🔥论文选自 Hugging Face 本周论文,解读由 Intern-S1 生成可能有误!
(1) Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing
论文简介:
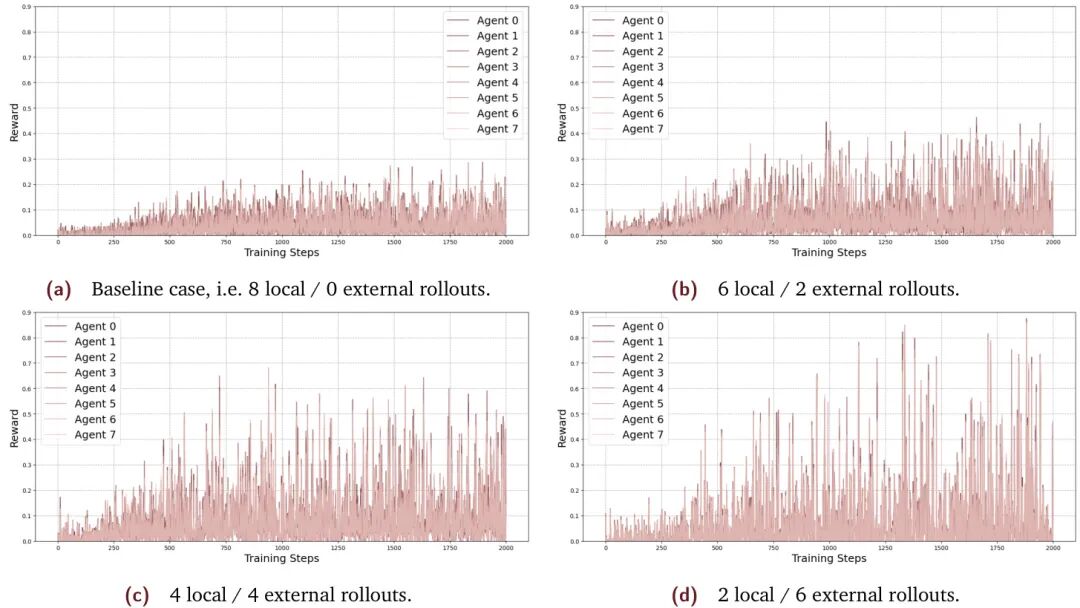
由Gensyn AI Team等机构提出了SAPO(Swarm sAmpling Policy Optimization),该工作提出了一种去中心化异步强化学习后训练算法,通过异构计算节点网络实现语言模型(LM)的高效后训练。SAPO允许各节点独立管理策略模型,同时共享解码后的rollouts(如纯文本形式),从而避免传统分布式RL的通信瓶颈和硬件依赖。在控制实验中,SAPO通过平衡本地与共享rollouts(4:4比例)使累计奖励提升94%,并展现出更强的样本效率和任务性能。其核心机制是通过经验共享传播"Aha时刻",加速学习过程,同时无需同步权重或硬件一致性要求。在开源演示中,数千个社区贡献的异构节点(运行小语言模型SLM)验证了SAPO的可扩展性,结果显示中等容量模型(如0.5B参数Qwen2.5)在群体训练中显著优于孤立训练,而更强模型(如0.6B参数Qwen3)的性能差异则趋于平缓。研究还揭示过度依赖外部rollouts可能导致学习震荡,未来需探索动态采样策略和混合方法以提升稳定性。SAPO为低成本、去中心化增强模型推理能力提供了新范式,其跨模态特性也为多智能体协作学习开辟了新方向。
论文来源:hf
Hugging Face 投票数:464
论文链接:
https://hf.co/papers/2509.08721
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.08721
(2) VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
论文简介:
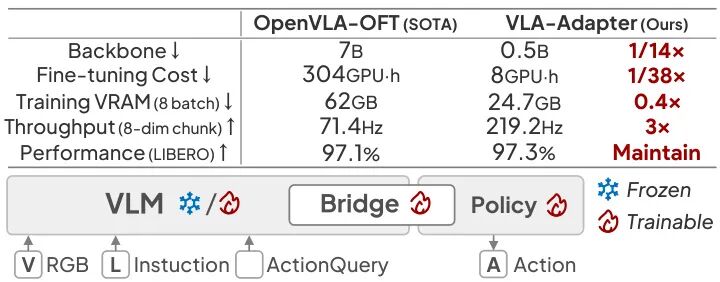
由西湖大学、北京邮电大学等机构提出了VLA-Adapter,该工作通过系统分析视觉-语言到动作空间的桥接范式,提出了一种轻量级的视觉-语言-动作模型架构。研究发现中间层视觉特征与深度层查询特征的协同作用能有效提升动作生成质量,进而设计了包含桥接注意力机制的策略网络,通过可学习参数动态调节多模态信息注入强度。实验表明,该方法在仅使用0.5B参数规模的Qwen2.5骨干网络时,无需机器人数据预训练即可在LIBERO、CALVIN等基准测试中达到甚至超越7B参数模型的性能表现。其推理速度达到219.2Hz,较OpenVLA提升3倍以上,且在单卡消费级GPU上8小时即可完成训练。该工作通过优化多模态信息融合路径,在显著降低模型规模和训练成本的同时,实现了动作生成性能与推理效率的突破,为轻量化具身智能模型的落地应用提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:167
论文链接:
https://hf.co/papers/2509.09372
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.09372
(3) Why Language Models Hallucinate
论文简介:
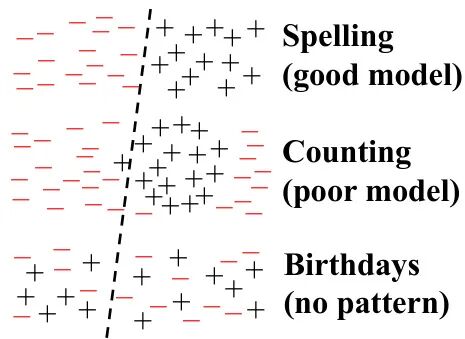
由OpenAI、Georgia Tech等机构提出的这项研究揭示了语言模型产生幻觉(hallucination)的统计根源,指出当前训练和评估体系存在根本性缺陷。论文通过建立生成错误与二分类问题的数学关联,证明即使训练数据无错误,语言模型仍会因交叉熵优化目标产生幻觉。研究发现,预训练阶段的幻觉源于统计学习中的固有矛盾:模型校准要求必然导致错误生成,而这种错误率与二分类任务中的误分类率存在2倍以上的数学关系。特别在处理无规律事实(如生日日期)时,模型幻觉率下限由训练数据中单次出现的提示比例决定,这解释了为何现有模型难以避免此类错误。
