点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

太长不看版:FastVGGT 在 VGGT 的注意力图中观察到很强的相似性,并利用无训练加速。
0. 论文信息
标题:FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
作者:You Shen, Zhipeng Zhang, Yansong Qu, Liujuan Cao
机构:Xiamen University、Shanghai Jiao Tong University
原文链接:https://arxiv.org/abs/2509.02560
代码链接:https://arxiv.org/abs/2509.02560
1. 导读
三维视觉的基础模型最近在三维感知方面表现出显著的能力。然而,由于推理时间效率低下,将这些模型扩展到长序列输入仍然是一个重大挑战。在这项工作中,我们详细分析了VGGT,一个SOTA前向可视几何模型,并确定了其主要瓶颈。可视化进一步揭示了注意图中的标记崩溃现象。受这些发现的启发,我们探索了前向可视觉几何模型中标记合并的潜力。由于三维模型独特的架构和任务特性,直接应用现有的合并技术是具有挑战性的。为此,我们提出了FastVGGT,它利用可视几几何模型中的标记合并在训练后实现加速。我们设计了一种独特的标记分区策略,专门针对三维架构和工作,有效地消除了冗余计算,同时保持VGGT强大的重建能力。在多个三维几何基准上的广泛实验验证了我们方法的有效性。 值得注意的是,在1000张输入图像的情况下, FastVGGT 比VGGT实现了4倍的速度提升,同时在长序列场景中减少了错误积累。
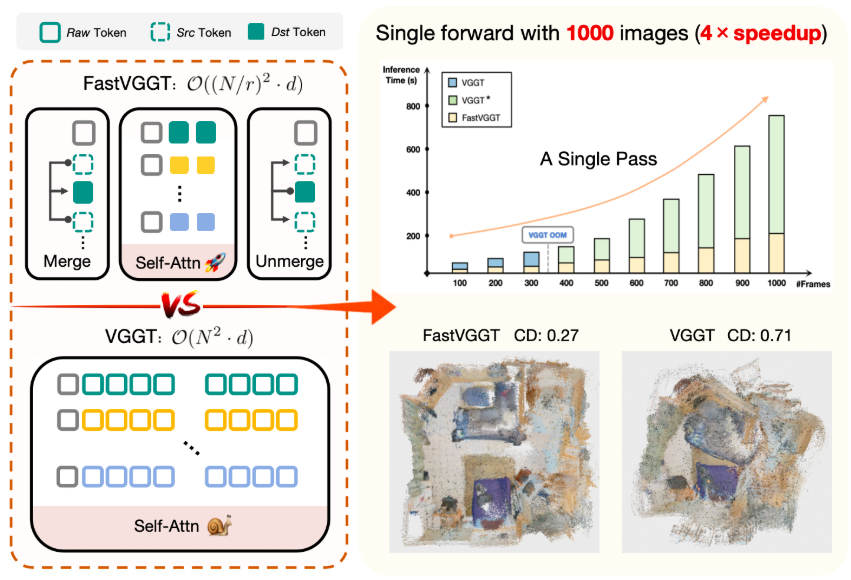
2. 效果展示
与VGGT通过所有场景标记进行密集交互不同,FastVGGT采用令牌合并,将交互限制在一个紧凑的子集中。对于1000张输入图像,它在减少错误累积的同时实现了超过4倍的推理速度提升。VGGT*表示VGGT的VRAM高效版本,使其能够处理更大的输入数据。
3. 引言
对于较长的输入序列,VGGT的推理速度主要受到 全局注意力的限制。
从视觉输入中推断场景的三维几何结构,对于机器理解物理世界并与之交互至关重要。深度学习的最新进展推动了三维几何估计领域的范式转变,实现了从基于迭代的优化管线向端到端神经网络的转变,这种网络可直接从原始视觉输入推断几何结构。
这种转变的典型代表是DUSt3R及其后续工作等大规模架构,它们展现出对跨图像对的复杂几何关系进行推理的卓越能力。在此基础上,VGGT实现了显著突破。其基于Transformer的前馈架构直接回归关键三维属性,包括相机参数、深度图和点轨迹,从而实现高度稳定且精确的重构。虽然这确立了VGGT作为三维场景理解领域最先进框架的地位,但其可扩展性受到两个关键瓶颈的制约:
第一,模型在跨视图或帧的密集全局令牌交互上存在计算成本过高的问题。尽管采用了Flash-Attention等技术将内存复杂度从O(n²)降低到O(nd),但底层时间复杂度仍保持为O(n²d)的二次方级别。第二,全局注意力机制作为捕获帧间关系的关键组件,容易产生误差累积。随着令牌空间随新帧的加入而扩展,微小误差会被放大,导致预测结果显著漂移。这些局限性共同限制了VGGT在大规模场景中的应用,并推动着更高效、更具可扩展性架构的开发。推荐课程:基于深度学习的三维重建MVSNet系列 [论文+源码+应用+科研]
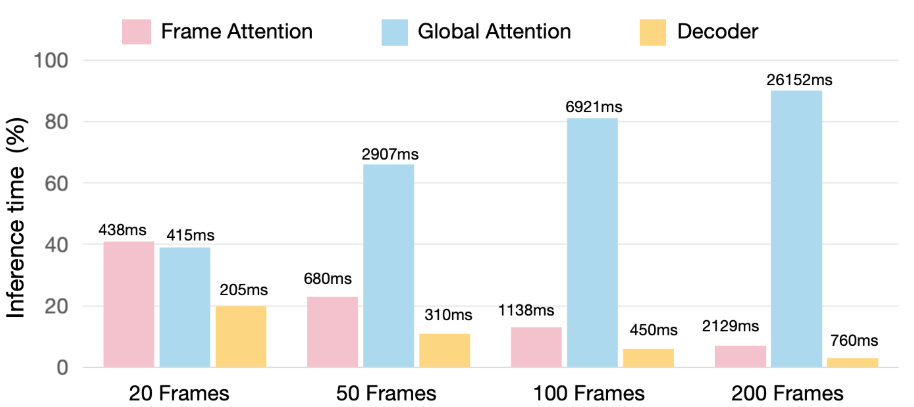
为定位VGGT的主要推理瓶颈,我们首先进行了详细的组件级性能分析。分析表明,虽然"帧内注意力"(帧内交互)和"全局注意力"(帧间交互)的计算成本在短序列中相当,但全局注意力的成本会随序列长度急剧上升,最终主导整个运行时间分布。这一发现催生了我们的核心研究问题:能否在不损害VGGT能力的前提下,缓解全局注意力的计算低效问题?为探究此可能性,我们可视化展示了注意力图,发现令牌间的注意力模式存在高度相似性,表明全局计算中存在显著冗余。我们在ScanNet数据集上可视化VGGT的全局注意图。每张图像由1,041个标记(一个相机标记,四个寄存器标记,以及来自28×37网格的1,036个补丁标记)表示。密集自我注意机制为每个标记生成一个注意图,标记和块之间的可视化显示许多这些图非常相似。

