
本文一作曹嘉航,香港大学在读博士生,前北京人形机器人创新中心实习生;共同一作黄翊泽,上海交通大学在读本科生;通讯导师 Andrew F. Luo,香港大学助理教授。
在机器人学习领域,提升基于生成式模型的控制策略(Policy)的性能通常意味着投入巨额成本进行额外的数据采集和模型训练,这极大地限制了机器人能力的快速迭代与升级。面对模型性能的瓶颈,如何在不增加训练负担的情况下,进一步挖掘并增强现有策略的潜力?
香港大学团队开创性地提出了 GPC(General Policy Composition,通用策略组合)框架,为这一挑战提供了全新的免训练解决方案。该框架通过在测试时(test-time)对多个预训练模型进行 “策略组合”,能够创造出一个性能超越任何单一父策略的 “组合策略”。
GPC 作为一个 “即插即用” 的通用框架,能够灵活融合不同架构(如 Diffusion-based Policy、Flow-based Policy)、不同模态(如视觉-动作模型 VA、视觉-语言-动作模型 VLA)的机器人策略,打破了传统性能提升方式对数据和算力的依赖。

论文标题:Compose Your Policies! Improving Diffusion-based or Flow-based Robot Policies via Test-time Distribution-level Composition
论文地址: https://arxiv.org/pdf/2510.01068
项目地址:https://sagecao1125.github.io/GPC-Site/
代码地址:https://github.com/SageCao1125/GPC
提高策略性能
GPC 免训练范式登场
尽管基于扩散模型(Diffusion-based models)的机器人策略已取得显著进展,但其性能的提升始终受限于模型容量和数据规模。传统的后训练优化方法,如监督微调(supervised fine-tuning)需要昂贵的数据收集,而强化学习(reinforcement learning)则面临复杂的奖励工程和大量的在线交互挑战。这些限制使得提升现有先进模型的性能变得既昂贵又耗时。
GPC 框架提出了一种提升策略性能的新范式。它不再依赖于 “更多训练”,而是巧妙地 “组合现有策略”。
GPC 的核心思想是在机器人执行任务的瞬间,通过凸组合(convex combination)的方式,将多个预训练策略的 “决策分数(distributional scores)” 进行动态融合。这种方式不仅简单高效,更重要的是,它建立在坚实的理论基础之上。
创新理论基石:证明 “1+1>2” 的组合潜力
这一理论基石主要包括两个核心发现。
功能层面的提升(Functional-Level Improvement):研究团队证明,对多个预训练策略的决策分数(distributional scores)进行凸组合(convex combination),能够生成一个在单步上具有更低误差的组合分数,它比任何一个单一策略的分数都要更精确。

系统层面的稳定性(System-Level Stability):通过建立一个 Grönwall 型界限,研究证明了单步的误差改善能够沿着整个轨迹传播,从而确保了组合策略在整个生成轨迹上也具有系统性的性能提升和更低的轨迹采样误差。

正是基于这一坚实的数学和系统稳定性证明,GPC 框架得以成立,为机器人能力的增强提供了全新的、有理论支撑的免训练路径。

通用 “策略组合器”
免训练实现 “即插即用”
通用策略组合(GPC)框架的核心优势在于其 “即插即用”(plug-and-play)的通用性,它以免训练的方式,轻松整合了各种机器人策略,打破了模型架构和模态的界限。
GPC 作为一种全新的范式,不再依赖于额外的模型训练,而是通过在测试时(test-time)将多个预训练策略的 “决策分数” 进行动态融合来实现性能增强。

异构策略的灵活架构组合
GPC 的通用性建立在其独特的分数组合机制上,使其能够跨越策略架构和输入模态进行灵活组合:
跨架构兼容:GPC 能够将基于扩散模型(Diffusion-based Policy)的策略或者基于流匹配(Flow-based Policy)的策略进行组合。这是因为无论策略是基于哪种生成式模型训练的,它们都能在底层被统一为分数函数(score function)的表示。
跨模态 / 跨任务融合:GPC 灵活整合了不同输入条件下的策略。无论是视觉 - 动作(VA)模型、视觉-语言-动作(VLA)模型,还是处理不同视觉模态(如 RGB 图像和点云)的策略,GPC 都能将它们的优势汇聚到一个更强大的组合策略中。
统一的分数凸组合机制
这种机制通过凸组合的方式,有效地平衡了来自不同条件的信息,使合成的决策分数保持在个体策略的可行凸包内,从而避免了策略执行中的极端或不稳定行为,生成更稳定、更连贯的动作轨迹。
GPC 与 Superposition(叠加原理)的扩展
除了核心的凸组合方式外,GPC 框架还自然地连接了叠加原理(Superposition),提供了更强大的组合操作符。
Logical OR(逻辑或):对应于从混合分布中采样。它通过使用 softmax 函数来加权,从而确定每个策略分数在采样时间步中的相对贡献。
Logical AND(逻辑与):对应于分布的交集,旨在强制各策略之间达成一致性。它通过求解一个线性系统来计算权重,确保在采样过程中不同策略保持一致。
这些扩展的组合操作符(Logical OR 和 Logical AND)为 GPC 提供了放大策略性能的潜力,能够通过更强的约束或混合机制来进一步提升控制效果。
权重搜索
为不同任务 “量身定制” 最优策略
GPC 框架的权重搜索机制,能为每一次策略组合找到最优的权重配置,从而为不同的任务和场景 “量身定制” 出最强的 “组合策略”。这一机制建立在严谨的理论分析之上,证明了最优权重的存在性,而广泛的实验则揭示了权重分配的关键作用。