研究进一步指出,后训练阶段的评估机制加剧了幻觉问题。当前主流基准测试(如MMLU-Pro、GPQA等)普遍采用二元评分体系,对不确定回答(如"I don't know")施加惩罚,导致模型被迫进行猜测。这种评分方式使得最优策略永远是输出自信的猜测而非诚实表达不确定性,形成了"考试文化"驱动的恶性循环。论文建议在评估中引入显式置信度阈值(如要求>t置信度才作答),通过调整现有基准的评分规则来改变激励机制。这种修改无需新增评估体系,而是对现有主流测试进行渐进式改革,有望在保持模型能力的同时显著降低幻觉率。研究强调,解决幻觉问题需要技术改进与评估体系变革的协同,单纯依赖后训练优化难以突破当前瓶颈。
论文来源:hf
Hugging Face 投票数:156
论文链接:
https://hf.co/papers/2509.04664
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.04664
(4) Reverse-Engineered Reasoning for Open-Ended Generation
论文简介:
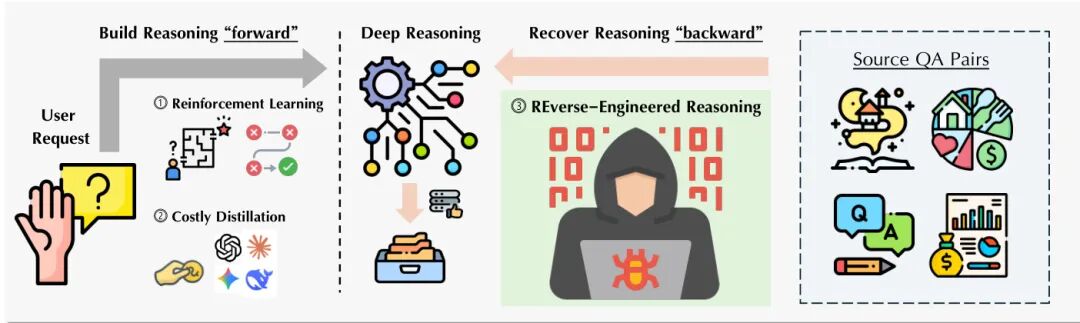
由 ByteDance Seed、香港科技大学、北京大学等机构提出了 Reverse-Engineered Reasoning (REER) 范式,该工作通过逆向工程从高质量输出中生成推理轨迹,解决了开放性生成任务中缺乏明确奖励信号的挑战。研究团队创新性地将推理过程建模为梯度无关的搜索问题,利用困惑度作为质量代理,通过迭代局部搜索算法从已知优质结果反向推导出逻辑连贯的思维链。基于此方法构建的 DeepWriting-20K 数据集包含 20,000 条深度推理轨迹,覆盖文学创作、学术写作等 25 个领域。训练出的 DeepWriter-8B 模型在 LongBench、HelloBench 等基准测试中表现突出,在创意写作任务上与 GPT-4o 和 Claude 3.5 持平,在专业写作领域更超越 Claude 3.5,同时在超长文本生成任务中以 91.28 分显著优于 GPT-4o 的 83.1 分。该研究通过逆向工程思维链的创新范式,为小规模模型培养深度推理能力提供了新路径,其开源数据集和训练方法为开放性生成任务的研究提供了重要基础。
论文来源:hf
Hugging Face 投票数:139
论文链接:
https://hf.co/papers/2509.06160
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.06160
(5) A Survey of Reinforcement Learning for Large Reasoning Models
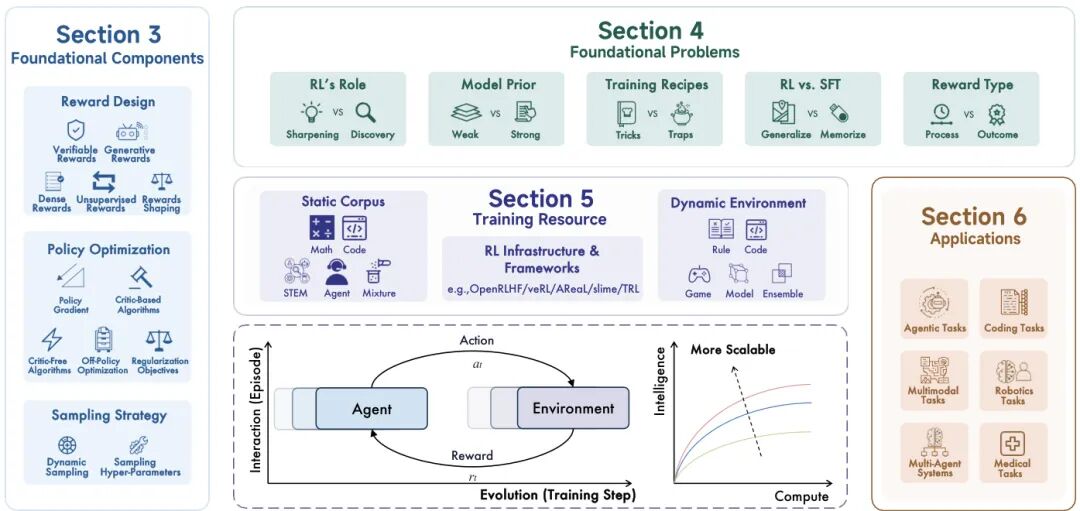
论文简介:
由清华大学、上海人工智能实验室等机构提出了《A Survey of Reinforcement Learning for Large Reasoning Models》,该工作系统性回顾了强化学习(RL)在大型语言模型(LLMs)推理能力中的应用进展,重点探讨了RL作为提升模型逻辑任务处理能力的核心方法论,从基础组件、核心问题、训练资源到下游应用的完整框架,并提出了面向人工超智能(ASI)的规模化发展路径。
研究指出,RL通过可验证奖励(如数学答案正确性、代码测试通过率)驱动模型实现长链推理、反思和自我修正,成为当前大型推理模型(LRMs)的核心训练范式。论文详细分析了RL在奖励设计(包括规则奖励、生成奖励、密集奖励和无监督奖励)、策略优化(策略梯度、批评家算法、免批评家算法及离策略优化)和采样策略(动态采样、结构化采样及超参数调节)三大基础组件的技术演进。特别强调了"验证者定律"(Verifier's Law)对任务可训练性的指导意义,即任务的客观可验证性直接影响RL的优化效率。
研究同时揭示了RL在LRMs应用中的核心争议:RL是强化已有能力还是发现新能力?与监督微调(SFT)相比,RL更擅长泛化而非记忆;模型先验知识的强弱如何影响训练效果;奖励类型应聚焦过程监督还是结果反馈。这些基础问题的探讨为后续算法改进提供了理论依据。
