导航是具身智能的基础能力,能够在真实环境中内导航和交互,对于机器人在物理环境中执行复杂任务至关重要。尽管该领域已取得了显著进展,但现有研究主要集中于相对低层次的任务,例如指令跟随和基本对象导航,未能完全捕捉动态环境中人类需求的差别。
当前的具身导航方法大致可分为两类:视觉与语言导航(VLN)和对象导航(ObjectNav)。VLN 任务要求智能体遵循详细的逐步指令,例如“左转,出门,然后直走”。这些任务需要精确的空间理解,通常过于依赖具体的指令,但这些指令在真实场景中人类很少会说。ObjectNav任务只能导航到预定义的对象类别(例如,“找到场景中的任何椅子”),并且在遇到目标对象时即告成功,而不考虑是否满足要求。
然而,真实世界中的人类指令常常需要复杂推理和很强的空间感知能力。例如,“我想喝杯咖啡”或“我想吃桌子上左边的水果”这样的需求,不仅需要理解潜在的目标对象,还需要推理对象之间的空间关系。这突显了现有的导航任务与真实世界需求之间的gap,严重阻碍了具身智能高级人机交互的发展。
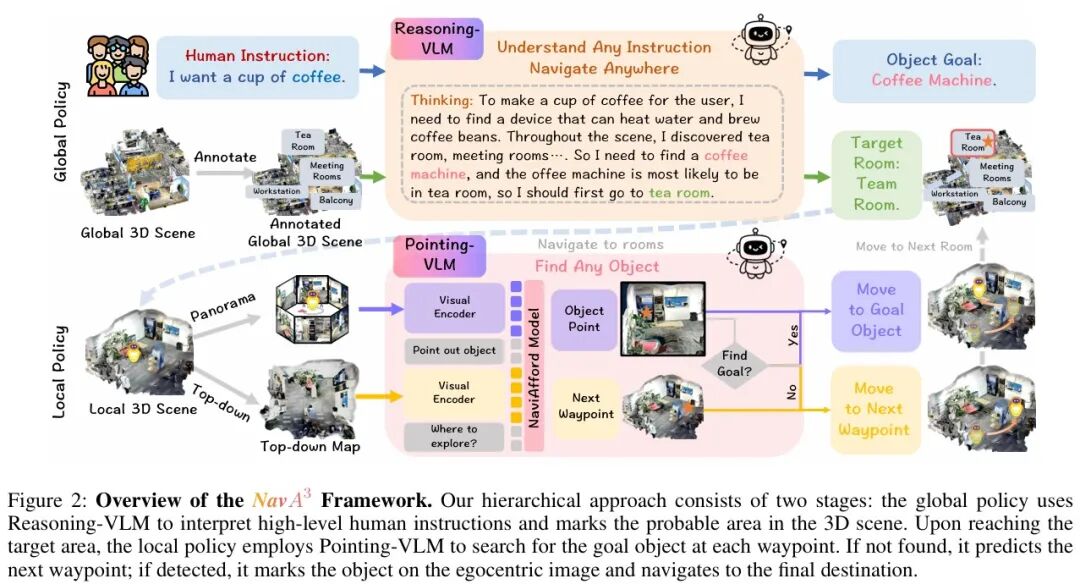
为此,清华大学联合北京智源人工智能研究院、中科院自动化所、北京大学等提出了长程导航任务,要求智能体能理解高级的人类指令,在真实环境中完成目标物体长程导航任务,并据此设计了分层框架NavA³。NavA³是一种创新的分层框架,将该复杂问题分解为全局策略和局部策略两个阶段,实现了对人类多样化的高级指令的理解、跨区域导航及对任意物体的定位。
实验表明,NavA³在导航性能上达到SOTA水平,为真实场景中通用具身导航系统的发展奠定了基础。

论文标题:《NavA3: Understanding Any Instruction, Navigating Anywhere, Finding Anything》
论文链接:https://arxiv.org/pdf/2508.04598v1
项目主页:https://NavigationA3.github.io/
1
方法
1.1 整体框架
NavA³采用了一种从全局到局部的分层方法,将语义推理与精确的空间定位相结合,以应对长程导航任务。
全局策略利用Reasoning-VLM解析高级人类指令。例如,“我想喝杯咖啡”,推断目标对象咖啡机并识别可能所在的房间如,茶室、厨房等。到达该房间后,局部策略利用NaviAfford模型(Pointing-VLM)分析每个路径点的全景RGB观测和局部地图。该模型判断目标对象是否存在;如果找到,则指向其位置以进行导航;如果未找到,则预测下一个最佳路径点或咨询Reasoning-VLM以继续探索,直到定位到目标。
1.2 3D场景构建
为实现在真实世界环境中的高效导航,使用了一个简单的重建流程构建了分层的3D场景表征,如图3所示。

该流程首先从多个视角捕获的一系列RGB图像,利用这些图像进行2D到3D重建。利用一个LiDAR传感器,生成一个密集点云,由以下公式表示:

其中每个点  代表场景中的一个3D坐标。重建过程采用特征点匹配算法在连续帧之间建立对应关系,随后通过网格重建生成连贯的3D几何结构。使用3D扫描应用程序简化此过程并确保高质量结果。
代表场景中的一个3D坐标。重建过程采用特征点匹配算法在连续帧之间建立对应关系,随后通过网格重建生成连贯的3D几何结构。使用3D扫描应用程序简化此过程并确保高质量结果。
重建的3D场景转换为俯视图后供全局和局部策略使用。全局策略采用MapNav的标注方法提供房间和区域级语义标注(如"茶室"、"会议室"、"阳台"、"工作站"),让VLM能很好地理解空间语义并推理出物体位置。标注后的全局场景表征为:

