

今天,AI圈知名的新锐独角兽Thinking Machines Lab正式上线了旗下的研究博客:联结主义(Connectionism),并发布公司成立以来的第一篇技术博文“克服LLM推理中的不确定性”。
“联结主义”这个名字来自人工智能早期时代,它是20世纪80年代研究神经网络及其与生物大脑相似性的子领域的名称。
Thinking Machines官方表示,“联结主义”涵盖的主题将与团队的研究范围一样广泛:从核心数值到即时工程,在这里,他们将分享内部的最新科研成果和技术见解,并与AI技术社区保持频繁且开放的联系。
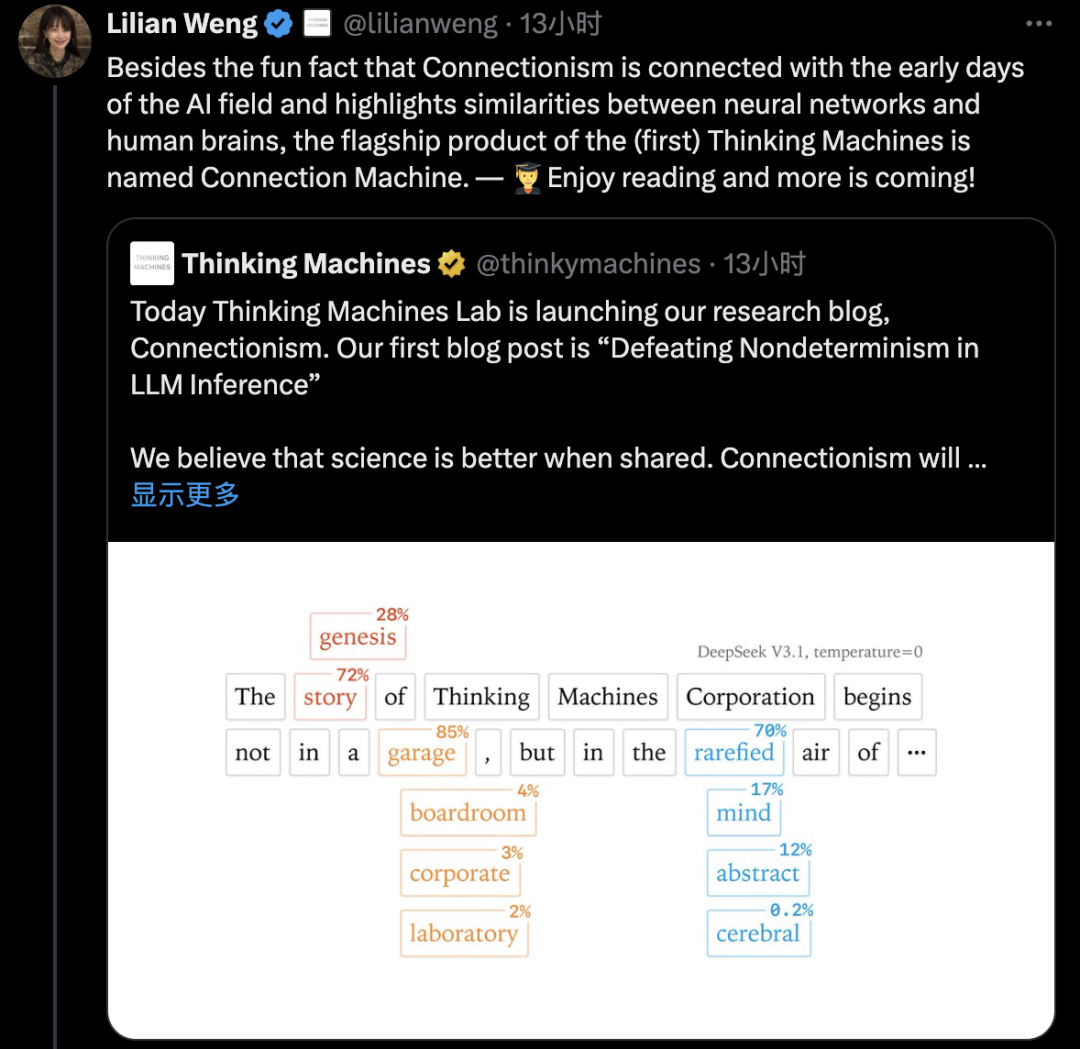









研究人员经过深入研究发现,几乎所有LLM推理端点都具有不确定性的主要原因是负载(以及批次大小)的变化具有不确定性,这种不确定性并非GPU独有——由CPU或TPU提供服务的LLM推理端点也存在这种不确定性。
因此,如果我们想避免推理服务器中的不确定性,就必须在内核中实现批量不变性,批次不变性的要求是,无论内核的批次大小如何,每个元素的缩减顺序都必须固定。
如何使内核具有批次不变性?文章提到了三种技术措施:

1、RMSNorm:每个核心“承包”一个请求
简单来说,这个解决思路是:一个核心专门处理一个请求的计算,不管批次多大,每个请求的合并顺序都固定,就算批次小导致有些核心空闲,也不随便拆分工(避免改变计算顺序)。
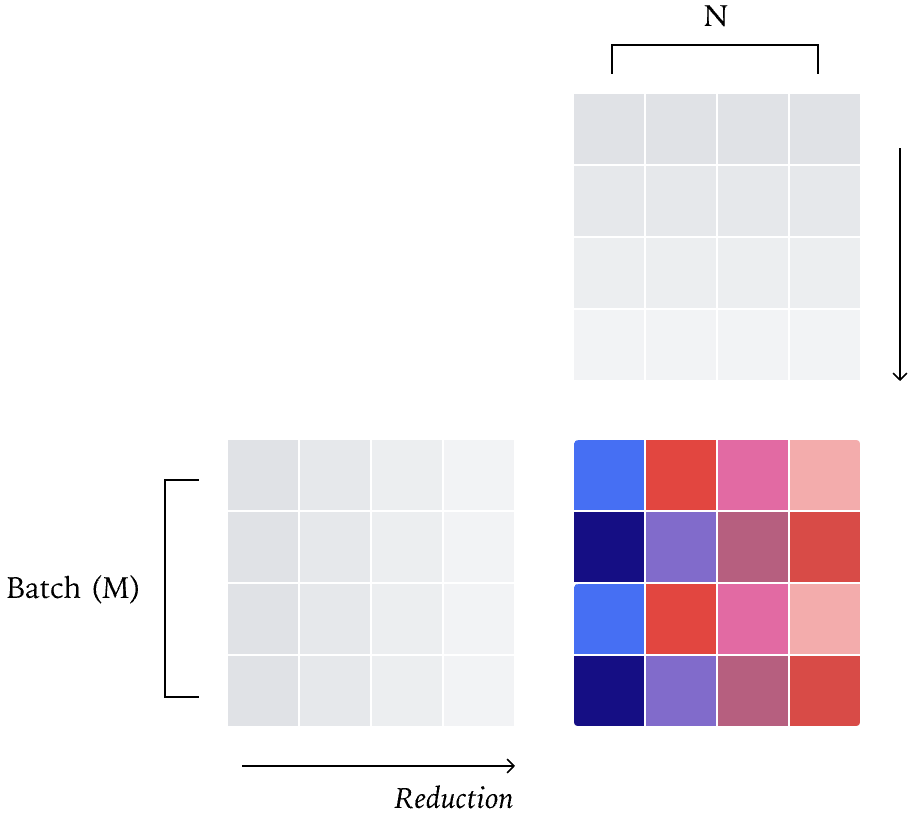
2. 矩阵乘法:固定计算“模板”
矩阵乘法是模型的核心运算,为了快,会把大矩阵切成小“瓷砖”(tile)计算。
解决思路:不管批次大小,都用同一种tile尺寸和计算配置——哪怕批次小的时候有点慢,也不换策略,保证计算方式统一。

3、注意力机制:处理好“历史缓存”,固定分割规则
解决思路:不按“拆几份”来分,而是按“每份固定大小”来分。比如不管批次多大,都按250个单位为一份拆缓存,剩下的零头单独算——这样合并顺序永远固定,结果就一致了。
经过一系列优化,作者用Qwen大模型做了测试实验,当启用批不变内核时,所有1000个完成结果都是相同的。不过,性能上会慢一点,比如vLLM默认26秒跑完1000个请求,优化后42秒。

速度变慢的主要原因是vLLM中的FlexAttention集成尚未进行深度优化,尽管如此,但仍然看到性能表现并不糟糕。
而且这些解决方法还有一个额外的好处,可以让RL训练更稳定。
之前因为训练和推理的输出数值有差异,导致RL变成了“离线训练”(用旧数据练新模型),容易崩;现在输出可重复了,训练和推理的数值完全一致,就能实现“在线训练”(用模型实时输出练模型),奖励和稳定性都好了很多。

Thinking Machines Lab团队表示,希望这篇博文能让技术社区对如何解决AI推理系统中的不确定性有一个扎实的理解,并激励其他人全面理解他们的AI系统。

-END-

如果您有什么想说的,欢迎在评论区留言讨论! 投稿或寻求报道,欢迎私信“投稿”,添加编辑微信。 【2025免费新年礼】:了解最新科技趋势分析、行业内部的独家见解、定期的互动讨论和知识分享、与行业专家的直接面对面交流的机会,领取100份AI科技商业研报合集,加群共同探讨与成长—— 扫描下方二维码,添加头部科技晶总微信! 