在训练资源层面,论文对比了静态语料库、动态环境和基础设施的适配性,指出当前资源复用性不足的局限。应用方面,RL已成功拓展至代码生成、智能体任务、多模态推理、多智能体协作、机器人控制及医疗诊断等领域,其中OpenAI o1和DeepSeek-R1等前沿模型验证了RL在复杂任务中的显著优势。未来方向聚焦于持续学习、基于记忆的RL、模型辅助RL、推理教学机制、预训练阶段集成RL等创新路径,旨在突破计算资源与算法设计的双重瓶颈,推动LRMs向通用智能演进。
论文来源:hf
Hugging Face 投票数:134
论文链接:
https://hf.co/papers/2509.08827
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.08827
(6) HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
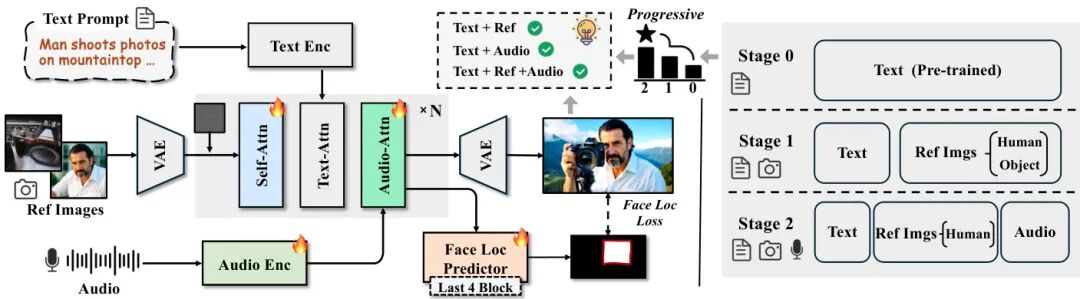
论文简介:
由清华大学和字节跳动等机构提出了HuMo,该工作提出了一种基于协作多模态条件的人类中心视频生成框架。针对现有方法在文本、图像、音频多模态输入协调上的不足,HuMo通过构建高质量三模态数据集和两阶段渐进训练范式,有效解决了训练数据稀缺和多任务协作困难两大挑战。在数据层面,通过视频-图像检索匹配和语音-唇动对齐技术,构建了包含百万级文本-图像对和5万级音频同步样本的高质量数据集;在方法层面,采用最小侵入式图像注入策略保持基础模型文本生成能力,通过渐进式任务加权策略实现主体保留与音频-视觉同步的协同学习,并提出预测式注意力机制引导模型关联音频与面部区域;在推理阶段,设计了时间自适应分类器无关引导策略,动态调整不同去噪阶段的模态权重。实验表明,HuMo在文本-图像、文本-音频、文本-图像-音频三种输入组合下均超越现有方法,在主体一致性、音频同步性和文本可控性等指标上达到最优,验证了其作为统一多模态视频生成框架的有效性。该工作为多模态内容创作提供了新的技术范式,相关数据和代码已开源。
论文来源:hf
Hugging Face 投票数:104
论文链接:
https://hf.co/papers/2509.08519
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.08519
(7) Parallel-R1: Towards Parallel Thinking via Reinforcement Learning
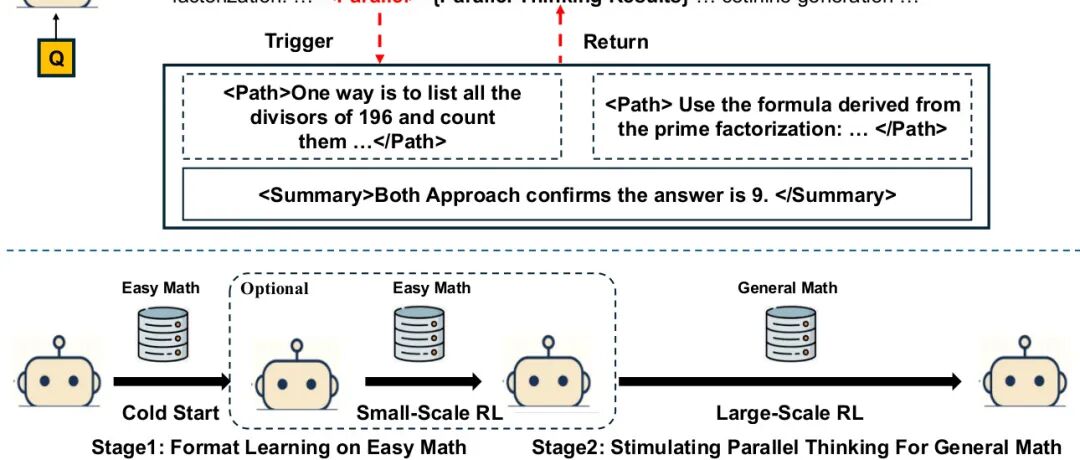
论文简介:
由腾讯AI Lab、马里兰大学等机构提出了Parallel-R1,该工作首次构建了基于强化学习的并行思考框架,通过渐进式课程设计和动态奖励机制,成功让大语言模型在真实数学推理任务中自主探索并行思考能力。研究发现,现有监督微调方法依赖合成数据导致模型仅能模仿固定模式,而Parallel-R1通过先用简单数学问题微调基础格式,再通过强化学习在复杂任务中泛化该能力,解决了冷启动难题。其创新性交替奖励策略(每10步切换准确率奖励与并行思考奖励)在保持推理效率的同时,实现了探索与验证的动态平衡。实验显示,在MATH、AMC23、AIME等基准测试中,模型准确率较基线提升8.4%,并在AIME25上通过"中期探索支架"机制取得42.9%的突破性提升。行为分析揭示了模型思考模式的演变规律:早期将并行思考作为探索工具,后期转为多视角验证手段,这种动态策略显著提升了复杂问题的求解能力。该工作不仅验证了强化学习在激活模型内在推理能力上的潜力,更为可解释AI提供了新的研究范式,相关模型、数据和代码已开源。
论文来源:hf
Hugging Face 投票数:90
论文链接:
https://hf.co/papers/2509.07980
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.07980
(8) WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents
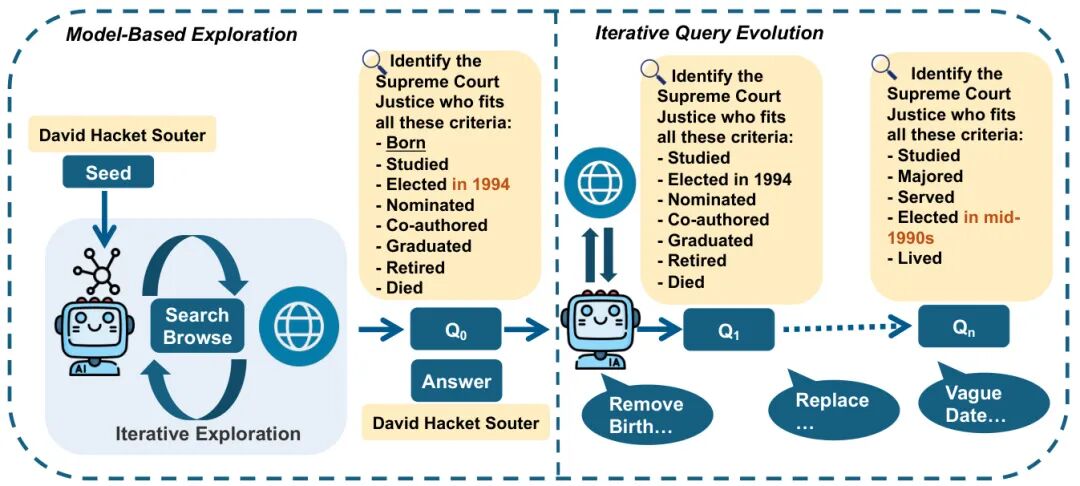
论文简介:
由香港科技大学、MiniMax和滑铁卢大学等机构提出了WebExplorer,该工作通过模型驱动的探索与迭代式长-短查询演化方法生成高质量数据,成功训练出支持128K上下文和100步工具调用的WebExplorer-8B模型。研究团队发现现有网络代理在复杂任务中表现不足的核心原因在于高质量训练数据匮乏,为此创新性地采用两阶段数据生成策略:首先通过种子实体引导模型自主探索相关信息空间,构建需要跨网站推理的初始QA对;随后通过去除显性线索、引入模糊描述等策略进行5轮迭代演化,生成平均需9.9步工具调用的高难度查询。基于此数据集,团队采用监督微调与GRPO强化学习结合的训练范式,使模型在BrowseComp-en/zh、GAIA、WebWalkerQA等基准测试中均取得同规模最优成绩,其中BrowseComp-en准确率达15.7%、FRAMES达75.7%,显著超越WebSailor-72B等更大规模模型。特别值得注意的是,该8B参数模型在HLE学术基准测试中实现17.3%的突破性表现,超过先前32B参数模型近5个百分点,验证了训练方法的泛化能力。实验表明,强化学习阶段模型平均工具调用次数从11次提升至16次以上,轨迹长度扩展至40K tokens,展现出处理复杂信息检索任务的长时程推理能力。该研究为构建具备深度网络交互能力的智能代理提供了高效的数据生成与训练范式。
论文来源:hf
Hugging Face 投票数:75
论文链接:
https://hf.co/papers/2509.06501
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.06501
(9) Visual Representation Alignment for Multimodal Large Language Models

论文简介:
由KAIST AI、NYU、Chung-Ang University等机构提出了VIsual Representation ALignment(VIRAL),该工作针对多模态大语言模型(MLLMs)在视觉任务中表现不足的问题,提出通过正则化策略对齐模型内部视觉表示与预训练视觉基础模型(VFMs)的特征,从而保留细粒度视觉信息并提升多模态理解能力。研究发现,现有MLLMs在文本监督下训练时,视觉表示会逐渐偏离视觉编码器的原始特征,导致空间推理和物体计数等任务性能下降。VIRAL通过在中间层引入基于余弦相似度的对齐损失,将MLLMs的视觉特征与更强的VFMs(如DINOv2)目标特征对齐,在不改变模型结构的前提下显著提升视觉理解能力。实验表明,该方法在CV-Bench2D、MMVP等视觉基准测试中平均提升3-5%,在通用多模态任务上也保持稳定增益。消融实验验证了对齐层选择、目标特征选择等设计的有效性,同时发现该方法能加速训练收敛并增强对视觉token排列的敏感性,证明其对空间关系建模的改进。该研究揭示了通过显式视觉对齐优化多模态信息流的重要性,为提升MLLMs的视觉感知能力提供了简洁有效的解决方案。
论文来源:hf
Hugging Face 投票数:73
论文链接:
https://hf.co/papers/2509.07979
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.07979
(10) SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
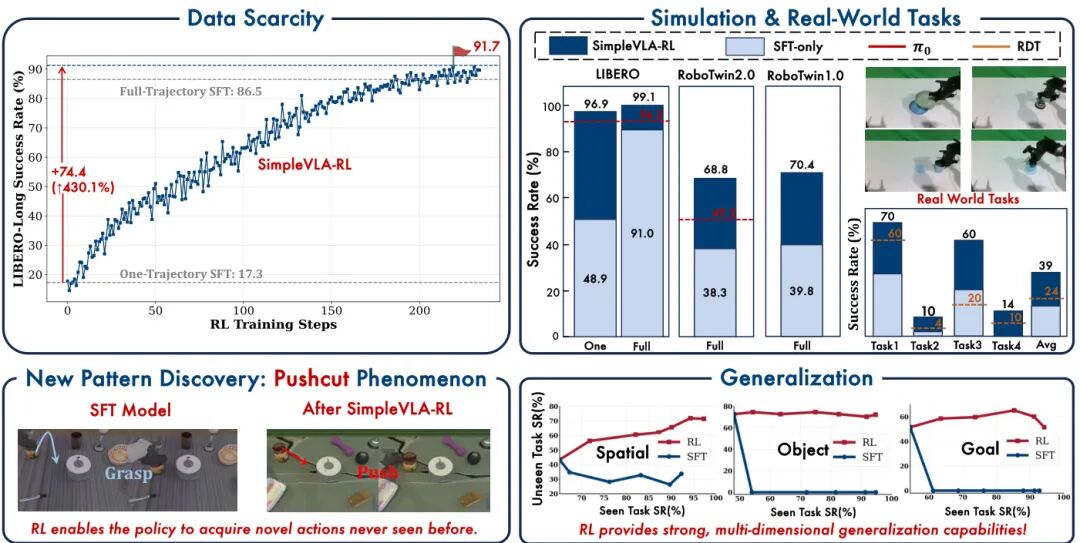
论文简介:
