点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
近年来,Sim2Real作为连接仿真环境和真实三维世界的主要桥梁,在越来越多的应用(如具身智能,虚拟现实)中扮演着至关重要的角色。在这一背景下,一个基本问题是——如何模拟和仿真真实捕获的三维数据。为了解决这个问题,现有多数方法将预定义的显式物理先验引入到仿真深度传感器中,以模拟真实的深度传感器,但这种方式难以充分捕捉真实世界的复杂性。最优解决方案应通过数据驱动的方式学习从合成数据到真实数据的隐式映射,遗憾的是,这一方案的研究近年来陷入了停滞。
为了重新推动这一研究方向的进展,港中大(深圳)韩晓光团队提出了Stable-Sim2Real,探索了一种数据驱动3D模拟的新路径——Stable-Sim2Real。其基于一种新颖的两阶段深度图扩散模型,采用一阶段稳定生成+二阶段局部增强。实验表明,使用该方法生成的三维模拟数据训练模型,能显著提升在真实世界下三维视觉任务的性能。目前论文和代码已经在项目主页公开,欢迎大家一起探索!

论文标题:Stable-Sim2Real: Exploring Simulation of Real-Captured 3D Data with Two-Stage Depth Diffusion
论文地址:https://arxiv.org/abs/2507.23483
项目主页:https://mutianxu.github.io/stable-sim2real/
项目代码:https://github.com/GAP-LAB-CUHK-SZ/stable-sim2real


背景介绍
近年来,真实世界三维数据集在解决三维视觉与机器人学领域的广泛任务中发挥着至关重要的作用。然而,真实三维数据的采集往往需要耗费大量人力与时间,且近年来日益凸显的数据隐私问题进一步增加了数据收集的复杂性。在此背景下,合成数据(即通过模拟生成的数据)作为一种替代性数据资源应运而生,其具有成本效益高、生成速度快且可规模化生产的优势。尽管如此,基于合成数据训练的模型在真实世界中的表现缺乏鲁棒性。
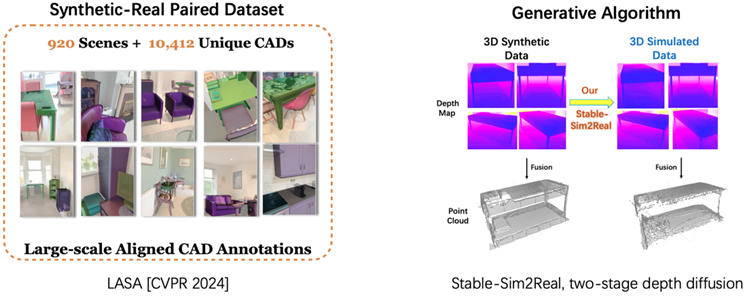
这一问题催生了三维数据仿真技术的发展,旨在缩小仿真数据与真实采集三维数据之间的差距。尽管已有研究尝试通过引入物理先验知识来模拟深度传感器,但由于依赖预定义的显式物理建模,这些方法难以捕捉真实世界的全部复杂性。更优的解决方案是以数据驱动的方式学习从合成数据到真实数据的隐式映射,从而更好地适应现实世界的多样性。然而,受限于数据的匮乏和早期模型的能力,仅有少数现有工作探索这一路径,相关的进展陷入了停滞状态(图2)。

本工作旨在探索数据驱动的三维仿真到真实(Sim2Real)转换方法,并推动学术界重新关注这一关键问题。本工作选用最新的合成-真实配对数据集LASA(图3),该数据集包含10,412个与真实物体扫描数据精确配准的高质量三维形状CAD标注。以LASA数据集为驱动,本工作的研究重点在于设计一种高效的数据驱动三维Sim2Real算法。鉴于真实采集数据模式固有的不确定性和多样性,本工作选用扩散模型进行生成。然而,由于三维数据的匮乏,训练三维扩散模型以获得强三维先验知识用于三维仿真仍存在困难。因此,本工作选择利用二维扩散基础模型(如SD——Stable Diffusion)的强泛化先验来模拟真实二维深度图,继而通过融合生成三维数据。这一策略与真实三维数据采集过程相似,即通过采集二维深度信息并融合成三维数据。
核心挑战与方法
为了实现这一方案,一个直观的baseline方法是从LASA数据集中获取CAD(即合成)深度图及其配对的真实深度图像,然后对Stable Diffusion(SD)模型进行微调,以学习二者之间的隐式映射。然而,本工作面临特殊挑战(图4):传统图像转换通常通过去除噪声来生成清晰图像,而本工作的任务目标却是输出具有高度不确定性的含噪声深度数据,这使得需要学习的分布规律变得更为复杂。