其中  代表几何区域,
代表几何区域, 是对应的语义标注。对于局部策略,直接使用未标注的俯视图地图Mlocal。
是对应的语义标注。对于局部策略,直接使用未标注的俯视图地图Mlocal。
1.3 全局策略
全局策略利用视觉语言模型Reasoning-VLM的推理能力连接高级人类指令与导航目标间的语义gap。如图2所示,给定人类指令 和标注的全局3D场景
和标注的全局3D场景 ,将全局推理任务作为多模态问题处理,Reasoning-VLM同时进行语义物体推理和空间位置预测。为支持系统化推理,研究人员设计了结构化提示模板来引导Reasoning-VLM:
,将全局推理任务作为多模态问题处理,Reasoning-VLM同时进行语义物体推理和空间位置预测。为支持系统化推理,研究人员设计了结构化提示模板来引导Reasoning-VLM:

1.4 局部策略
NaviAfford模型
为实现精准的空间物体定位,提出了NaviAfford模型,是一种Pointing-VLM,如图4所示。在LVIS和Where2Place数据集中精选的约5万张图像和100万个问答对上进行训练。将实例分割掩码转换为带边界框坐标  的物体检测格式,并在每个框内采样5-8个代表点以增强空间粒度和定位精度,提升Reasoning-VLM能力。
的物体检测格式,并在每个框内采样5-8个代表点以增强空间粒度和定位精度,提升Reasoning-VLM能力。

数据集构建系统生成两类可供性标注以实现全面空间理解。对于物体可供性,计算方向关系(上下左右前后)在特定语境中识别目标物体。例如,"寻找沙发前的电视",首先确定目标物体及其与参考物体的空间关系。对于空间可供性,识别满足约束的自由空间,使模型理解可用于导航和放置的区域。这种双重可供性的方法构建了能捕捉真实世界导航所需复杂空间关系的训练样本。
导航过程
智能体在每个路径点捕获全景RGB视图,NaviAfford模型检测目标物体:若检测到,输出多个点坐标,取中心点作为定位结果。坐标转换则通过相机内参将像素坐标转为相机坐标:

再通过旋转和平移转为机器人坐标。
若未检测到,系统遵循两阶段决策过程:首先由Reasoning-VLM分析局部3D场景和历史探索数据,决定继续探索当前区域或转移至新区域。若选择继续,则由NaviAfford模型识别下一最佳探索点;否则根据先前搜索选择最具潜力的新区域进行探索,实现高效区域转移。
2
实验
2.1 评估基准
为评估长周期导航性能,研究人员构建了一个包含五个不同场景的基准测试集:会议室A、会议室B、茶室、工作站和阳台。每个场景包含10个导航任务,总计50个任务。每种方法,对每个任务进行了10次。
2.2 与主流方法的对比
研究人员评估了三种类型的基线模型:
(1) 闭源通用VLM,包括GPT-4o、Qwen-VL-Max;
(2) 开源通用VLM,包括Janus-Pro-7B、Qwen2.5-VL-7B和LLaVA-Next-7B;
(3) 专用导航方法,包括NaVid、NaVILA和 MapNav,这些方法需要针对长程导航任务进行调整。
实验结果如表1所示,NavA3在所有场景中均显著优于现有的SOTA方法,平均成功率达到了66.4%;而现有的最优基线模型MapNav成功率仅有25.2%,NavA³比MapNav高出41.2%。而其他闭源通用VLM和开源通用VLM成功率极低,开源通用VLM成功率为0,闭源通用VLM成功率也仅有0.4%~2%,证明了NavA3能有效解决高级语言命令的理解与真实环境中空间导航之间的gap。
同时,NavA3在所有场景中都显著降低了导航误差(NE)。与最优基线模型MapNav相比,在会议室A降低了5.98米,在会议室B降低了6.49米,在茶室降低了7.23米,在工作站降低了5.22米,在阳台降低了6.11米。

2.3 真机实验
NavA3在轮式和四足机器人上的成功部署,突显了其通用性。给机器人语言指令,机器人经过深度思考,即可导航到正确的位置。如下demo所示为给轮式机器人“我想喝冰可乐”的指令,机器人最终成功找到了冰箱。
3
总结
本论文中,清华大学联合北京智源人工智能研究院等提出了解决具身导航与真实世界人类需求间gap的分层框架NavA³,使机器人能够理解高级语言指令并能在复杂环境中导航。该方法将导航分为全局和局部两个阶段:全局策略利用Reasoning-VLM解析指令和目标识别;局部策略使用该团队所提出NaviAfford模型进行精确的目标物体定位。实验表明,NavA³显著优于最先进的方法,且在轮式和四足机器人上成功部署。
END
推荐阅读
超越微软Magma!NVIDIA联合提出机器人VLA推理模型ThinkAct,能反思错误并自主纠正
结合3D高斯与生成模型!清华联合BIGAI提出机器人操作世界模型GWM | ICCV 2025
灵巧手抓放任务成功率100%!帕西尼联合上交大提出融合触觉的VLA模型OmniVTLA
全面优于π0!星海图开源端到端双系统VLA模型G0:基于500小时真机数据预训练
训练数据65万条!上海AI Lab联合提出端到端VLA模型InstructVLA,真机实验成功率超OpenVLA
点击下方名片 即刻关注我们