由清华大学、上海人工智能实验室、上海交通大学等机构提出了SimpleVLA-RL,该工作针对视觉-语言-动作(VLA)模型在机器人操作任务中的数据稀缺和泛化能力不足问题,提出了一种高效的强化学习(RL)训练框架。通过改进Group Relative Policy Optimization(GRPO)算法,引入动态采样、温度调节和剪辑范围调整等探索增强策略,该框架实现了在仅有单个演示数据的情况下,将LIBERO-Long任务成功率从17.1%提升至91.7%,并在RoboTwin 1.0/2.0基准测试中超越π₀等SOTA模型。实验表明,SimpleVLA-RL在短/中/长时域任务中均取得显著提升,尤其在双臂操作的RoboTwin 2.0上实现68.8%的平均成功率(较基线提升80%)。研究还发现RL训练中特有的"pushcut"现象——模型自主探索出超越演示数据的推动物体策略,揭示了RL在动作规划中的创新潜力。该框架通过模拟环境的高效并行渲染与端到端训练,显著降低对真实机器人数据的依赖,并在真实世界任务中实现38.5%的平均成功率,为VLA模型的规模化训练提供了新范式。
论文来源:hf
Hugging Face 投票数:67
论文链接:
https://hf.co/papers/2509.09674
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.09674
(11) RewardDance: Reward Scaling in Visual Generation
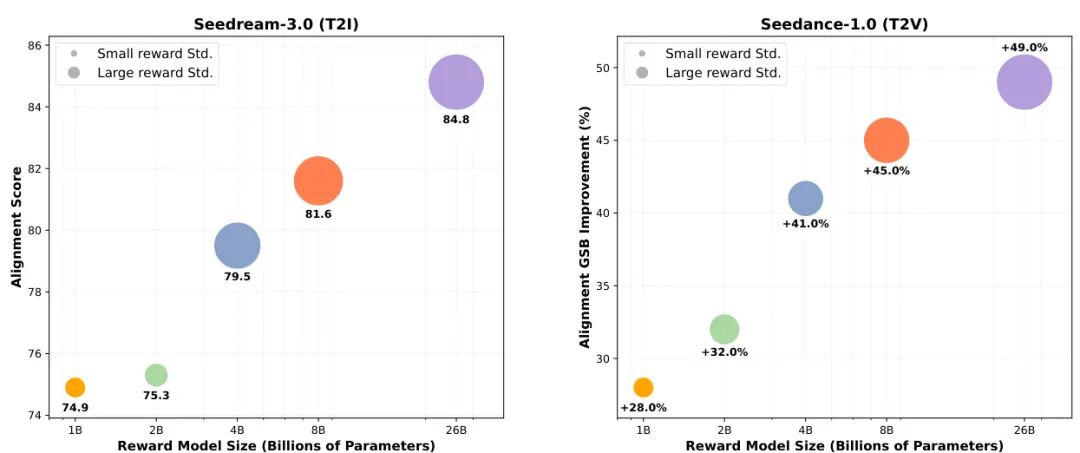
论文简介:
由 ByteDance 等机构提出了 RewardDance,该工作针对视觉生成领域奖励模型(RM)扩展性不足的问题,提出了一种基于生成式范式的可扩展奖励建模框架。现有方法存在三大核心缺陷:CLIP架构的扩展瓶颈、Bradley-Terry损失与视觉语言模型(VLM)的范式错位,以及强化学习优化中的奖励劫持问题。RewardDance 通过将奖励评分转化为VLM对"yes"token的预测概率,实现了奖励目标与VLM自回归机制的原生对齐,从而解锁了模型扩展(1B-26B参数)和上下文扩展(任务指令、参考示例、链式推理)的双重突破。实验表明,该框架在文本到图像、文本到视频、图像到视频生成任务中均显著超越现有方法,其26B参数模型使FLUX.1-dev的对齐得分从67.0提升至73.6,Seedream-3.0从74.1提升至84.8。特别值得注意的是,RewardDance通过保持高奖励方差有效缓解了奖励劫持问题,解决了小模型普遍存在的模式崩溃现象。该工作首次系统验证了奖励模型扩展性与生成质量的正相关关系,为视觉生成领域的奖励建模提供了新的设计范式和发展方向。
论文来源:hf
Hugging Face 投票数:61
论文链接:
https://hf.co/papers/2509.08826
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.08826
(12) EchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs
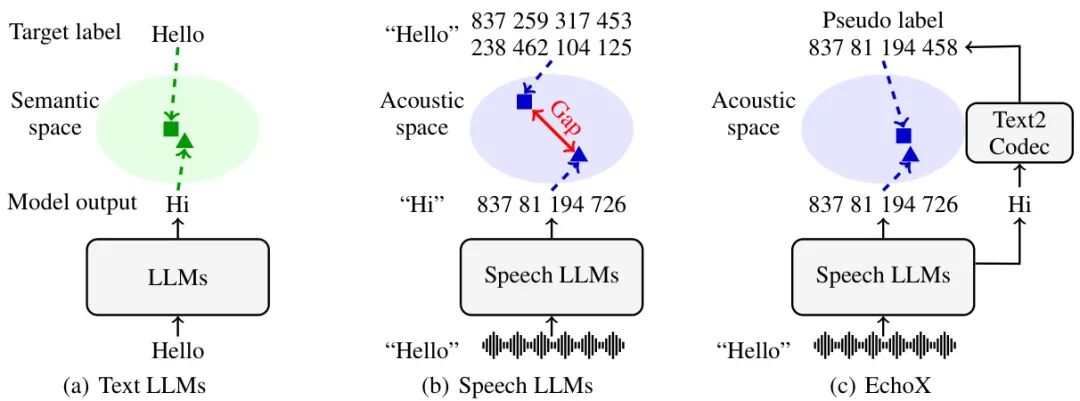
论文简介:
由香港中文大学深圳校区与腾讯天籁团队提出了EchoX,该工作针对语音到语音大语言模型(SLLMs)存在的声学-语义表征空间割裂问题,创新性地设计了回声训练框架(Echo Training)与单元语言(Unit Language)建模方法,成功实现了在约6000小时训练数据下与千万级数据模型相当的语音问答性能。研究团队发现传统SLLMs因语音token预测目标与语义表征的不匹配,导致模型在追求发音准确性时牺牲了语义连贯性。为此,EchoX采用三阶段训练策略:首先将文本大模型转化为语音到文本对话模型,接着训练文本到语音token的转换模块,最终通过冻结的文本到语音模块动态生成伪标签,引导语音到语音模型学习统一的声学语义表征。核心创新点在于设计了回声解码器(Echo Decoder)和去噪适配器(Denoising Adapter),通过对比学习对齐中间表征与语义空间,同时引入基于单元语言的语音token压缩方法,将语音序列长度压缩至文本的4.57倍,显著提升生成效率。实验表明,EchoX-3B在WebQuestions数据集上达到31.6%的准确率,较同等规模的Interleave模型提升196%,且流式生成模式将平均延迟从138 tokens降至27 tokens。该工作为语音大模型的高效训练提供了新范式,相关代码与数据集已开源。