为应对这些挑战,本工作提出Stable-Sim2Real(如图5所示)。在第一阶段扩散过程中,模型并非直接生成对应的真实世界深度图,而是生成真实深度图与CAD深度图之间的残差(即差异值)。随后通过将生成的残差与CAD深度图相加,得到模拟的深度图。与直接生成含噪声的真实深度相比,向本身干净且视角一致的CAD深度添加噪声,能够产生更稳定的深度数据——其视角变化更小,且能更好地保持原始几何结构(详细讨论与概率分析见原文)。
尽管第一阶段生成的深度图中某些区域成功拟合了真实的pattern,但部分局部区域仍存在生成结果与真实采集数据间显著的几何差异。为解决该问题,模型在第二阶段训练了一个三维感知判别器(3D-Aware Discriminator,仅在训练时使用),在局部几何层面区分第一阶段生成结果与真实采集数据,随后通过调整扩散损失函数,对第一阶段生成结果进行局部增强。最终,将生成的深度图融合以得到模拟三维数据。
实验与验证
首先,本工作提供了三维数据仿真的直观效果对比,其中Stable-Sim2Real更贴近真实世界扫描的三维数据,并且在out-of-domain (e.g. ShapeNet, ABO, 3D-Future)的合成数据上也展现出了极佳的泛化性(图6,7)。


此外,针对于下游应用,本工作提出了一套针对三维数据仿真的综合基准测试方案:若使用生成的仿真数据训练模型后能在真实世界中的性能得到提升,则验证了仿真方法的有效性。聚焦于两个基础性真实世界三维任务:三维形状重建与三维物体/场景理解(图8)。
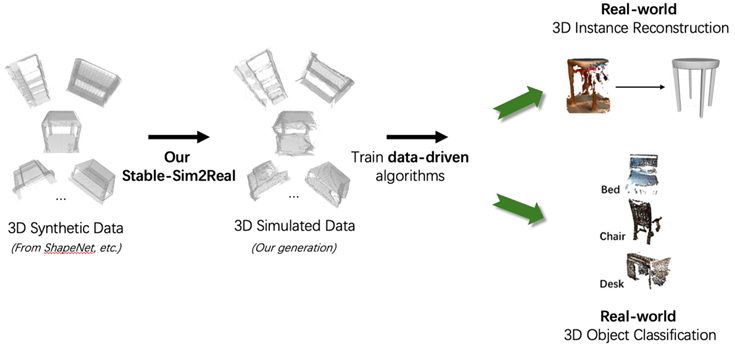
对于三维形状重建任务,预训练一个以生成的仿真三维数据为输入、输出干净三维表面的重建网络。对于三维物体/场景理解任务,生成的三维仿真数据被用于预训练自监督点云学习框架。为更纯粹地评估生成的仿真数据带来的性能增益,本工作对预训练网络进行少样本评估,有效剥离其他干扰因素,直接衡量生成的仿真数据对模型性能的提升贡献。



思考与展望

本研究所提出的"clean-to-noisy"的方法,本质上将服务于提升"noisy-to-clean"这一逆问题的求解效果。其背后的主要原因是:训练"noisy-to-clean"模型仍需大规模clean-noisy配对数据。而获取/扩增此类配对数据时,本方法恰好提供了合理的解决方案:通过易于获得的合成数据生成难以采集的真实noisy数据。最终,该方法填补并完善了"clean-noisy-clean"的闭环流程。从更宏观的角度来看,这实则构成了"真实→仿真→真实"(Real2Sim2Real)的完整技术闭环(图10)。更多实验细节请参阅原论文。
3D视觉1V1论文辅导来啦!

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001











