

该论文发表于The Thirty-Eighth AAAI Conference on Artificial Intelligence(AAAI-24,人工智能领域顶级会议,CCF-A),题目为《Language-Guided Transformer for Federated Multi-Label Classification》。
代码链接:
https://github.com/Jack24658735/FedLGT
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/29295


论文概要
联邦学习(Federated Learning, FL)作为一种隐私保护的分布式学习范式,允许多个客户端在不共享私有数据的情况下协同训练模型,已在医疗、金融等领域展现出巨大潜力。然而,现有联邦学习方法多聚焦于单标签图像分类,在更贴近实际场景的多标签分类任务中面临严峻挑战:客户端数据分布的异质性(如标签分布偏移、领域差异)会导致局部模型对标签相关性的学习存在偏差,直接聚合局部模型会引发全局性能退化。
针对这一问题,本文提出了一种全新的联邦多标签分类框架 —— 联邦语言引导 Transformer(FedLGT)。该框架基于 Transformer 架构,通过两大核心技术突破现有瓶颈:一是客户端感知掩码标签嵌入(Client-Aware Masked Label Embedding, CA-MLE),引导局部模型聚焦全局模型尚未掌握的标签知识;二是通用标签嵌入(Universal Label Embedding, ULE),利用预训练视觉 - 语言模型(如 CLIP)的文本编码器生成统一标签嵌入,实现跨客户端标签语义对齐。
实验结果表明,FedLGT在FLAIR、MS-COCO、PASCAL VOC等多标签数据集上全面超越现有联邦学习方法(如 FedAvg、FedC-Tran),在复杂数据异质性场景下仍能保持优异的泛化性能,为联邦多标签分类任务提供了全新解决方案。

研究背景
多标签图像分类需识别图像中所有目标类别(如“液体”“玻璃”“植物” 可共存于一张图像),其核心挑战在于建模标签间的相关性(如“液体” 与 “玻璃” 常共现)。在联邦学习场景中,这一挑战被数据异质性进一步放大。
● 标签分布偏移:不同客户端的标签空间可能重叠有限(如客户端1侧重 “液体 + 玻璃”,客户端2侧重 “液体 + 植物”),导致局部模型学习的标签相关性存在偏差。
● 领域差异:即使标签相同,不同客户端的图像特征可能因采集环境(如光照、设备)不同而存在显著差异。
● 聚合冲突:直接聚合局部模型会混淆不同客户端学到的标签关联模式(如 “液体” 与 “玻璃”“植物” 的关联被强行融合),导致全局模型性能下降。
现有联邦学习方法(如FedProx、FedBN)主要针对单标签任务设计,无法处理多标签特有的标签相关性问题;而集中式多标签模型(如C-Tran)依赖全局数据学习标签关联,难以直接迁移到联邦场景。因此,如何在保护隐私的前提下,跨客户端协同学习鲁棒的标签相关性,成为联邦多标签分类的关键难题。

方法
FedLGT 的整体框架如图 1 所示,通过融合Transformer 的全局建模能力与语言引导的标签语义对齐机制,实现跨客户端知识聚合。其核心包括三大模块:多标签 Transformer基础架构、客户端感知掩码标签嵌入(CA-MLE)、通用标签嵌入(ULE)。