论文来源:hf
Hugging Face 投票数:55
论文链接:
https://hf.co/papers/2509.09174
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.09174
(13) Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
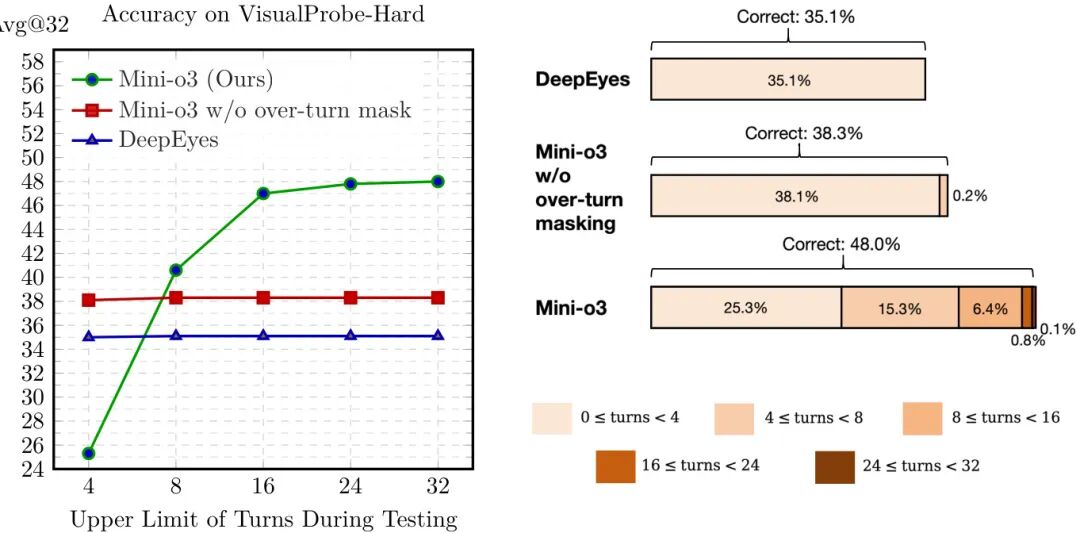
论文简介:
由 ByteDance 和香港大学等机构提出了 Mini-o3,该工作通过扩展多轮推理模式和交互轮数显著提升了视觉搜索任务的性能。针对现有开源模型在复杂视觉任务中推理模式单一、交互轮数受限的问题,Mini-o3 构建了包含 4000 个高分辨率图像的 Visual Probe 数据集,设计了涵盖深度优先搜索、试错探索等多样化推理策略的冷启动数据收集流程,并引入过轮掩码策略优化强化学习训练。该策略通过屏蔽超轮次响应的惩罚信号,在保持训练效率的同时实现测试时交互轮数的自然扩展,使模型在仅训练 6 轮的情况下,推理深度可扩展至 32 轮且准确率持续提升。实验表明,Mini-o3 在 VisualProbe-Hard 等基准测试中准确率达到 48.0%,相比 DeepEyes+ 提升 12.9 个百分点,并在多轮推理轨迹中展现出目标定位、假设修正和回溯等复杂认知行为。通过降低单次交互的像素预算至 2M,模型在保证感知精度的同时将有效交互轮数提升至 8.0 轮,成功解决高分辨率图像中目标尺寸小、干扰物密集等挑战性场景。该研究为多模态模型的多轮交互设计提供了可复现的技术范式,为复杂视觉推理任务提供了新的解决方案路径。
论文来源:hf
Hugging Face 投票数:55
论文链接:
https://hf.co/papers/2509.07969
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.07969
(14) MachineLearningLM: Continued Pretraining Language Models on Millions of Synthetic Tabular Prediction Tasks Scales In-Context ML
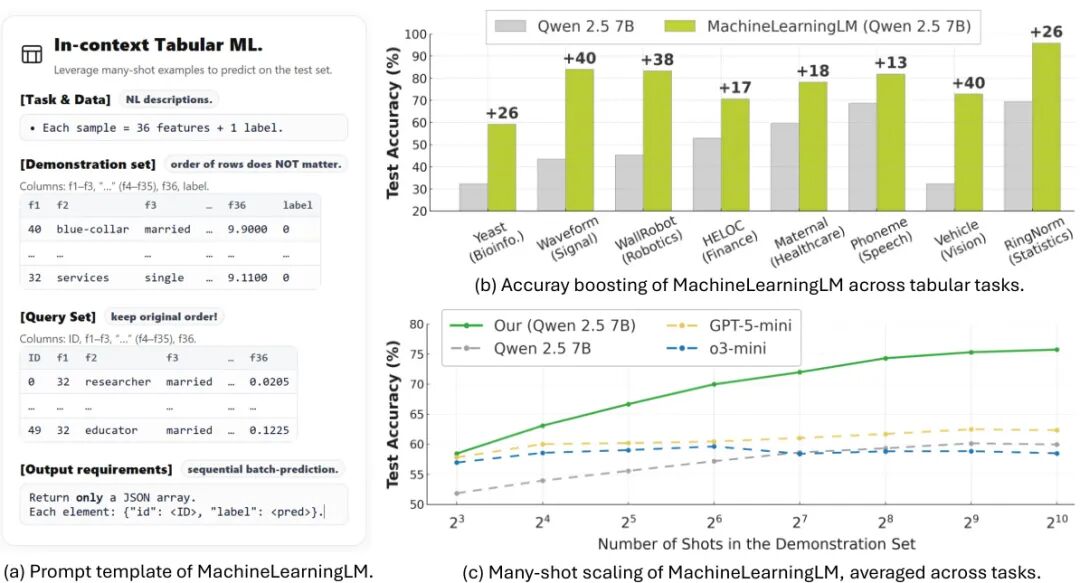
论文简介:
由 UCAS、SCUT 和 Stanford 等机构提出的 MachineLearningLM 框架通过持续预训练增强大语言模型的多示例上下文学习能力。该方法基于结构因果模型(SCM)生成数百万个合成表格分类任务,涵盖从 8 到 1024 个示例的训练规模,采用随机森林教师模型进行初始模仿学习以稳定训练过程。核心创新包括:1)表格结构化编码将示例压缩至传统提示的 1/3-1/2 长度;2)整数归一化技术将数值特征压缩为单 token 表示,提升数值处理效率;3)批量预测机制实现单次推理处理 50 个查询样本。实验显示,在 32 个领域分类任务中,该模型在 512-shot 场景下平均准确率较 Qwen-2.5-7B 提升 15.2%,在金融、医疗等领域超越 GPT-5-mini 12%,且能保持 MMLU 75.4% 的通用推理能力。特别在数值型表格任务中,其性能接近随机森林水平(平均差距<2%),同时对类别不平衡数据表现出更强鲁棒性。该研究证明通过合成数据预训练可使通用语言模型获得与专业表格模型相当的数值建模能力,同时保留语言理解和多模态扩展潜力。代码和模型已在 GitHub 和 HuggingFace 开源。
论文来源:hf
Hugging Face 投票数:53
论文链接:
https://hf.co/papers/2509.06806
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.06806
(15) Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models
论文来源:hf
Hugging Face 投票数:51
