
本文由 Intern-S1、Qwen3 等 AI 生成, 由机智流编辑部校对

在人工智能与机器人技术迅猛发展的今天,如何让机器人更高效、更智能地理解环境、执行任务,成为了学术界与工业界共同关注的焦点。传统的视觉-语言-行动(Vision-Language-Action, VLA)模型虽然在机器人操作领域展现了强大的潜力,但往往依赖大规模预训练模型和高昂的计算成本,这无疑为实际应用设置了高门槛。
近日,由西湖大学、北京邮电大学、浙江大学和香港科技大学(广州)等顶尖机构联合研发的VLA-Adapter模型,以其5亿参数量的轻量化的设计和卓越的性能,为机器人领域的VLA模型带来了革命性的突破。这款模型不仅在性能上媲美甚至超越现有顶尖方案,还大幅降低了训练和部署的门槛,堪称机器人智能领域的里程碑式创新。
本文将带您深入了解VLA-Adapter的独特魅力,从其核心创新到实验成果,再到实际应用的潜力,为您揭开这一前沿技术如何为机器人赋予更高效的感知与行动能力。

先搞懂现有衔接视觉语言和动作的范式
在VLA模型的发展历程中,如何有效桥接视觉-语言(VL)感知空间到行动(A)空间一直是核心挑战。早期研究尝试通过直接对齐感知与行动空间来实现这一目标,例如将行动离散化为令牌进行对齐,但这种方法不可避免地引入了内在损失,导致行动表示不够精确。随着技术进步,研究者们转向连续行动空间,并根据用于桥接的感知特征类型,将现有范式大致分为两大类:基于VLM原始特征的桥接和基于额外查询作为接口的桥接。
 图1:现有从视觉语言到行动的代表性桥梁范式示意图,展示了原始特征和额外查询接口的典型方法。
图1:现有从视觉语言到行动的代表性桥梁范式示意图,展示了原始特征和额外查询接口的典型方法。
首先,基于VLM原始特征的桥接范式直接从视觉-语言模型中提取视觉和语言表征,作为行动生成的条件。早期方法倾向于使用VLM的最终层特征,认为这些层编码了最相关的语义信息,从而有助于任务执行。然而,后续研究发现,中间层特征往往保留了更丰富的多模态细节,对需要精细感知或复杂推理的任务更有益。例如,一些工作利用VLM的中间层特征,如中间单层、浅层一半或所有中间层特征,来增强策略网络的行动生成能力。这种范式的优势在于其简单性和直接性,但也面临特征提取的层级选择问题,以及在高维环境中可能的信息丢失。
其次,引入额外查询作为接口的范式则代表了更先进的桥接方式。这种方法不再依赖原始特征,而是使用可学习的查询作为VL与行动空间之间的桥梁。这些查询能够动态融入多模态信息,并在训练过程中优化,从而在性能上超越传统原始特征方法。双系统 VLA(dual-system VLA)架构的相关工作(Shentu et al., 2024; Bu et al., 2024a; Cui et al., 2025)显示,这种接口设计能够更好地捕捉任务相关性,并通过异步机制缓解行动生成中的延迟问题。总体而言,这些现有范式为VLA模型的设计提供了基础,但仍存在对大规模VLM的依赖和效率瓶颈等问题,这也正是VLA-Adapter试图解决的核心痛点。
创新核心:轻量化与高效性的完美结合
