点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
1. 导读
点云是一种常见的3D表示形式,能够捕捉丰富的几何结构,因此在自动驾驶、机器人、虚拟现实等领域得到了广泛应用。但点云标注困难,导致有监督学习很难大规模应用,自监督学习逐渐成为主流。
现有的生成式自监督方法,如 Point-MAE,通过在同一视图内进行掩码重建(Self-Reconstruction)来学习特征。模型需依赖局部几何结构补全缺失部分即可。然而,这种单视图内部的“自重建”(Self-Reconstruction)任务是否足够具有挑战性?它能否驱动模型学习到更深层次、更泛化的3D语义信息?
本文指出,自重建范式的大部分方法,比如Point-MAE,在同一视图内补全被掩码的点,模型只需捕捉单视图内的局部几何结构,可变性较低,任务不够有挑战性。在图像领域,比如对比学习(MoCo, SimCLR)等方法已经证明双视图相比于单视图能给训练带来更多可变性与挑战性,从而迫使模型学习更加语义丰富的表征,进而提高性能。
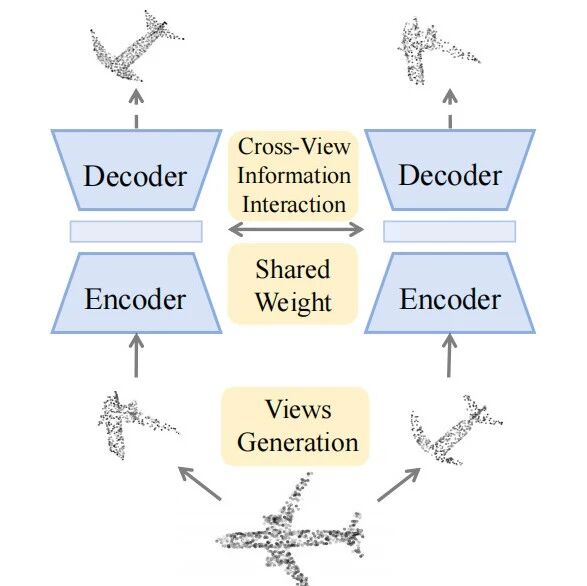
对此,本文提出了一个根本性的问题:点云生成式自监督学习是否必须局限在单视图内进行重建?答案是:不必。Point-PQAE通过交叉双视图重建,直接打破了这一限制。该方法首次将双视图生成与跨视图重建这种全新范式引入点云生成式自监督学习,显著提升了任务的挑战性与信息量,推动点云表征学习进入新阶段。Point-PQAE已经被计算机视觉领域顶会ICCV 2025接受。范式对比如下图。

论文链接:https://arxiv.org/abs/2509.01250
代码链接:https://github.com/aHapBean/Point-PQAE
2. 效果展示
Point-PQAE 跨视图重建可视化效果如下:

从图中可以看到,点云重建效果良好,且重建能够泛化到各个crop ration之下。
3. 主要贡献
本文的主要贡献如下:
1. 首创跨视图生成式预训练范式:提出双视图交叉重建任务,突破以往仅限单视图自重建的限制,实现了更加具有挑战性的点云自监督预训练。
2. 解耦视图生成策略:通过随机裁剪 + 归一化 + 旋转生成互相独立的 partial views,避免模型学到数据增强的捷径。本文首次提出并在点云自监督领域应用了随机裁剪机制。
3. 跨视图建模模块:提出视图相对位置嵌入(VRPE)与位置查询模块(PQ Block),显式建模跨视图几何关系并高效完成特征对齐。
4, 显著性能提升:在分类、few-shot、分割等任务上全面超越 Point-MAE,并接近甚至媲美跨模态 SOTA 方法。
4. 方法
Point-PQAE 的整体框架如下图所示。输入点云首先经过随机裁剪与旋转生成两个解耦子视图,然后划分为 patch 并编码为 token。编码后的特征通过本文提出的位置查询模块(PQ Block)进行跨视图交互,其中视图相对位置嵌入(VRPE)作为查询向量,用于显式建模视图间的几何关系。最后,经过解码器输出预测点云,完成跨视图重建任务。

