【导读】SpikingBrain借鉴大脑信息处理机制,具有线性/近线性复杂度,在超长序列上具有显著速度优势,在GPU上1M长度下TTFT 速度相比主流大模型提升26.5x, 4M长度下保守估计速度提升超过100x;在手机CPU端64k-128k-256k长度下较Llama3.2的同规模模型Decoding速度提升4.04x-7.52x-15.39x,展示了通过借鉴大脑结构和功能构建新一代AI基础模型和架构的研究路径具有强大潜力。
当前主流大模型基于Transformer架构、在Scaling law驱动下通过增加网络规模、算力资源和数据量提升智能水平并取得了巨大成功。
然而,Transformer架构相对于序列长度具有二次方复杂度,使其训练和推理开销巨大,超长序列处理能力受限。
近日,中国科学院自动化研究所李国齐、徐波团队借鉴大脑神经元内部复杂工作机制,发布了国产自主可控类脑脉冲大模型SpikingBrain (瞬悉)-1.0,能够以极低的数据量实现高效训练,模型具有线性/近线性复杂度,显著提升长序列的训练和推理效率,训练和推理全流程在国产GPU算力平台上完成。


现有主流大模型基于Transformer架构,其基本计算单元为点神经元模型:简单乘加单元后接非线性函数,这条简单神经元加网络规模拓展的技术路径可以被称为「基于外生复杂性」的通用智能实现方法。
如前所述,这一路径面临着功耗高、可解释性差等问题。
人脑是目前唯一已知的通用智能系统,包含约1000亿神经元和约1000万亿突触数量、具有丰富的神经元种类、不同神经元又具有丰富的内部结构,但功耗仅20W左右。
鉴此,李国齐研究团队相信还有另一条路径-「基于内生复杂性」的通用智能实现方法:即找到一条融合神经元丰富动力学特性、构建具有生物合理性和计算高效性的神经网络新路径,其将充分利用生物神经网络在神经元和神经环路上的结构和功能特性。
在该思路下,探索脑科学与人工智能基础模型架构之间的桥梁、构建新一代非Transformer的类脑基础模型架构,或将引领下一代人工智能的发展方向、为实现国产自主可控类脑大模型生态提供基础积累。

SpikingBrain-1.0基于脉冲神经元构建了线性(混合)模型架构,具有线性(SpikingBrain-7B)及近线性复杂度(SpikingBrain-76B,激活参数量12B)的类脑基础模型(图1)。

图1. SpikingBrain框架概览
为解决脉冲编码时的性能退化问题,构建了自适应阈值神经元模型,模拟生物神经元脉冲发放的核心过程,随后通过虚拟时间步策略实现「电位-脉冲」的转换,将整数脉冲计数重新展开为稀疏脉冲序列。
借助动态阈值脉冲化信息编码方案,可以将模型中计算量占比90%以上的稠密连续值矩阵乘法,替换为支持事件驱动的脉冲化算子,以实现高性能与低能耗二者兼顾:脉冲神经元仅在膜电势累积达到阈值时发放脉冲事件,脉冲到达时触发下游神经元活动,无脉冲时则可处于低能耗静息状态。
进一步,网络层面的MoE架构结合神经元层面的稀疏事件驱动计算,可提供微观-宏观层面的稀疏化方案,体现按需计算的高效算力分配。
该团队在理论上建立了脉冲神经元内生动力学与线性注意力模型之间的联系,揭示了现有线性注意力机制是树突计算的特殊简化形式,从而清晰地展示了一条不断提升模型复杂度和性能的新型可行路径。
基于这一理解以及团队前期工作,团队构建了与现有大模型兼容的通用模型转换技术和高效训练范式,可以将标准的自注意力机制转换为低秩的线性注意力模型,并适配了所提出的脉冲化编码框架。
此外,为实现国产算力集群对类脑脉冲大模型的全流程训练和推理支持,团队开发了面向国产GPU集群的高效训练和推理框架、Triton/CUDA 算子库、模型并行策略以及集群通信原语。
SpikingBrain-7B 和SpikingBrain-76B分别为层间混合纯线性模型和层内混合的混合线性 MoE 模型(图2)。
其中SpikingBrain-7B由线性注意力和滑窗注意力1:1层间堆叠而成。而SpikingBrain-76B则包含 128 个 sink token、16个路由专家以及1个共享专家;对于线性层,在第 [1, 2, 3, 5, 7, 9, 11] 层布置了7个稠密FFN,其余层均实现为MoE层;
对于注意力模块在第[7, 14, 21, 28]层采用线性注意力+Softmax注意力(LA+FA)组合,在其他层均采用线性注意力+ 滑窗注意力(LA+SWA)组合。
在推理阶段,SpikingBrain利用脉冲编码将激活值转换为整数计数用于GPU执行,或转换为脉冲序列用于事件驱动的神经形态硬件。