通过在测试时(test-time) 对组合权重进行搜索,GPC 能够灵活地适应各种任务场景,持续地实现性能提升。以下是实验中总结出的三大核心发现:
发现 1:捕捉更广阔的通用分布 当被组合的两个策略都具有中等(例如,高于 30%)的准确率时,GPC 在适当的权重配置下,通常能实现比单一基线策略更高的准确率。这种性能的提升,反映了组合后的分数分布捕捉到了更广义的分布,减少了对特定条件下的单一决策的依赖。
发现 2:避免弱策略的负面影响 实验表明,当其中一个策略的准确率显著较低时,GPC 难以超越表现最好的那个基线策略的峰值性能。这提示了来自低准确率模态的分数可能会显著干扰联合分布,从而降低整体组合策略的表现。
发现 3:强策略主导最优结果 GPC 性能的提升总是伴随着表现较好的基线策略获得更大权重时被最大化。这一发现强调了为强分布分配更高权重的必要性,它能有效地将组合策略的决策导向更可靠的“共识区域”,从而最大化 GPC 的有效性。
这些发现共同强调了 GPC 在利用不同条件策略优势方面的通用性,以及适当调整权重以适应每个策略性能的重要性。
实验验证
从仿真到真实世界
经过严格测试,GPC 在仿真与真实环境中均展现出超越单一基线方法的性能.
仿真环境测试:在 Robomimic、PushT 和 RoboTwin 等多个主流仿真测试平台上,GPC 的应用带来了显著的性能提升。与单一基线模型相比,GPC 策略在 Robomimic 和 PushT 任务上实现了最高 7.55% 的平均成功率提升,在复杂的 RoboTwin 双臂协作任务上提升了 7%。这表明 GPC 不同任务执行的有效性上表现出色,为实际应用节省了大量的时间和资源。

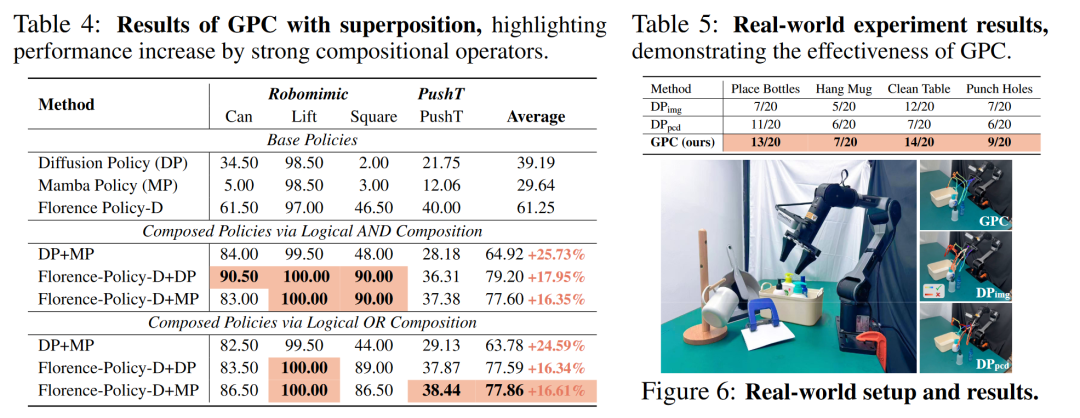
真实世界:我们采用 PiPER 机器人进行了真机实验。如 Table 5 所示,在 4 个实际任务中,GPC 在每个任务对比单一基线成功率拥有 5-10% 的提升,展示了在真实环境中 GPC 框架的提升策略性能的能力。
下面展示了清理桌面的真机视频:
DP 失败 ❌
DP3 失败 ❌
GPC 成功 ✅
想了解更多关于 GPC 的详细信息,可访问项目主页:
https://sagecao1125.github.io/GPC-Site/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