解耦视图生成(Decoupled Views Generation)与传统单视图掩码不同,Point-PQAE 引入了随机裁剪机制,为每个点云生成两个独立视图。这是点云自监督领域首次应用随机裁剪。具体做法是:在输入点云上随机选择裁剪比例 ,并各自随机采样中心点 。随后扩展最近邻点形成子点云 :
其中 是最小裁剪比例。随后对子视图做 min-max 归一化并以几何中心 为原点,同时施加随机旋转,从而彻底解耦两视图的坐标系。
Patch 划分与嵌入(Patch Generation & Embedding) 为了在 Transformer 中高效处理点云,Point-PQAE 将子视图划分为 patch。采用 FPS 采样 个中心点 ,并对每个中心点使用 KNN 聚合得到 patch :
每个 patch 经 PointNet 轻量嵌入为 token 序列,作为 Transformer 编码器输入。
编码与潜在表示(Encoding) 通过轻量级 PointNet 和 Transformer 编码器,得到两个视图的潜在表示:
其中 , 是隐藏维度。
视图相对位置嵌入(View-Relative Positional Embedding, VRPE) 为了实现跨视图重建,需要建模两视图间的相对几何关系。以从视图1重建视图2为例,定义它们的几何中心差:
再结合 patch 中心位置,构造 patch 级的相对位置:
随后使用正弦编码生成 VRPE:
作为跨注意力的查询向量。
位置查询模块(Positional Query Block, PQ Block) 在 PQ Block 中,VRPE 被作为 Query,而源视图的潜在表示作为 Key 和 Value,进行跨注意力:
这样,模型便能显式对齐跨视图几何关系,从视图1推理视图2。对称地,也可得到 。
解码与重建(Decoder & Reconstruction) 经过 PQ Block 的表征 输入解码器:
最后通过线性投影预测点云 patch:
训练目标(Training Objective) Point-PQAE 采用双向 Chamfer-L2 距离作为重建损失:
这一目标驱动模型在预训练阶段学习到更丰富的几何与语义特征。
5. 实验结果
本文提出的 Point-PQAE 在下游任务中的表现大幅超越了传统 Self-Reconstruction 范式的代表方法 Point-MAE,并且与当前 SOTA 的跨模态方法性能相当。具体结果如下:
ScanObjectNN(真实场景点云分类):在 OBJ-BG、OBJ-ONLY 和 PB-T50-RS 三个变体上均优于 Point-MAE。尤其在 Frozen(MLP-LINEAR)评估中,Point-PQAE 的表现提升显著,例如线性探测从约 **82.8% → 89.3%**,表明其预训练表征具有更强的线性可分性。 ModelNet40(CAD 物体分类):在 1K 和 8K 点数设置下,Point-PQAE 表现同样良好,整体结果与 Point-MAE 相比持平或略优。 Few-shot Learning:在 5-way/10-way 的 10/20-shot 设置下,Point-PQAE 均超越 Point-MAE,部分设置下提升幅度显著,显示出更强的泛化能力。 Segmentation(ShapeNetPart / S3DIS):在 Cls.mIoU、Inst.mIoU、mIoU 等指标上均有稳健提升,其中场景语义分割任务也观察到 0.6% ~ 0.7% 的性能增长。



本文也进行了详尽的消融实验分析,包括:
VRPE 设计:用 sinusoid VRPE 优于 learnable VRPE 和无 VRPE,表明固定的频率编码有利于刻画相对位置时的稳定性。 augmentation 比较:在裁剪后,rotation 对性能贡献最大;jitter/scale 等联合使用并不能取代 rotation 的效果。 裁剪机制的重要性:若移除 crop(只做归一化/旋转),两视图会保留过强的对应性,cross-reconstruction 退化为“学习数据增强”而无益。实验表明 crop + normalization + rotation 的组合能最大化视图解耦与信息量。 视图解耦的有效性:在独立裁剪后,需要进行norm. + rotation两步数据增强,独立增强两个裁剪后的点云,以让两个点云的坐标系以及相对关系解耦,为交叉视图重建做准备。消融实验证明了这种解耦操作的有效性。

6. 总结
Point-PQAE 抛弃了“只在单视图内做自重建”的传统思路,提出了基于解耦视图生成 + 相对位置编码 + 位置查询的 cross-reconstruction 框架。该方法从任务设计上增加了预训练的难度与信息量,使模型在预训练中必须学会跨视图的几何关系与语义对应,得到了语义更加丰富的表征,最终在下游点云分类、few-shot、分割等任务上均取得显著提升。
3D视觉1V1论文辅导来啦!
3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001