基于对注意力冗余的观察,我们引入了无需训练的令牌合并技术来提升VGGT的推理效率。令牌合并通过将令牌划分为源(src)集和目标(dst)集,并将每个源令牌合并到最相似的目标令牌中,从而整合冗余表示。尽管该方法在二维视觉任务中有效,但其向专为三维几何理解设计的架构扩展仍属未探索领域。不同于处理单张图像的二维场景,VGGT依赖跨图像对应关系,这使得直接应用令牌合并技术极具挑战性。
为此,我们提出FastVGGT——一种新型无需训练的框架,通过策略性应用令牌合并来缓解全局注意力瓶颈。我们的方法首先保留基础坐标系:具体而言,首帧令牌作为整个场景的全球参考,被指定为高优先级目标(dst)令牌并免于合并,以确保重构稳定性。此外,为保持全局一致性并保留细粒度细节,我们识别并保留所有帧中最显著的令牌,使其完全绕过合并过程并直接参与注意力计算。最后,受ToMeSD启发,我们在后续各帧中实施基于区域的随机采样,确保源令牌和目标令牌的空间平衡选择,防止合并过程中局部区域关键信息的丢失。
实验表明,这种集成方法使FastVGGT显著降低了全局注意力的计算开销。对于包含1000张图像的大规模输入,其推理速度较基线VGGT提升4倍,同时缓解了长序列重构中的误差累积问题。值得注意的是,原始VGGT因内存消耗过高,在处理超过300张图像的序列时会出现内存不足(OOM)错误。通过显存优化,改进后的VGGT成功处理超过1000张图像的输入,展现出显著的可扩展性提升。
4. 主要贡献
我们的主要贡献如下:1)识别并分析了限制VGGT推理速度的关键瓶颈;2)基于对VGGT全局注意力的观察,首次将令牌合并引入前馈视觉几何架构;3)通过大量实验证明,我们的方法在保持重构质量的同时,显著加速了VGGT在大规模输入下的处理速度,并缓解了误差累积。
5. 方法
我们通过采用无训练的令牌合并来缓解VGGT中的冗余注意力。虽然在二维视觉中已经很成熟,但其在三维架构中的应用仍未被充分探索。由于视觉几何依赖于跨图像对应,我们提出了三种定制但简单且有效的令牌合并在策略:
初始帧中的令牌(作为整个场景的全局参照)被指定为高优先级dst令牌,并免于合并以确保重建稳定性。
为了保持全球一致性并保留细粒度的细节,我们识别并保留所有帧中最显著的标记,使它们能够完全绕过合并过程,直接参与注意力计算。
灵感来自 ToMeSD ,我们在每个后续帧内实现基于区域的随机采样。这确保了 src 和 dst 令牌的空间平衡选择,防止合并过程中局部区域的关键信息丢失。

6. 实验结果
我们首先在ScanNet-50数据集上评估FastVGGT,使用倒角距离(CD)指标报告重构质量。实验采用包含1000、500和100张图像的输入序列,以评估不同序列长度下的性能。表2结果显示,尽管π³和StreamVGGT等先进方法在短序列上表现优异,但因内存限制无法处理长序列。Fast3R和CUT3R等方法虽能高效处理长序列,但重构质量严重下降。相比之下,FastVGGT在所有设置下均较基线VGGT实现显著加速,同时保持重构精度。特别地,在处理超长序列(如1000张图像)时,FastVGGT不仅维持重构保真度,还显著缓解误差累积,展现出大规模三维重构的鲁棒性和可扩展性。


7. 总结
本研究提出Fast-VGGT——一种无需训练的加速方法,通过策略性令牌合并提升VGGT推理速度,同时不牺牲重构质量。通过性能剖析,我们确定全局注意力模块是长序列输入的主要瓶颈,并观察到其注意力图存在强相似性。为此,我们引入令牌合并缓解推理瓶颈,并设计适配前馈视觉几何模型的策略。在多个基准上的实验表明,FastVGGT在1000张图像输入下实现最高4倍加速,同时在相机位姿估计和三维重构任务中保持竞争力,并进一步缓解长序列设置中的误差累积。这些结果凸显令牌合并作为扩展视觉几何模型的原则性解决方案的价值,并证明FastVGGT在实际应用中具有即时实用性。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001











