近日,由字节跳动、香港大学团队联合开发的Mini-o3模型正式上线。这个号称Open AI o3 视觉推理平替的视觉语言模型(VLM),在训练限制轮数仅6轮的情况下,能在测试阶段将思考轮数扩展到数十轮。
Mini-o3的核心创新为Visual Probe挑战性问题数据集构建、迭代数据收集管道以及超轮次掩码策略,支持深度优先搜索等多样化推理模式。测试时,交互轮次可扩展至 32 轮以上,准确率也会随着轮次增加显著提升。

目前,Mini-o3在 VisualProbe、VBench、HR-Bench、MME-Realworld 等基准上取得了 7B 量级的最佳成绩。训练代码、模型权重以及包含 4,500 条数据的 Visual Probe 数据集也已开源。
训练数据收集
Mini-o3通过提出一种有效的多模态智能体训练方案来推进交互深度和推理模式。该智能体支持多轮图像工具使用,从而提高了视觉基础任务的适应性和推理多样性。
训练过程包括两个阶段:
监督微调(SFT):在数千个涉及图像工具使用的多轮轨迹(即冷启动数据)上对模型进行微调,使模型生成具有多样化和鲁棒推理模式的有效轨迹。 具有可验证奖励的强化学习(RLVR):使用可验证的、语义感知的奖励,采用外部 LLM 作为评判者来计算奖励信号。总共设置 6 个交互轮次和 32K 上下文长度的上限。

团队构建了一个具有挑战性的视觉搜索数据集——Visual Probe 数据集。它包含用于训练的 4,000个视觉问答集和用于测试的 500个问答集。 VisualProbe 的特点是:
小目标; 大量干扰物; 高分辨率图像

为了生成高质量、多样化的多轮轨迹,Mini-o3只保留最终答案正确的轨迹。遵循此过程,团队从 6 个示例中收集了大约 6,000 条冷启动轨迹。
超轮次掩码策略
为了增加每个环节中可行的轮次数,团队将每张图像的最大像素数减少至 200 万。这种简单的调整允许在相同的上下文预算内容纳更多轮次,提高了长视野问题的解决率。
为了防止模型陷入“提前回答”策略,团队还提出了一种超轮次掩码技术,其目标是避免对“未完成”的回答进行惩罚。

这项技术削减了之前“屏蔽”未完成回答的损失,鼓励模型继续探索。
值得注意的是,尽管在训练期间采用了相对较小的翻转轮次上限,但测试时间轨迹可以延伸至数十轮,准确率也会随着轮次增加而提升。因此,轮次掩码对于实现测试时间在交互翻转次数方面的扩展优势至关重要。
实践结果
本研究核心发现,尽管Mini-o3(蓝线)训练时仅设定6轮上限,但在测试中,随着交互轮次上限从4增至32轮,其在VisualProbe-Hard数据集上的准确率从38%持续升至48%。这表明模型真正学会了“思考”,且思考越充分,效果越好。相比之下,未采用Over-turn Masking策略的模型(红线)在6轮后性能便停止增长。

在多项视觉搜索基准测试中,Mini-o3均刷新了最新的SOTA成绩,显著超越现有开源模型。尤其是在最具挑战性的 VisualProbe-Hard 任务上,Mini-o3的准确率高达 48.0%,相比此前表现最佳的 DeepEyes(35.1%) 提升明显。

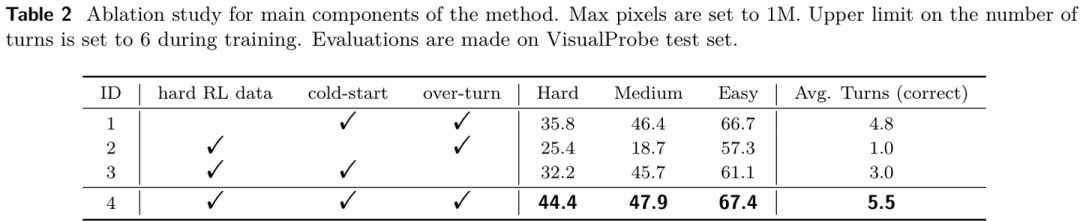
消融实验结果进一步印证了Mini-o3的创新设计:无论移除 Visual Probe 数据集、冷启动 SFT,还是 Over-turn Masking,模型性能都会大幅下降。
结语
Mini-o3研究团队作者一共6人,其中赖昕和Junyi Li是项目的共同一作。
公开资料显示,赖昕是字节跳动的研究员,主攻大型多模态模型。他本科就读于哈尔滨工业大学,后获得香港中文大学博士学位。博士期间,他作为第一作者参与的Step-DPO项目在MATH和GSM8K分别获得了70.8%和94.0%的准确率。
Junyi Li曾就读于华中科技大学,目前是香港大学的博士,参与字节研究工作。2024年,他作为第一作者的PartGLEE项目被ECCV接收。
在Mini-o3的工作中,团队研究了视觉语言模型(VLMs)的多轮基于图像的工具使用。他们开发了一个三管齐下的方法:
首先构建VisualProbe——一个包含训练和评估任务的挑战性视觉搜索数据集; 其次通过利用现有VLM的上下文学习能力来收集冷启动数据; 最后通过超轮次掩码策略增强了原始GRPO,促进了测试时的轮次扩展
研究团队表示,Mini-o3的技术方案能为多轮交互式多模态模型的开发与强化学习应用提供实际指导。
往期推荐

商务合作

张先生:18594278240(同微)
Email:zhangsihan@ofweek.com