VLA-Adapter的核心目标是解决传统VLA模型在高维控制环境中的两大瓶颈:对大规模视觉-语言模型(VLM)的依赖和高计算成本。研究团队通过系统性地分析视觉-语言(VL)表征到行动(A)空间的桥梁机制,提出了一种全新的桥接范式——VLA-Adapter。这种范式通过轻量化的策略,成功将多模态信息高效传递到行动空间,显著降低了模型规模和训练成本。
传统VLA模型通常需要依赖大规模的机器人数据集(如Open X-Embodiment和DROID)进行预训练,以确保模型能够适应多样化的任务环境。然而,这种方法不仅需要耗费大量计算资源,还会导致训练时间长、推理速度慢、GPU内存占用高等问题。VLA-Adapter则另辟蹊径,通过一个仅0.5亿参数的骨干网络(在 Qwen2.5-0.5B 上训练的 Prismatic VLM[1]),无需机器人数据预训练,即可实现与70亿参数模型相媲美的性能。这种轻量化设计不仅降低了硬件需求,还将训练时间缩短至仅8小时,使用单张消费级GPU即可完成,极大地降低了VLA模型的部署门槛。
关键技术:桥接注意力机制
VLA-Adapter的成功离不开其创新的桥接注意力(Bridge Attention)机制。研究团队深入探讨了视觉-语言表征对行动生成的影响,并提出了几个关键发现:
中层特征更优:相比于VLM的深层特征,中层特征能够更好地整合图像和文本信息,保留更丰富的多模态细节,从而在行动生成中表现更佳。 动作查询的深层优势:通过引入可学习的动作查询(ActionQuery),深层特征能够更有效地促进行动生成,相较于浅层特征具有更强的聚合能力。 全层特征的普适性:使用全层特征不仅提升了性能,还避免了选择最优特征层的繁琐过程,使模型设计更具通用性。
基于这些发现,VLA-Adapter设计了一个轻量级的策略网络(Policy Network),通过桥接注意力模块将视觉-语言表征与动作空间高效连接。桥接注意力模块包含两次交叉注意力和一次自注意力,通过可学习的参数动态调节特征注入比例,确保训练的稳定性和性能的优化。这一机制使得VLA-Adapter能够在极小的模型规模下,依然实现高效的动作生成。
 图2:VLA-Adapter框架示意图。关键组成部分是有效的条件探索和注意力设计。“注意力” 具体包括与条件相关的交叉注意力以及自身的自注意力。右图给出了关于 “层” 和 “类型” 的四个条件。
图2:VLA-Adapter框架示意图。关键组成部分是有效的条件探索和注意力设计。“注意力” 具体包括与条件相关的交叉注意力以及自身的自注意力。右图给出了关于 “层” 和 “类型” 的四个条件。
训练效率:单GPU,8小时完成
VLA-Adapter的另一个亮点是其高效的训练流程。研究团队采用端到端的训练方式,仅对策略网络和动作查询(ActionQuery)进行从头训练,而无需对骨干VLM进行微调。这种设计不仅降低了计算需求,还显著缩短了训练时间。实验显示,VLA-Adapter在单张NVIDIA H100 GPU上仅需8小时即可完成训练,相比传统VLA模型动辄数天甚至数周的训练时间,这无疑是一大突破。此外,模型的推理速度也令人印象深刻,其吞吐量高达219.2Hz,延迟仅为0.0365秒,远超现有模型,为实时机器人应用提供了坚实的基础。
