点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0.这篇文章干了啥?
这篇文章提出了一种名为导航世界模型(Navigation World Model,NWM)的可控视频生成模型,用于基于过去的观察和导航动作预测未来的视觉观察,以解决现有视觉导航模型的局限性。该模型采用条件扩散变压器(Conditional Diffusion Transformer,CDiT),在人类和机器人代理的多样化第一人称视角视频上进行训练,参数规模达10亿。在熟悉的环境中,NWM可模拟导航轨迹并评估其是否能达到目标,动态地纳入规划中的约束条件;在未知环境中,它能基于单张输入图像想象轨迹。具体内容包括:
模型设计:提出NWM的公式,将其定义为从先前的潜在观察和动作到未来潜在状态表示的随机映射,并引入时间偏移输入以学习环境的时间动态;设计CDiT作为世界模型,其计算复杂度与上下文帧数呈线性关系,在参数扩展和计算效率上优于标准DiT;介绍了使用NWM进行导航规划的方法,通过最小化能量函数将问题转化为模型预测控制(MPC)问题,并使用交叉熵方法进行优化。 实验设置:使用多个机器人数据集和未标记的Ego4D视频进行训练,以GO Stanford数据集作为未知评估环境;采用绝对轨迹误差(ATE)、相对位姿误差(RPE)、LPIPS、DreamSim、PSNR、FID和FVD等指标评估模型性能;将DIAMOND、GNM和NoMaD作为基线方法进行比较。 实验结果:消融实验表明,CDiT在模型容量、目标数量、上下文大小、时间和动作条件等方面具有优势;视频预测和合成实验显示,NWM在预测准确性和视频质量上优于基线方法;导航规划实验证明,NWM在独立规划、带约束规划和轨迹排名方面均取得了优于现有方法的结果;在未知环境中,训练未标记数据可显著提高视频预测性能。 局限性与展望:模型存在模式崩溃和难以模拟时间动态等局限性,未来可通过增加上下文和训练数据解决;目前模型使用3自由度导航动作,扩展到6自由度导航及更多动作是未来的研究方向。
NWM为视觉导航提供了一种可扩展、数据驱动的世界模型学习方法,有望推动视觉导航和基于模型的规划的发展。
1. 论文信息
论文题目:Navigation World Models 作者:Amir Bar、Gaoyue Zhou、Danny Tran、Trevor Darrell、Yann LeCun等 作者机构:FAIR at Meta、New York University、Berkeley AI Research等 论文链接:https://arxiv.org/abs/2412.03572v2
2. 摘要
摘要
导航是具备视觉运动能力的智能体的一项基本技能。我们引入了一种导航世界模型(NWM),这是一种可控的视频生成模型,它能根据过去的观测和导航动作来预测未来的视觉观测。为了捕捉复杂的环境动态,NWM采用了条件扩散变换器(CDiT),该模型在人类和机器人智能体的各种以自我为中心的视频集合上进行训练,并将参数规模扩展到了10亿。在熟悉的环境中,NWM可以通过模拟导航轨迹并评估它们是否能达成预期目标来规划导航路径。与行为固定的有监督导航策略不同,NWM可以在规划过程中动态地纳入约束条件。实验证明了它在从头开始规划轨迹或对从外部策略中采样的轨迹进行排序方面的有效性。此外,NWM利用其学习到的视觉先验知识,能够从单张输入图像中想象出陌生环境中的轨迹,使其成为下一代导航系统的一个灵活而强大的工具。
项目页面:https://amirbar.net/nwm arXiv:2412.03572v2 [cs.CV] 2025年4月11日

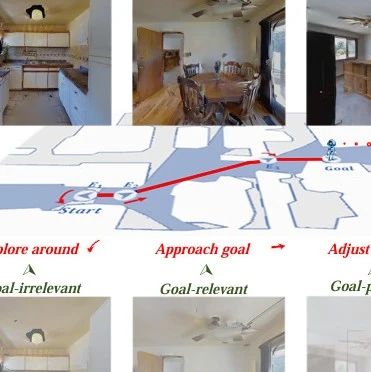
3. 效果展示
在已知环境中追踪轨迹。我们提供了不同模型沿真实轨迹生成的定性视频对比。
4. 主要贡献
文章的主要贡献如下:
引入了导航世界模型(NWM),并提出了一种新颖的条件扩散变压器(CDiT),与标准的DiT相比,它能有效扩展到10亿参数,同时显著降低计算需求。 在来自不同机器人代理的视频片段和导航动作上训练CDiT,使其能够独立或与外部导航策略一起模拟导航计划,从而实现最先进的视觉导航性能。 通过在无动作和无奖励的视频数据(如Ego4D)上训练NWM,证明了在未见环境中视频预测和生成性能得到了提升。
5. 基本原理是啥?
