异质性导致模态缺失、稀疏或低质输入引发语义偏差,还有延迟、鲁棒性、可解释性这些硬性要求,样样都头疼。对此,作者提出未来研究可以重点关注三条路线: 一是引入结构化空间建模和记忆机制,让机器人拥有更靠谱的“空间感”; 二是提升系统的可解释性与伦理适应性,毕竟没人想养一个“黑箱型小叛逆”; 三是借鉴脑科学的建模理念,发展具备长期学习能力的认知型 VLM 架构,让机器人不再“短记性”,而是越用越聪明。
总之,我们的愿景很明确:未来的机器人视觉系统不仅要更自主、更高效,还得更懂我们。说白了,就是想把机器人培养成“既有大脑,又懂社交”的全能型选手。









![2025年中国畜牧机器人行业发展背景、市场现状及布局企业分析:“农业强国”战略背景下,行业发展前景广阔[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-08-29/68b0fca6679d3.jpeg)

