导语:
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。
代码链接:https://github.com/RLinf/RLinf
Hugging Face链接:https://huggingface.co/RLinf
使用文档链接:https://rlinf.readthedocs.io/en/latest/

人工智能正在经历从“感知”到“行动”的跨越式发展,融合大模型的具身智能被认为是人工智能的下一发展阶段,成为学术界与工业界共同关注的话题。在大模型领域,随着o1/R1系列推理模型的发布,模型训练的重心逐渐从数据驱动的预训练/后训练转向奖励驱动的强化学习(Reinforcement Learning, RL)。OpenAI预测强化学习所需要的算力甚至将超过预训练。与此同时,能够将大规模算力高效利用的RL infra的重要性也日益凸显,近期也涌现出一批优秀的框架,极大地促进了该领域的发展。

然而,当前框架对具身智能的支持仍然受限。相比推理大模型这一类纯大脑模型,具身智能领域存在大脑(侧重推理、长程规划,如RoboBrain)、小脑(侧重执行、短程操作,如OpenVLA)及大小脑联合(快慢系统,如pi 0.5)等多样模型。其次,具身智能除了包含Agentic AI的多步决策属性外,他还有一个独特属性:渲训推一体化。与工具调用智能体、浏览器智能体所交互的仿真器相比,具身仿真器通常需要高效并行物理仿真和3D图形渲染等,因此当前主流仿真器通常采用GPU加速,耦合多步决策带来了算力和显存竞争的新挑战。总的来说,具身智能领域不仅继承了推理大模型和数字智能体的难点,同时还引入了新的渲训推一体化特征,再加上具身智能模型尚未收敛,对框架的灵活性、高效性和易用性提出挑战。

在这样的背景下,清华大学、北京中关村学院和无问芯穹联合推出了一个面向具身智能的灵活的、可扩展的大规模强化学习框架RLinf。

RLinf的“inf”不仅代表着RL “infrastructure”,也代表着“infinite” scaling,体现了该框架极度灵活的系统设计思想。RLinf的系统可以抽象为用户层(统一编程接口)、任务层(多后端集成方案)、执行层(灵活执行模式)、调度层(自动化调度)、通信层(自适应通信)和硬件层(异构硬件)6大层级。相比其他框架的分离式执行模式,RLinf提出的混合式执行模式,在具身智能训练场景下实现了超120%的系统提速,VLA模型涨幅40%-60%。同时,RLinf高度灵活、可扩展的设计使其可快速应用于其他任务,所训练的1.5B和7B数学推理大模型在AIME24、AIME25和GPQA-diamond数据集上取得SOTA。

设计一:采用基于Worker的统一编程接口,利用微执行流实现宏工作流,实现一套代码驱动多种执行模式。
当前已有强化学习框架通常采用两种执行模式:共享式(所有卡跑同一个组件) 和 分离式(不同的卡分配不同的组件)。然而,这两种模式在具身智能“渲训推一体”的特点下都存在局限性。主要是:由于具身智能体多步决策的属性,模型(Actor)要和仿真器(Simulator)频繁交互,而当前框架一方面不支持仿真器状态快速卸载和加载,另一方面若用共享式需要频繁加载卸载组件,切换开销大,严重降低系统效率。因此,目前已有的框架在这个场景下仅支持分离式训练,但分离式采用on-policy算法训练时资源闲置率高,系统气泡比较大。RLinf针对这一问题,提出了混合式执行模式,如图4所示,这种模式兼具分离式和共享式的优势,再配合上细粒度流水设计,使得系统几乎无气泡,显著提升了系统运行效率。