论文链接:
https://hf.co/papers/2509.06949
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.06949
(16) 3D and 4D World Modeling: A Survey
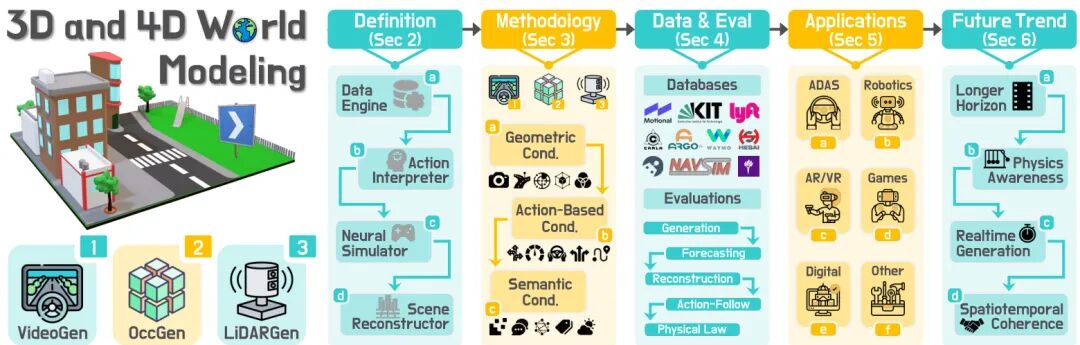
论文简介:
由多个研究机构联合提出了《3D and 4D World Modeling: A Survey》,该工作首次系统梳理了基于原生3D/4D表示的世界建模领域,建立了统一的术语体系和分类框架,填补了该领域的研究空白。论文针对视频流、占据网格和LiDAR点云三种核心模态,提出了VideoGen、OccGen和LiDARGen的分类法,分别对应视频生成、占据生成和LiDAR生成三类方法。通过梳理生成式(从观测和条件生成场景)与预测式(基于历史和动作预测未来)两大范式,论文进一步将方法细分为数据引擎、动作解释器、神经模拟器和场景重构器四类功能模块,为跨方法比较提供了统一维度。研究系统总结了nuScenes、Waymo等18个主流数据集的标注特性与模态组合,并构建了包含生成质量(FID/FVD)、预测精度(Chamfer距离)、规划相关性(轨迹合规率)等维度的评估体系。特别强调原生3D/4D表示在几何一致性、物理约束和动作交互建模上的独特优势,指出其在自动驾驶、机器人仿真等安全敏感场景中的不可替代性。论文还揭示了当前方法在长时序一致性、跨模态对齐和动态场景建模等方面的挑战,为后续研究指明方向。该工作通过建立标准化的术语体系和评估基准,为3D/4D世界模型的系统研究奠定了基础。
论文来源:hf
Hugging Face 投票数:50
论文链接:
https://hf.co/papers/2509.07996
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.07996
(17) Set Block Decoding is a Language Model Inference Accelerator
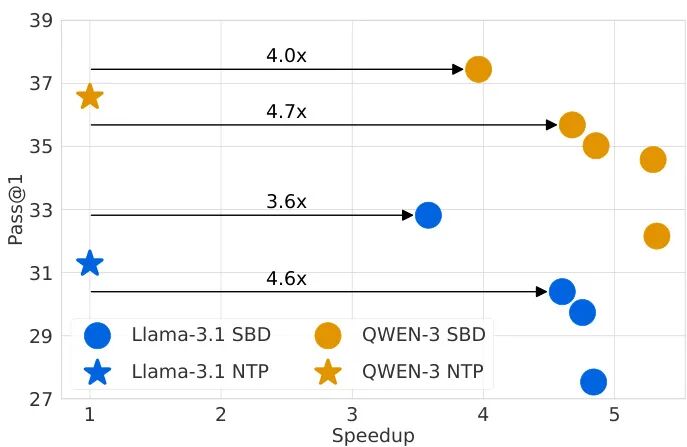
论文简介:
由 Meta 等机构提出了 Set Block Decoding(SBD),该工作提出了一种通过结合标准 next token 预测(NTP)和 masked token 预测(MATP)来加速语言模型推理的方法。SBD 允许模型在单个架构内并行采样多个非连续的未来 token,通过引入离散扩散文献中的先进求解器实现显著加速,且无需修改模型架构或牺牲准确性。实验表明,通过对 Llama-3.1 8B 和 Qwen-3 8B 微调,SBD 在保持与 NTP 相当性能的同时,将生成所需的前向传递次数减少了 3-5 倍。其核心优势在于:1)仅需微调现有 NTP 模型,无需额外超参数;2)兼容精确的 KV 缓存;3)通过 EB-Sampler 灵活控制速度-精度权衡。理论分析表明,block 推理的计算开销可忽略,3-5 倍的前向传递减少可直接转化为墙钟时间加速。实验覆盖推理、编码、数学等任务,验证了 SBD 在不同场景下的有效性,为大规模语言模型的高效部署提供了实用方案。
论文来源:hf
Hugging Face 投票数:48
论文链接:
https://hf.co/papers/2509.04185
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.04185
(18) Symbolic Graphics Programming with Large Language Models

论文简介:
由香港中文大学、西湖大学、上海人工智能实验室和马克斯·普克朗恩研究所等机构提出了Symbolic Graphics Programming with Large Language Models,该工作研究了大语言模型生成可渲染为精确视觉内容的符号图形程序(SGPs)的能力。论文首先提出了SGP-GenBench基准测试,从物体保真度、场景保真度和组合一致性三个维度评估LLMs的符号图形生成能力,发现闭源模型显著优于开源模型且性能与编码能力正相关。针对开源模型生成能力不足的问题,研究者提出基于强化学习的微调方法,通过格式有效性验证和跨模态奖励(结合SigLIP文本图像对齐和DINO图像相似性)引导模型优化。实验表明,该方法使Qwen-2.5-7B模型的SVG生成质量提升显著,在组合性任务上得分从8.8提升至60.8,达到与闭源模型相当的水平。分析显示,强化学习使模型发展出更精细的物体分解策略和场景上下文细节补充能力,例如将复杂物体拆解为多层基础图形元素,或在沙滩场景中自主添加浪花、冲浪者等合理元素。该研究证明符号图形编程可作为跨模态对齐的精确评估手段,而基于视觉基础模型的强化学习为向LLMs注入视觉知识提供了可扩展方案。
论文来源:hf
Hugging Face 投票数:44
论文链接:
https://hf.co/papers/2509.05208
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.05208
(19) Kling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis

论文简介:
由快手科技等机构提出了Kling-Avatar,该工作通过多模态指令理解和级联生成框架实现高质量长时长虚拟人动画合成。核心贡献包括:1) 提出多模态大语言模型(MLLM)Director,将音频、图像和文本指令统一为高阶语义蓝图,实现从低级信号跟踪到语义意图理解的范式转变;2) 设计两阶段级联生成框架,先生成关键帧蓝图再并行生成子片段,兼顾全局语义连贯与局部细节丰富性,支持任意时长稳定生成;3) 构建包含375组多模态指令的数据集,覆盖真人/卡通/动物等跨域场景,建立唇同步、视觉质量、指令响应等多维度评估体系;4) 实现1080p/48fps高清输出,在唇形精度、情感表现、身份一致性等指标全面超越OmniHuman-1和HeyGen等竞品,尤其在中文场景和歌唱场景优势显著。该方法通过指令驱动的语义规划和并行生成架构,解决了传统方法存在的模态冲突、长时生成失真等问题,为数字人直播、教育等实际应用提供新范式。
论文来源:hf
Hugging Face 投票数:42
论文链接:
https://hf.co/papers/2509.09595
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.09595
(20) Reconstruction Alignment Improves Unified Multimodal Models
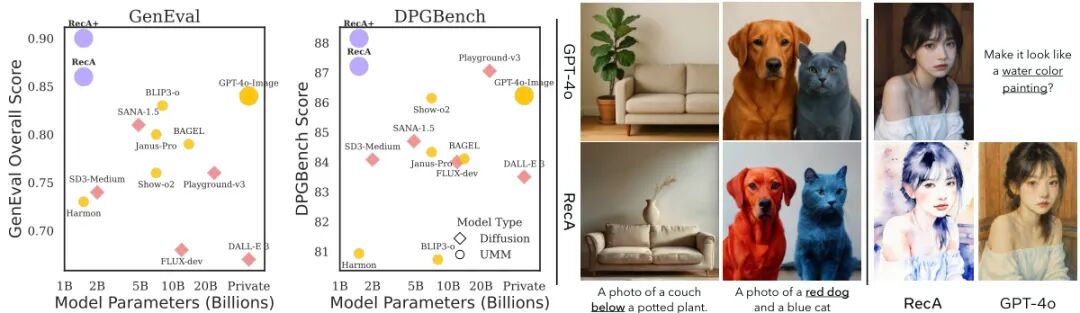
论文简介:
由UC Berkeley和University of Washington等机构提出的Reconstruction Alignment(RecA)方法,通过利用视觉理解编码器的嵌入作为"密集文本提示",为统一多模态模型(UMMs)提供了无需配对标注的自监督对齐策略。该方法通过让模型基于自身视觉编码器生成的语义特征重建输入图像,以自监督方式优化生成与理解能力的对齐,在仅需27个A100 GPU小时的后训练中,使15亿参数模型在GenEval(0.73→0.90)和DPGBench(80.93→88.15)上取得显著提升,同时在ImgEdit(3.38→3.75)和GEdit(6.94→7.25)等编辑任务中表现优异。实验表明,RecA在自回归、掩码自回归和扩散模型等不同UMM架构上均有效,其性能超越了参数量更大的开源模型(如140亿参数的BAGEL),且在保持视觉理解能力的同时显著提升生成保真度。该方法无需额外标注数据,通过简单的两阶段训练策略(先监督微调后RecA优化)即可实现SOTA效果,为多模态模型的对齐优化提供了高效通用的解决方案。
论文来源:hf
Hugging Face 投票数:38
论文链接:
https://hf.co/papers/2509.07295
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.07295