1. 导航世界模型(NWM)的提出
NWM是一种可控的视频生成模型,旨在基于过去的观察和导航动作预测未来的视觉观察。它通过在各种机器人和人类代理的视频片段及导航动作上进行训练,能够模拟潜在的导航计划并验证是否达到目标,从而规划新的导航轨迹。与其他相关模型相比,NWM在广泛的环境和实体中进行训练,利用了机器人和人类代理导航数据的多样性,且不依赖3D先验来训练一个用于跨不同环境导航的单一模型。
2. 条件扩散变压器(CDiT)的设计
模型架构:CDiT是一种用于学习NWM的新型条件扩散变压器,其计算复杂度相对于上下文帧的数量呈线性关系,在跨不同环境和实体训练高达10亿参数的模型时具有良好的扩展性,与标准DiT相比,所需的浮点运算次数减少了4倍。 训练目标:模型通过最小化干净目标和预测目标之间的均方误差来学习去噪过程,同时预测噪声的协方差矩阵并使用变分下界损失进行监督,以实现从噪声版本重建未来帧,从而生成逼真的未来帧。推荐课程:机械臂6D位姿估计抓取从入门到精通。
3. 基于世界模型的导航规划
熟悉环境中的规划:如果世界模型熟悉某个环境,可以使用它来模拟导航轨迹,并选择能够到达目标的轨迹。通过定义能量函数,将规划问题转化为模型预测控制(MPC)问题,并使用交叉熵方法进行优化。 未知环境中的规划:在未知环境中,NWM可以利用其学习到的视觉先验,从单个输入图像想象轨迹。通过添加未标记的数据进行训练,NWM在未知环境中的视频预测和生成性能得到显著提高。
4. 实验设置与结果
数据集:使用多个机器人数据集(如SCAND、TartanDrive、RECON和HuRoN)以及未标记的Ego4D视频进行训练,GO Stanford作为未知评估环境。
评估指标:使用绝对轨迹误差(ATE)、相对姿态误差(RPE)、LPIPS、DreamSim、PSNR、FID和FVD等指标评估预测的导航轨迹和视频合成质量。
实验结果
模型性能比较:CDiT在高达10亿参数的模型中表现更好,消耗的浮点运算次数不到DiT的2倍,且速度更快。使用4个目标状态、更多的上下文帧以及同时进行时间和动作条件训练可以显著提高模型的预测性能。 导航规划效果:NWM在独立规划和与现有方法结合使用时都取得了具有竞争力的结果,能够有效地在约束条件下进行规划,并通过轨迹排名提高导航性能。 泛化能力:在未知环境中,训练模型时添加未标记的数据可以显著提高视频预测和生成性能,但模型仍然存在模式崩溃等局限性。
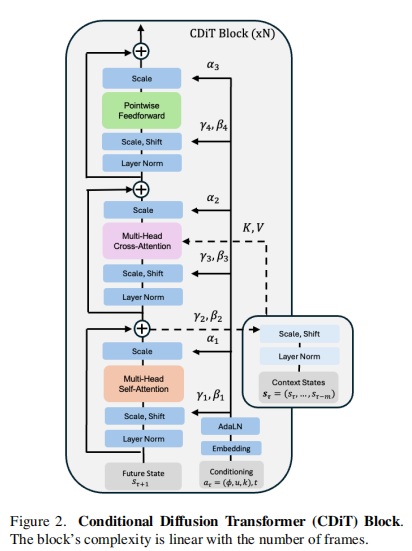
6. 实验结果
该文章围绕导航世界模型(NWM)展开了一系列实验,旨在验证其在视觉导航中的有效性和优势。实验结果总结如下:
消融实验
模型架构:在高达10亿参数的模型中,CDiT表现优于标准DiT,使用不超过2倍的FLOPs,且在参数相同时,CDiT速度快4倍且性能更佳。 目标数量:使用4个目标状态进行训练可显著提高模型在所有指标上的预测性能。 上下文大小:更多的上下文帧有助于提高模型的预测性能,上下文过短时模型易“失去跟踪”,导致预测效果不佳。 时间和动作条件:同时使用时间和动作条件训练模型效果最佳,仅使用时间条件会导致性能较差,不使用时间条件也会使性能略有下降。
视频预测和合成
预测准确性:与DIAMOND相比,NWM的预测准确性显著更高。在初始阶段,NWM的1 FPS变体表现更好,但8秒后,4 FPS变体由于累积误差和上下文丢失较少而更优。 生成质量:通过FVD评估视频生成质量,结果表明NWM生成的视频质量更高。