实验验证:性能与效率的双赢
为了全面验证VLA-Adapter的性能,研究团队在多个机器人任务基准上进行了广泛的实验,包括模拟环境和现实世界的测试。这些实验不仅展示了VLA-Adapter的卓越性能,还凸显了其在轻量化设计下的高效性和泛化能力。
模拟环境:LIBERO与CALVIN的优异表现
在LIBERO基准测试中,VLA-Adapter在Spatial、Object、Goal和Long四个任务套件上均表现出色,平均成功率达到97.3%,超越了包括OpenVLA-OFT(70亿参数)和SmolVLA(22亿参数)在内的多个基线模型。尤其在长时程任务(LIBERO-Long)中,VLA-Adapter以95.0%的成功率,领先同等规模的VLA-OS模型29.0%,展现了其在复杂任务上的强大能力。
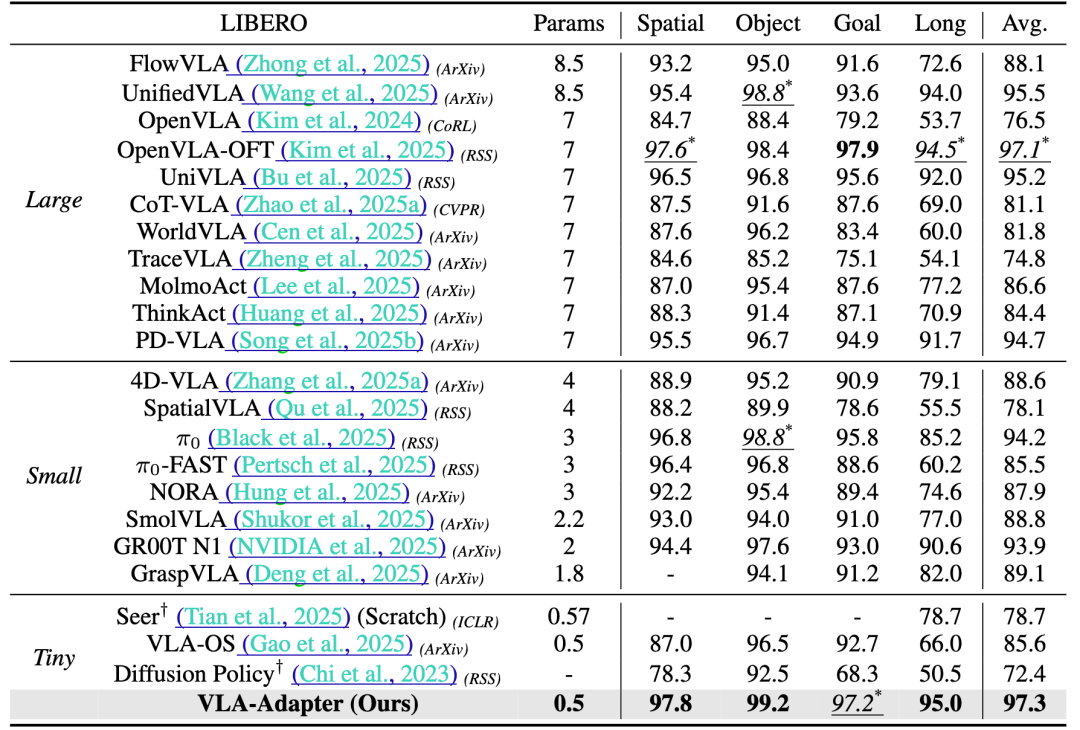 图3:LIBERO 基准测试的对比。粗体表示最佳性能。斜体 * 表示次优性能。†代表非基于视觉语言模型(VLM)的基线。“Scratch” 指未在机器人数据上进行预训练的工作。“Params” 指主干网络规模,其单位为 “十亿”。
图3:LIBERO 基准测试的对比。粗体表示最佳性能。斜体 * 表示次优性能。†代表非基于视觉语言模型(VLM)的基线。“Scratch” 指未在机器人数据上进行预训练的工作。“Params” 指主干网络规模,其单位为 “十亿”。
研究团队还使用了 CALVIN ABC→D(Mees 等人,2022)来评估在零样本泛化任务上的性能。CALVIN 包含四个环境(环境 A、B、C 和 D)。“ABC→D” 意味着在环境 A、B 和 C 上进行训练,在环境 D 上进行评估。VLA 需要依次执行 1000 个预设的任务序列。每个任务行包含五个子任务。模型只有完成当前子任务后才能进入下一个子任务。
在CALVIN ABC→D 零样本泛化任务中,VLA-Adapter同样表现出色,平均任务完成长度达到4.42,超越了包括UniVLA和OpenHelix在内的多个大型模型。这一结果表明,VLA-Adapter在未见环境下的泛化能力极强,能够灵活应对多样化的任务需求。
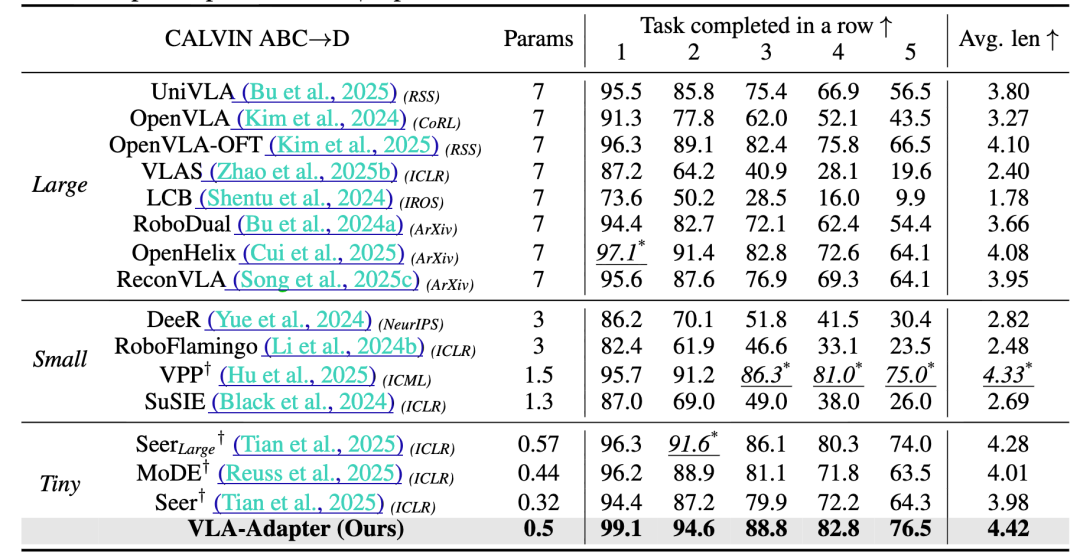 图4:在 CALVIN ABC→D 基准上的比较。粗体表示最佳性能。斜体 * 表示次优性能。†代表非基于视觉语言模型(VLM)的方法。
图4:在 CALVIN ABC→D 基准上的比较。粗体表示最佳性能。斜体 * 表示次优性能。†代表非基于视觉语言模型(VLM)的方法。
现实世界:多样化任务的稳健表现
在现实世界的机器人任务中,VLA-Adapter使用6自由度的Synria Alicia-D机器人,配备Logitech C920e和RealSense D405相机,完成了包括简单拾取放置、块体侧向移动、块体堆叠以及复杂长时程任务等多种实验。测试中,研究团队通过随机化对象位置增加了任务难度,以评估模型的泛化能力。结果显示,VLA-Adapter在各类任务中均表现出优异的成功率,超越了ACT和OFT-style基线,展现了其在实际应用中的强大潜力。