然而,要想实现一套代码驱动多种执行模式(即无需更改代码,通过配置参数即可实现分离、共享或混合)是不容易的,一种标准的解决方案是构建计算流图,但会导致编程灵活性降低,debug难度直线上升,所以当前已有框架通常只支持一种模式(分离或者共享),引入新的执行模式需要大量的系统开发。
为此,RLinf 提出了创新的宏工作流到微执行流的映射机制(Macro-to-Micro Flow,M2Flow),实现从组件级而非任务级进行调度。M2Flow允许用户使用过程式编程方式灵活构建复杂训练流程,解决传统计算流图构建编程灵活性低的问题,同时能够将过程式的训练流程灵活映射到底层不同的执行模式上,为不同的训练流程(如RLHF、RLVR等)选择最优执行模式(配合自动调度模块)。因此,该映射机制兼具过程式编程(Imperative Programming)的灵活性、易用性、易调试性和声明式编程(Declarative Programming)的编译优化能力。具体而言,RLinf采用基于Worker的统一编程接口,允许用户将训练流程中的不同组件,如模拟器、训练推理引擎,封装成不同Worker,然后通过过程式编程将这些Worker串起来形成完整的训练流程。M2Flow通过细粒度控制微执行流,即控制每个Worker的运行GPU、执行的批大小、执行时机等,实现极度灵活的执行模式。
总结来说,RLinf使用户能够以高度可适配的方式编排组件(Actor、Critic、Reward、Simulator等),组件可以放置在任意 GPU 上,并自动配置不同的执行模式,目前支持3种执行模式:
共享式(Collocated Mode):用户可以配置组件是否同时常驻于 GPU 内存,或通过卸载/重新加载机制交替使用 GPU。 分离式(Disaggregated Mode):组件既可以顺序运行(可能导致 GPU 空闲),也可以以流水线方式执行,从而确保所有 GPU 都处于忙碌状态。 混合式(Hybrid Mode):进一步扩展了灵活性,支持自定义组合不同的放置形式。典型案例是Generator和GPU-based Simulator执行分离式细粒度流水,二者与Inference和Trainer执行共享式。
设计2: 面向具身智能大小脑不同训练需求,采用全新的低侵入式多后端集成方案,兼顾高效性和易用性。
如前文提到,具身智能领域的特点是:大小脑同时存在,且该领域仍处在蓬勃发展期,技术路线尚未收敛。因此为了更好地支持具身智能不同用户(如具身大小脑研究人员)的需求,RLinf集成了两套后端:
Megatron + SGLang/vLLM:针对已收敛的模型架构(如具身大脑 VLM),支持已适配模型的快速接入,是大规模集群训练的首选模式。在这一模式下,RLinf也采用了全新的低侵入式训推引擎集成方式,有助于快速集成训推引擎的更新版本(用户可尝试切换SGLang版本,方法见说明文档Advanced Feature章节),进而能够启用Megatron和SGLang/vLLM的所有优化能力,如5D并行等。 FSDP + Hugging Face:针对未收敛的模型架构(如具身小脑 VLA),支持Hugging Face模型开箱即用无需适配,是快速小规模验证的首选模式。这一模式对于算力受限及新手用户比较友好,特别为具身智能从业者打造。

同时RLinf也支持多项来自一线从业者的刚需,包括LoRA训练,断点续训,以及适应不同网速用户的训练可视化(Tensorboard、W&B、SwanLab)等。此外,RLinf也正在集成SFT模块,致力于提供一站式的服务,通过一套代码满足多样化的训练需求。
设计3: 设计面向强化学习的自适应通信库和自动化调度模块,提升训练稳定性和系统效率。
自适应通信机制。强化学习存在多个组件,且这些组件之间存在大量的数据交互。灵活、高效的互通信是支撑强化学习框架高效运行的关键,也是框架可扩展性的重要保证。因此,RLinf特别设计了一套面向强化学习的通信库,其中主要包含四项优化技术:自适应CUDAIPC/NCCL通信、负载均衡传输队列、多通道并发通信机制、快速通信重配置。
自适应CUDAIPC/NCCL通信:无需用户配置,根据两个互通信组件所在GPU自动选择使用CUDAIPC通信还是使用NCCL通信,即两个组件位于同一个GPU上时使用CUDAIPC,位于不同GPU上时使用NCCL。 负载均衡传输队列:可以根据上一个组件在不同GPU上所产生数据量的大小,在发送给下一个组件的不同GPU时做数据量负载均衡,使得下一个组件不同GPU的计算量接近,提升系统运行效率。