导航规划实验
独立规划:在目标条件导航中,NWM独立规划的结果在所有指标上均优于NoMaD和GNM等先前方法,如在RECON数据集上预测2秒轨迹时,NWM的ATE和RPE表现更优。 约束规划:NWM能够有效支持带约束的规划,在不同约束条件下规划时,仅出现轻微的性能下降,且能满足所有约束条件。 轨迹排名:NWM可增强现有导航策略,通过对NoMaD采样的轨迹进行评估和排名,选择更多样本(如32个)时导航性能进一步提升。
未知环境泛化:在未知环境(如Go Stanford数据集)中,使用未标记的Ego4D数据进行训练可显著提高视频预测性能和生成质量。不过,模型在未知环境中更容易出现模式崩溃,且在模拟行人运动等时间动态方面存在困难。
运行时间和效率
时间跳过:通过组合相邻动作并模拟更少的未来状态,可在不降低导航性能的情况下加速推理时间。 模型蒸馏:将扩散去噪步骤从250减少到6可进一步加速推理,仅伴有轻微的视觉质量损失。 量化:理论上,4位量化可实现4倍的加速且不影响性能。
测试时间适应:通过在未知环境的轨迹上对NWM进行2k步的微调,可改善该环境中的轨迹模拟效果。

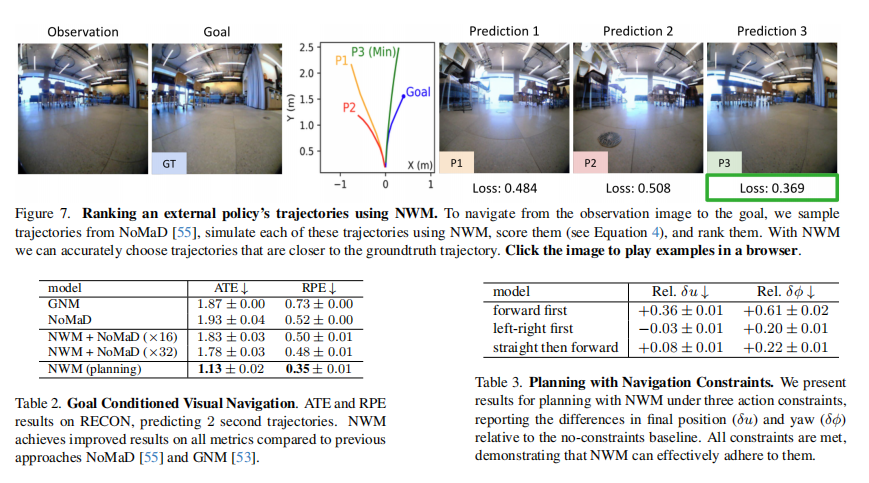



7. 总结 & 未来工作
总结
本文提出了一种用于视觉导航的导航世界模型(Navigation World Model,NWM),它是一种可控的视频生成模型,基于过去的观察和导航动作预测未来的视觉观察。具体内容如下:
模型设计:提出了一种新颖的条件扩散变压器(Conditional Diffusion Transformer,CDiT),其计算复杂度与上下文帧数呈线性关系,在高达10亿参数的模型训练中,与标准的DiT相比,能显著降低计算需求,同时实现更好的未来预测结果。该模型在来自各种机器人和人类代理的第一人称视角视频上进行训练。 导航规划:在熟悉的环境中,NWM可以通过模拟潜在的导航计划并评估它们是否达到预期目标来规划导航轨迹。与固定行为的监督导航策略不同,NWM可以在规划过程中动态纳入约束条件。实验表明,它在从头规划轨迹或对从外部策略采样的轨迹进行排名方面都非常有效。 泛化能力:在未知环境中,NWM可以从单个输入图像想象轨迹,通过在无标签、无动作和无奖励的视频数据(如Ego4D)上进行训练,能够提高在未知环境中的视频预测和生成性能。 实验结果:通过与多个基线模型(如DIAMOND、GNM、NoMaD等)的比较,NWM在多个评估指标(如绝对轨迹误差、相对姿态误差、LPIPS、DreamSim、PSNR、FID和FVD等)上表现出色,无论是独立规划还是与现有方法结合使用,都能实现最先进的视觉导航性能。
未来展望
解决模型局限性:当前模型存在两个主要局限性,一是在处理分布外数据时会出现模式崩溃,二是在模拟行人运动等时间动态方面存在困难。未来可以通过使用更长的上下文和更多的训练数据来解决这些问题。 扩展导航动作维度:目前模型使用3自由度的导航动作,未来可以将其扩展到6自由度导航,甚至控制机器人手臂的关节等,这将为模型的应用带来更多可能性。
3D视觉硬件

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