 图5:VLA-Adapter在现实世界任务中的执行示例,展示了其在复杂任务中的高效性和稳定性。
图5:VLA-Adapter在现实世界任务中的执行示例,展示了其在复杂任务中的高效性和稳定性。
消融实验:关键组件的优化
为了进一步验证VLA-Adapter的设计合理性,研究团队进行了消融实验,探索了动作查询数量、条件类型和特征注入比例等关键组件的影响。实验结果表明,64个动作查询能够平衡性能与效率,而全层特征的结合显著提升了模型的鲁棒性。这些发现为VLA-Adapter的优化设计提供了坚实的理论依据。
实际应用潜力:降低门槛,赋能未来
VLA-Adapter的轻量化设计和高效率使其在实际应用中具有巨大的潜力。无论是工业自动化、智能家居,还是医疗辅助机器人,VLA-Adapter都能以更低的硬件成本和更快的部署速度,为各种场景提供高效的机器人解决方案。其无需大规模预训练的特点,也让中小型研究机构和企业能够更轻松地开发和部署VLA模型,极大地推动了机器人技术的普及和应用。
此外,VLA-Adapter的高推理速度和低延迟使其特别适合需要实时响应的场景,例如自动驾驶、物流机器人和交互式服务机器人。研究团队还提供了开源项目页面(https://vla-adapter.github.io/ ),方便开发者获取模型详情和代码,进一步促进了技术的共享与创新。
结论:机器人智能的未来之路
由西湖大学等机构联合研发的VLA-Adapter,以其创新的桥接范式和轻量化设计,为VLA模型的发展开辟了新路径。它不仅在性能上媲美甚至超越了大规模模型,还通过高效的训练和推理流程,显著降低了机器人智能技术的应用门槛。无论是模拟环境中的复杂任务,还是现实世界中的多样化挑战,VLA-Adapter都展现了其卓越的适应性和稳定性。
未来,随着VLA-Adapter的进一步优化和应用,我们有理由相信,机器人将变得更加智能、灵活和普及,为人类生活带来更多便利。这项由西湖大学、北京邮电大学、浙江大学和香港科技大学(广州)联合推出的技术,不仅是学术界的突破,更是机器人产业迈向实用化的重要一步。
 图6:冻结骨干时VLA-Adapter与OpenVLA-OFT的执行示例,展示了VLA-Adapter在无需预训练时的优异性能。
图6:冻结骨干时VLA-Adapter与OpenVLA-OFT的执行示例,展示了VLA-Adapter在无需预训练时的优异性能。
在 Qwen2.5-0.5B 上训练的 Prismatic VLM: https://arxiv.org/pdf/2411.02359
-- 完 --
机智流推荐阅读:
1. LangChain 新一代记忆管理:RunnableWithMessageHistory 全面解析与实战
2. IJRR2025|万字长文解读视觉RL在多目标操作中的痛点与ASIMO的突破
3. 128K上下文+100轮工具调用!港科大联合MiniMax推出WebExplorer-8B,登顶6大信息检索基准
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