多通道并发通信:使用多CUDA stream以及多网络流并发的通信,避免队头阻塞(Head-of-Line Blocking),降低通信延迟。 快速通信重配置:该功能主要面向大规模集群训练,是实现下文秒级动态扩缩的支撑技术之一,可有效解决通信容错和通信调整的问题。
自动化调度模块。大规模强化学习框架的优化目标是尽量减少系统资源闲置。已有框架通常采用人为指定资源配置的方案,依赖于人工经验,容易造成系统资源浪费,RLinf设计了一套自动调度策略,可以针对用户的训练流以及用户所使用的计算资源,选择最优的执行模式。具体而言,RLinf会对各组件做自动化性能分析,获得各组件对资源的使用效率和特征。然后,构建执行模式的搜索空间,该搜索空间描述了强化学习算法各组件对计算资源的分配复用关系,包括“时分复用”、“空分复用”以及二者结合的资源分配方案;在这样的建模下,RLinf的自动化调度不仅支持已有强化学习框架中“共享式”和“分离式”的典型资源分配方式,还支持二者结合的混合分配方案的建模分析。最后,基于上述性能分析数据,在该空间中搜索出最优的执行模式。除此之外,该自动调度策略还集成“秒级在线扩缩容(Online Scaling)”能力,70B模型只需 1 秒即可完成5D并行动态扩缩,而传统方案需十几秒甚至更久。该功能及相关论文将于10月上线开源版本。基于该技术可进一步实现运行时组件间计算资源的动态调度,配合细粒度流水设计,可以在保证算法on-policy属性的前提下进一步压缩系统气泡率,且显著提升训练稳定性。
RLinf性能快览
具身性能(采用FSDP+HuggingFace后端测试):
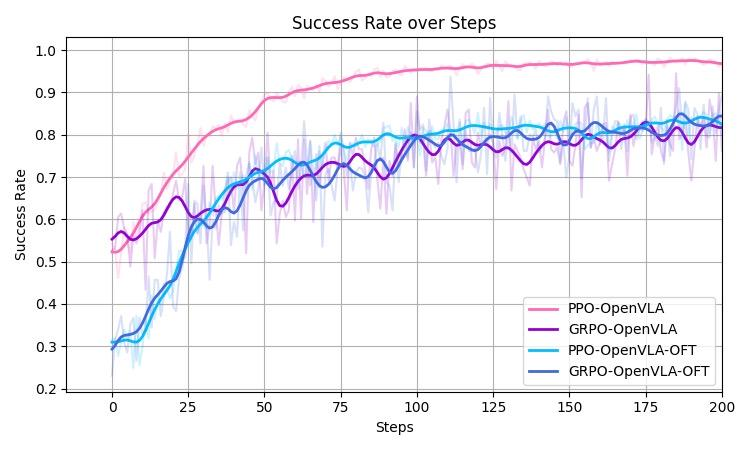
在应用上,与其他框架相比,RLinf 的特色在于Vision-Language-Action Models (VLAs)+RL的支持,为研究人员探索VLAs+RL领域提供了良好的基础算法性能及测试平台。RLinf支持了主流的CPU-based和GPU-based 仿真器(具体平台见说明文档),支持了百余类具身智能任务,集成了主流的具身大模型OpenVLA、OpenVLA-OFT、Pi 0。特别地,团队率先实现了对Pi 0的大规模强化学习微调,相关算法及论文将在9月底发布。在量化指标上,以Maniskill3(典型的GPU-based Simulator )为例进行测试,RLinf采用混合式结合细粒度流水的执行模式。相比其他框架的分离式执行模式,系统效率显著提速120%以上(图7)。OpenVLA及OpenVLA-OFT在Maniskill3 自建25个任务[1]中采用PPO算法和适配具身的GRPO算法训练后,成功率曲线如图8所示,可以看到模型成功率可以从SFT后的30%-50%提升至80%-90%,涨幅40%-50%以上。在公开测试平台LIBERO的4个场景中,OpenVLA-OFT采用RLinf适配具身的GRPO算法训练后,平均成功率达到97.3%,相比SFT模型涨幅62.4%。团队前序工作曾探讨RL和SFT对VLA泛化性提升的不同之处[1],RLinf将研究进一步拓展至大规模场景下,助力探索具身智能领域的RL Scaling Law。相关模型已开源在https://huggingface.co/RLinf,欢迎下载测试。


推理性能(采用Megtatron+SGLang后端测试):
面向具身智能是RLinf 的应用特色,但RLinf的系统设计思想不仅限于具身智能,灵活、可扩展的设计理念使得其可以快速支持其他应用,体现了其通用性。以RLinf 支持的推理大模型训练为例,团队集成优化后的GRPO算法[2]进行了数学推理大模型的训练,数据集为AReal-boba数据集[3],基座模型为DeepSeek-R1-Distill-Qwen。在三个测试集(AIME24、AIME25、GPQA-diamond)中进行测评,32 个样本取平均,Pass@1测试结果如表2和3所示,RLinf-math-1.5B和RLinf-math-7B在三个测试集上均取得SOTA性能(注:表格中的模型均来自HuggingFace开源模型,统一测试脚本https://github.com/RLinf/LLMEvalKit)。相关模型已开源在https://huggingface.co/RLinf,欢迎下载测试。


Last but not least!
考虑到框架的易用性,RLinf提供了全面且系统化的使用文档。RLinf在开发之初的目标就是开源,因此让每一个用户能够理解、使用和修改是设计原则之一,也是一个优秀开源框架必备的属性。团队采用公司级代码开发流程,确保文档内容覆盖从入门到深度开发的各层次需求。此外,RLinf还提供完整的API文档与集成AI问答机器人支持,以进一步提升开发体验与支持效率。

RLinf团队的开发成员具有交叉研究背景,包含从系统到算法到应用的技术全栈,例如系统架构设计、分布式系统、大模型训练推理加速、强化学习、具身智能、智能体等。正是由于这样的交叉背景,使得团队能够从应用需求驱动算法设计,算法指导系统设计,高效系统加速算法迭代,体现了大模型时代下新型科研形态。未来RLinf团队也将持续开发和维护,具体Roadmap见Github网站。

最后,诚挚地邀请大家体验RLinf框架,并且与我们交流技术观点与潜在合作机会。同时,RLinf团队持续招聘博士后、博士、硕士、研究员、工程师及实习生,欢迎投递简历,与我们共同推进下一代强化学习基础设施的建设与发展。(联系方式:zoeyuchao@gmail.com, yu-wang@mail.tsinghua.edu.cn)
[1] Liu, Jijia, et al. "What can rl bring to vla generalization? an empirical study." arXiv preprint arXiv:2505.19789 (2025).
[2] https://github.com/inclusionAI/AReaL
[3]https://huggingface.co/datasets/inclusionAI/AReaL-boba-Data