图2. SpikingBrain网络架构

SpikingBrain1.0的长序列训练效率显著提升。SpikingBrain-1.0-7B模型能以极低的数据量(约为主流大模型的2%),实现与众多开源Transformer模型相媲美的通用语言建模性能(表1)。

SpikingBrain-1.0-76B混合线形模型通过扩展更多的参数量和更精细的注意力设计,基本保持了基座模型的性能,能使用更少的激活参数接近甚至优于Llama2-70B、Mixtral-8*7B、Gemma2-27B等先进的Transformer模型(表2)。

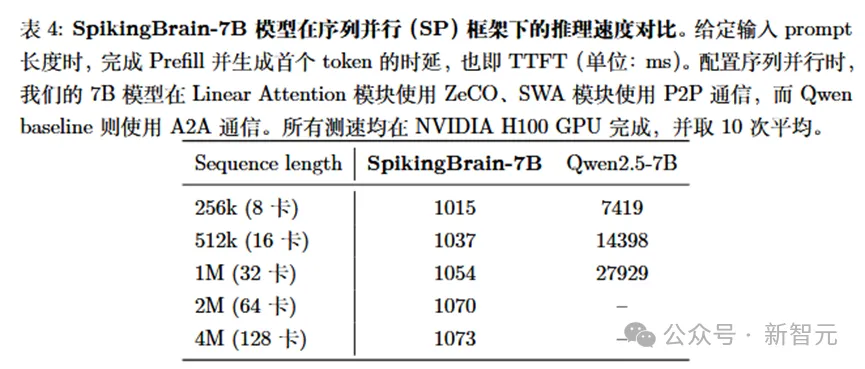
SpikingBrain-1.0-7B模型在Huggingface框架下适配了多卡序列并行推理(使用ZeCO加上P2P通信),并支持4M长度的Prefill。
结果显示,相比于使用标准注意力和A2A通信的Qwen baseline,SpikingBrain-1.0-7B在512K和1M长度下TTFT(提交提示到生成第一个Token所需的时间)加速分别达到13.88倍和26.5倍,且随序列长度和卡数扩展具有几乎恒定的时间开销,在4M长度下Qwen已经无法评测,根据拟合scaling曲线,保守估计速度提升超过100倍(表4)。
团队将压缩到1B的SpikingBrain-1.0部署到CPU手机端推理框架上,在64k-128k-256k长度下较Llama3.2的1B模型Decoding速度分别提升4.04x-7.52x-15.39x。
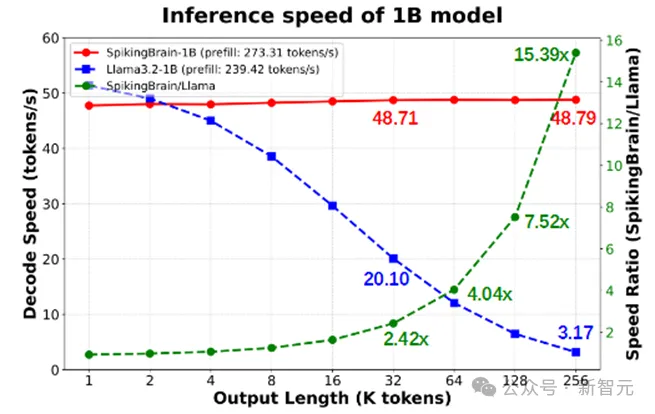
图2 基于CPU移动推理框架下,不同输出长度的解码速度比较
对话Demo和网络试用端口:团队提供了SpikingBrain-1.0-76B模型的网络端的试用端口供大家体验,该模型基于vLLM推理框架部署在国产GPU集群上,可以支持数百人的并发请求。
为支持类脑研究生态的构建,团队开源了SpikingBrain-1.0-7B模型(详见技术报告)。

