VLA模型在推理任务要求机器人能够解读多模态指令、完成长程规划,并在动态环境中自适应地执行任务。但以端到端的方式训练的VLA模型,直接将输入映射到动作,缺乏显式的推理过程,这限制了模型的长程规划和适应复杂动态任务的能力。
为此,NVIDIA联合台湾大学提出基于MLLM的双系统VLA模型ThinkAct。ThinkAct采用双系统架构,通过强化驱动的视觉潜在规划连接高层推理与低层动作执行,让MLLM具备在真实环境中执行行动前的推理能力。
在具身推理和机器人操作基准上的大量实验表明,ThinkAct在复杂的具身任务中具备了少样本适应、长程规划和自主纠正的能力。

论文标题:《ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning》
论文链接:https://arxiv.org/pdf/2507.16815
项目主页:
https://jasper0314-huang.github.io/thinkact-vla/
1
方法
ThinkAct采用双系统架构,连接结构化推理与可执行动作。具体而言,通过基于动作对齐奖励的强化学习来增强MLLM的长程规划能力,该奖励源自视觉目标完成度和轨迹分布匹配。ThinkAct还能够利用人类和机器人视频来激发基于视觉观察的具身推理。
为了连接推理和执行,将中间推理步骤压缩为紧凑的潜在轨迹。该轨迹捕获高层意图,并允许下游动作网络高效适应新环境。通过强化结构化推理并聚焦于真实世界动作,ThinkAct解决了长程操作任务,同时在物理场景中实现了少样本动作适应和自我纠正。

1.1 用于具身推理的强化视觉潜在规划
为了实现在多样化环境中泛化的具身推理,该团队通过强化学习增强MLLM的推理能力。现有方法往往是让MLLM在生成低层动作之前推理,同时使用目标环境中的任务成功率作为奖励信号。但这种方法局限于特定的仿真环境,无法在多样化的环境中泛化。
为了应对这一挑战,该团队设计了一种创新的动作对齐视觉反馈,它捕获长程目标并鼓励规划过程中的视觉关联。具体而言,将高层planning表示为时空轨迹,捕获视觉场景上的gripper末端执行器,作为引导具身推理的视觉-动作指导。

为了增强MLLM  的具身推理能力,使用group相对策略优化(GRPO)进行强化微调。给定输入
的具身推理能力,使用group相对策略优化(GRPO)进行强化微调。给定输入 ,GRPO首先从原始MLLM
,GRPO首先从原始MLLM  采样M个不同的响应
采样M个不同的响应 。每个响应使用:
。每个响应使用:

定义的奖励函数进行评估,得到一组奖励信号 。因此,通过最大化以下目标来优化
。因此,通过最大化以下目标来优化  :
:

为了进一步获得通用的具身知识,ThinkAct可以灵活地封装公开可用的问答数据,通过将其格式化为问答式准确性奖励,来增强机器人VQA或故障检测等能力。完成强化微调,将能够生成长CoT步骤;同时将文本推理抽象为紧凑的视觉计划潜变量  ,捕获长程时空规划意图。
,捕获长程时空规划意图。
1.2 推理增强的动作适应
利用MLLM推理出的高层具身意图,目标是以“先思考后行动”的方式,将推断出的视觉潜在规划  与目标环境的动作模型
与目标环境的动作模型 连接起来,将具身推理嵌入到物理世界的可执行动作中。具体而言,基于Transformer的动作模型
连接起来,将具身推理嵌入到物理世界的可执行动作中。具体而言,基于Transformer的动作模型 构建,该模型基于由视觉观察和语言指令组成的当前状态预测动作。虽然
构建,该模型基于由视觉观察和语言指令组成的当前状态预测动作。虽然 仅通过感知即可在目标环境中运行,但通过将其以latent projector的方式与动作模型的输入空间连接起来,增强其能力,使推理指导能够被有效利用,从而增强其在目标环境中的底层动作执行。因此,仅通过带标注的动作演示,以模仿学习的方式更新状态编码器、latent projector和动作模型:
仅通过感知即可在目标环境中运行,但通过将其以latent projector的方式与动作模型的输入空间连接起来,增强其能力,使推理指导能够被有效利用,从而增强其在目标环境中的底层动作执行。因此,仅通过带标注的动作演示,以模仿学习的方式更新状态编码器、latent projector和动作模型:
1.3 学习策略与推理
受Video-r1启发,ThinkAct采用多阶段训练策略。在强化学习之前,独立初始化两个模块。MLLM  使用监督数据进行冷启动,用于学习解释视觉轨迹并以正确的输出格式生成推理和答案。另一方面,动作模型
使用监督数据进行冷启动,用于学习解释视觉轨迹并以正确的输出格式生成推理和答案。另一方面,动作模型 在 Open X-Embodiment (OXE) 数据集上进行预训练,为底层动作执行提供坚实基础。在SFT冷启动之后,MLLM
在 Open X-Embodiment (OXE) 数据集上进行预训练,为底层动作执行提供坚实基础。在SFT冷启动之后,MLLM  使用动作对齐的奖励进行调优,以指导生成有效的潜在planning。在推理增强的动作适应期间,冻结
使用动作对齐的奖励进行调优,以指导生成有效的潜在planning。在推理增强的动作适应期间,冻结 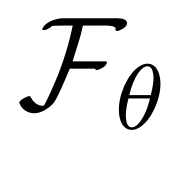 ,同时根据潜在视觉planning
,同时根据潜在视觉planning  的条件,在目标环境上更新动作模型
的条件,在目标环境上更新动作模型 及其状态编码器和latent projector。
及其状态编码器和latent projector。
在推理时,给定视觉观察和指令,ThinkAct生成视觉planning潜变量 ,该潜变量以动作模块
,该潜变量以动作模块 为条件,预测一系列适合当前环境的可执行动作。
为条件,预测一系列适合当前环境的可执行动作。
2
实验
2.1 机器人操作
为评估ThinkAct在机器人操作任务上的有效性,研究人员在SimplerEnv和LIBERO上进行评估。SimplerEnv包含Google-VM (视觉匹配)、Google-VA和Bridge-VM三种任务,引入了颜色、材质、光照和相机位姿的变化以测试模型鲁棒性。对于LIBERO 基准,借鉴先前工作OpenVLA、Cot-vla,评估LIBERO-Spatial、LIBERO-Object、LIBERO-Goal和LIBERO-Long子任务,以测试模型在空间布局、物体变化、目标多样性和长程规划方面的泛化能力。
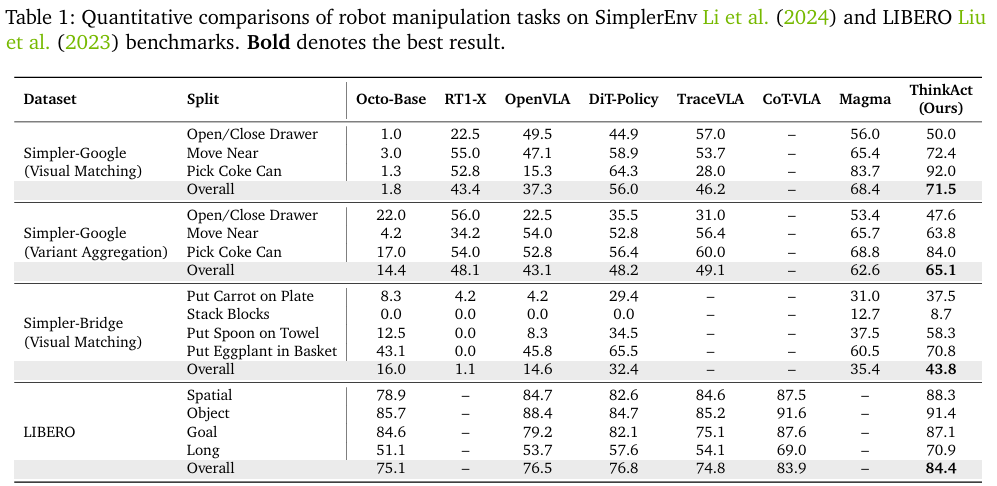
实验结果如上表所示,在SimplerEnv上,ThinkAct在Google-VM、Google-VA和Bridge-VM上分别比基线动作模型DiT-Policy成功率高出15.5%、16.9%和11.4%。ThinkAct在三种任务上的总成功率分别是71.5%、65.1%和43.8%,在所有方法中位列最高。
在LIBERO基准上,ThinkAct取得了84.4%的最佳总成功率,优于DiT-Policy和近期最优的CoT-VLA,证明了该模型在在多样化机器人操作中的有效性。
2.2 具身推理
在EgoPlan-Bench2、RoboVQA、OpenEQA三个基准上评估了ThinkAct在具身场景中的推理能力。

EgoPlan-Bench2评估模型在家庭场景中的多步规划能力,ThinkAct总成功率为48.2%,比第二名Qwen2.5-VL*的45.7%高出2.5%。RoboVQA侧重于机器人操作中的长程任务推理,ThinkAct总成功率为59.8%,比第二名Qwen2.5-VL*的55.7%高出4.1%。OpenEQA侧重于评估模型在多样化环境中的零样本具身理解能力,ThinkAct实现了更好的泛化和场景理解能力,在该基准上也取得了最佳性能,总成功率为56.2%。
2.3 定性结果
如下图展示了Simpler-Bridge和LIBERO-Long任务中的两个操作示例的推理过程和执行场景。在LIBERO-Long任务“拿起书并将其放入后面的隔间”中,ThinkAct将指令分解为子任务:(1)拿起书;(2)从左向右移动;(3)将书放入隔间。该任务体现了ThinkAct的长程规划能力,还对规划轨迹进行了可视化,证实了gripper在执行过程中紧密遵循推理引导的planning。

为了更好地证明强化学习对推理过程的影响,下图展示了在具身推理任务上进行强化学习微调前后的ThinkAct。

2.4 ThinkAct分析
推理增强少样本适应
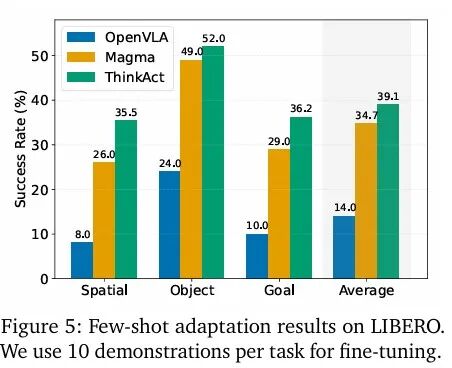
根据图3和图4观察,ThinkAct能够描述环境并将任务指令分解成可执行的子目标。为验证这种推理是否提高了动作模型的适应性,在LIBERO基准上进行了少样本适应实验。具体来说,使用LIBERO-Spatial和LIBERO-Object来评估模型对未知环境的适应能力,并使用LIBERO-Goal测试模型对新技能的适应能力。在每个任务上仅使用10个演示样本对动作模型微调,并在100次试验中评估性能。
如下图所示,ThinkAct始终优于最先进的方法,在所有任务中取得了最高的成功率。与Magma对比,在LIBERO-Goal上高出 7.3%,在LIBERO-Spatial上高出9.5%,证明了推理能力在新技能和新环境中进行少样本泛化的有效性。
推理引发的自主纠正
故障检测和自主纠正是机器人操作的关键。为评估ThinkAct是否能够面对错误的执行进行思考并纠正,研究人员让推理MLLM在执行过程中观察更多的context信息,将其输入从单张图像扩展到短视频片段。这种时间context使ThinkAct能够检测故障、重新思路并重新规划。如下demo所示,在一项“要求机器人将盒子放入篮子”的任务中,gripper在中途意外掉落了盒子。模型识别出了该故障,称“让我们重新考虑如何完成这项任务”,并生成了一个修正planning,引导gripper回到掉落位置重新抓取盒子。随后,机器人成功完成了任务,这证明了ThinkAct能够通过推理反思错误行为并进行自我纠正。
3
总结
NVIDIA联合台湾大学提出基于MLLM的双系统VLA模型ThinkAct。通过结合动作对齐的强化学习和增强推理的动作适应,ThinkAct使具身智能体能够“先思考再行动”,并能在动态环境中鲁棒的执行动作。在大量的具身推理和机器人操作任务上的实验,展示了ThinkAct强大的长程规划、少样本适应、故障检测和自主纠正的能力,为通向更具思考性和适应性的具身智能提供了一条可行的路径。
END
推荐阅读
灵巧手抓放任务成功率100%!帕西尼联合上交大提出融合触觉的VLA模型OmniVTLA
全面优于π0!星海图开源端到端双系统VLA模型G0:基于500小时真机数据预训练
训练数据65万条!上海AI Lab联合提出端到端VLA模型InstructVLA,真机实验成功率超OpenVLA
20亿参数+全面超越π0!清华朱军团队&地平线提出全新VLA模型H-RDT,有效从人类操作数据中学习
机器人非抓取操作重大突破!北大&银河通用王鹤团队提出自适应世界动作模型DyWA | ICCV 2025
点击下方名片 即刻关注我们