本次发布的国产自主可控类脑脉冲大模型探索了脉冲神经元内生复杂神经动力学与线性注意力模型之间的机制联系,设计了线性模型架构和基于转换的异构模型架构,通过动态阈值脉冲化解决了脉冲驱动限制下的大规模类脑模型性能退化问题,实现了国产GPU算力集群对类脑脉冲大模型训练和推理的全流程支持。
超长序列的建模在复杂多智能体模拟、DNA序列分析、分子动力学轨迹等超长序列科学任务建模场景中将具有显著的潜在效率优势。
未来该团队将进一步探索神经元内生复杂动态与人工智能基础算子之间的机制联系,构建神经科学和人工智能之间的桥梁,期望通过整合生物学见解来突破现有人工智能瓶颈,进而实现低功耗、高性能、支持超长上下文窗口的类脑通用智能计算模型,为未来的类脑芯片设计提供重要启发。
☟☟☟
☞人工智能产业链联盟筹备组征集公告☜
☝
精选报告推荐:
11份清华大学的DeepSeek教程,全都给你打包好了,直接领取:
【清华第四版】DeepSeek+DeepResearch让科研像聊天一样简单?
【清华第七版】文科生零基础AI编程:快速提升想象力和实操能力
【清华第十一版】2025AI赋能教育:高考志愿填报工具使用指南
10份北京大学的DeepSeek教程
【北京大学第五版】Deepseek应用场景中需要关注的十个安全问题和防范措施
【北京大学第九版】AI+Agent与Agentic+AI的原理和应用洞察与未来展望
【北京大学第十版】DeepSeek在教育和学术领域的应用场景与案例(上中下合集)
8份浙江大学的DeepSeek专题系列教程
浙江大学DeepSeek专题系列一--吴飞:DeepSeek-回望AI三大主义与加强通识教育
浙江大学DeepSeek专题系列二--陈文智:Chatting or Acting-DeepSeek的突破边界与浙大先生的未来图景
浙江大学DeepSeek专题系列三--孙凌云:DeepSeek:智能时代的全面到来和人机协作的新常态
浙江大学DeepSeek专题系列四--王则可:DeepSeek模型优势:算力、成本角度解读
浙江大学DeepSeek专题系列五--陈静远:语言解码双生花:人类经验与AI算法的镜像之旅
浙江大学DeepSeek专题系列六--吴超:走向数字社会:从Deepseek到群体智慧
浙江大学DeepSeek专题系列七--朱朝阳:DeepSeek之火,可以燎原
浙江大学DeepSeek专题系列八--陈建海:DeepSeek的本地化部署与AI通识教育之未来
4份51CTO的《DeepSeek入门宝典》
51CTO:《DeepSeek入门宝典》:第1册-技术解析篇
51CTO:《DeepSeek入门宝典》:第2册-开发实战篇
51CTO:《DeepSeek入门宝典》:第3册-行业应用篇
51CTO:《DeepSeek入门宝典》:第4册-个人使用篇
5份厦门大学的DeepSeek教程
【厦门大学第一版】DeepSeek大模型概念、技术与应用实践
【厦门大学第五版】DeepSeek等大模型工具使用手册-实战篇
10份浙江大学的DeepSeek公开课第二季专题系列教程
【精选报告】浙江大学公开课第二季:《DeepSeek技术溯源及前沿探索》(附PDF下载)
【精选报告】浙江大学公开课第二季:2025从大模型、智能体到复杂AI应用系统的构建——以产业大脑为例(附PDF下载)
【精选报告】浙江大学公开课第二季:智能金融——AI驱动的金融变革(附PDF下载)
【精选报告】浙江大学公开课第二季:人工智能重塑科学与工程研究(附PDF下载)
【精选报告】浙江大学公开课第二季:生成式人工智能赋能智慧司法及相关思考(附PDF下载)
【精选报告】浙江大学公开课第二季:AI大模型如何破局传统医疗(附PDF下载)
【精选报告】浙江大学公开课第二季:2025年大模型:从单词接龙到行业落地报告(附PDF下载)
【精选报告】浙江大学公开课第二季:2025大小模型端云协同赋能人机交互报告(附PDF下载)
【精选报告】浙江大学公开课第二季:DeepSeek时代:让AI更懂中国文化的美与善(附PDF下载)
【精选报告】浙江大学公开课第二季:智能音乐生成:理解·反馈·融合(附PDF下载)
6份浙江大学的DeepSeek公开课第三季专题系列教程
【精选报告】浙江大学公开课第三季:走进海洋人工智能的未来(附PDF下载)
【精选报告】浙江大学公开课第三季:当艺术遇见AI:科艺融合的新探索(附PDF下载)
【精选报告】浙江大学公开课第三季:AI+BME,迈向智慧医疗健康——浙大的探索与实践(附PDF下载)
【精选报告】浙江大学公开课第三季:心理学与人工智能(附PDF下载)
【AI加油站】第八部:《模式识别(第四版)-模式识别与机器学习》(附下载)
人工智能产业链联盟高端社区

一次性说清楚DeepSeek,史上最全(建议收藏)
DeepSeek一分钟做一份PPT
用DeepSeek写爆款文章?自媒体人必看指南
【5分钟解锁DeepSeek王炸攻略】顶级AI玩法,解锁办公+创作新境界!
【中国风动漫】《雾山五行》大火,却很少人知道它的前身《岁城璃心》一个拿着十米大刀的男主夭折!

免责声明:部分文章和信息来源于互联网,不代表本订阅号赞同其观点和对其真实性负责。如转载内容涉及版权等问题,请立即与小编联系(微信号:913572853),我们将迅速采取适当的措施。本订阅号原创内容,转载需授权,并注明作者和出处。如需投稿请与小助理联系(微信号:AI480908961)
编辑:Zero