图1 联邦语言引导 Transformer(FedLGT)框架示意图
(1) 多标签 Transformer 基础架构
FedLGT以Transformer为核心构建模型骨架,将图像特征与标签嵌入作为输入序列,通过自注意力机制捕捉视觉特征与标签间的关联。
● 图像特征由ResNet-18骨干网络提取,转化为序列形式。
● 标签嵌入与状态嵌入(表示标签的 “已知”“未知”“负例” 状态)融合为掩码标签嵌入,作为Transformer的另一输入序列。
● 输出通过MLP头预测各标签的存在概率,实现多标签分类合冲突。
(2)客户端感知掩码标签嵌入(CA-MLE)
客户端感知掩码标签嵌入(CA-MLE)是解决局部与全局目标不一致的关键设计。其核心思路是让局部模型在训练时重点关注全局模型尚未掌握的标签知识:客户端接收当前全局模型后,先用其对本地数据进行预测,得到各标签的置信度;若某标签的置信度处于阈值区间(如0.48~0.52,即全局模型对该标签“不确定”),则将其标记为“未知”状态,强制局部模型重点学习;且仅“未知”状态的标签参与损失计算,确保局部训练聚焦全局模型的薄弱环节,实现知识互补。这一过程可表示为:当全局模型对标签 c 的预测概率 ρc处于 τ-ε 到 τ+ε 之间(其中 τ=0.5 为判断阈值,ε=0.02 为不确定性边际),则将该标签的状态设为 “未知”,否则保持原状态。
计算公式如下:
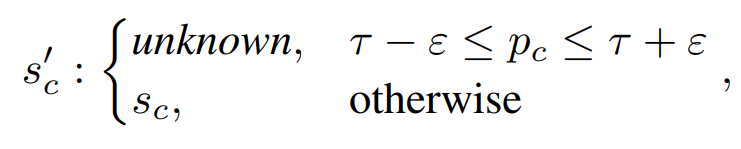
其中,τ=0.5为判断阈值,ε=0.02为不确定性边际,ρc为全局模型对标签c的预测概率。
(3) 通用标签嵌入(ULE)
通用标签嵌入(ULE)则用于统一跨客户端的标签语义空间。其借助 CLIP 的预训练文本编码器生成固定的标签嵌入:为每个标签设计提示文本 “The photo contains [CLASS]”(如 “ The photo contains liquid”),通过 CLIP 的文本编码器生成对应嵌入,确保不同客户端对同一标签的语义理解一致;这些嵌入参数固定不参与训练,作为全局共享的 “语义锚点”,大幅减少模型聚合时的标签语义冲突。对于 FLAIR 粗粒度任务(类别较抽象),还结合细粒度标签信息优化嵌入 —— 或直接用细粒度标签填充提示文本,或对粗粒度类别对应的细粒度嵌入取平均,进一步提升语义一致性。
(4) 损失函数与训练流程
FedLGT 的总损失包括两部分:
● 带属性加权的二元交叉熵损失,仅对 CA-MLE 标记的 “未知” 标签计算,强化小样本标签学习。

● 全局模型采用 FedAvg 聚合策略,按客户端数据量加权融合局部模型参数。

训练流程遵循联邦学习范式:服务器广播全局模型→客户端通过 CA-MLE 和 ULE 进行局部训练→上传局部模型→服务器聚合更新全局模型,迭代至收敛。

实验和结果
实验所用数据集包括FLAIR、MS-COCO和PASCAL VOC。其中FLAIR是首个联邦多标签专用数据集,包含真实用户在Flickr上的图像,尺寸为256×256像素,天然具有非IID特性(数量倾斜、标签分布偏移、领域差异),分为粗粒度(17个类别)和细粒度(1628个类别)任务,后者因类别更多、分布更稀疏,对模型泛化能力要求更高;MS-COCO 含122,218张图像、80个常见目标类别,实验中通过人工划分模拟联邦场景;PASCAL VOC则含21,503张图像、20个类别,作为轻量级场景的验证集。
实验的实现细节与参数设置严格统一:所有模型均采用 ResNet-18 作为视觉特征提取器,确保对比公平;ULE 基于 CLIP 文本编码器生成,状态嵌入中 “positive”“negative” 通过 CLIP 生成,“unknown” 固定为全零向量;CA-MLE 的阈值 τ=0.5,不确定性边际 ε=0.02;局部训练每轮5个 epoch,采用 Adam 优化器(学习率0.0001),批处理大小16;联邦通信轮次设为50,每轮激活客户端数量等效于50个(通过采样率控制);针对FLAIR的数量倾斜问题,采用非均匀客户端采样策略(按数据量占比分配采样概率),避免小数据集客户端被忽视。实验基于 PyTorch 框架实现,训练硬件为单台 NVIDIA RTX 3090Ti GPU(24GB 显存),确保计算资源一致。
评估指标采用多标签分类领域的标准指标,包括 per-class(C)和 overall(O)的平均精度(AP)、精确率(P)、召回率(R)、F1 分数,其中 per-class 指标反映模型对稀有类别的识别能力,overall 指标则体现整体性能。
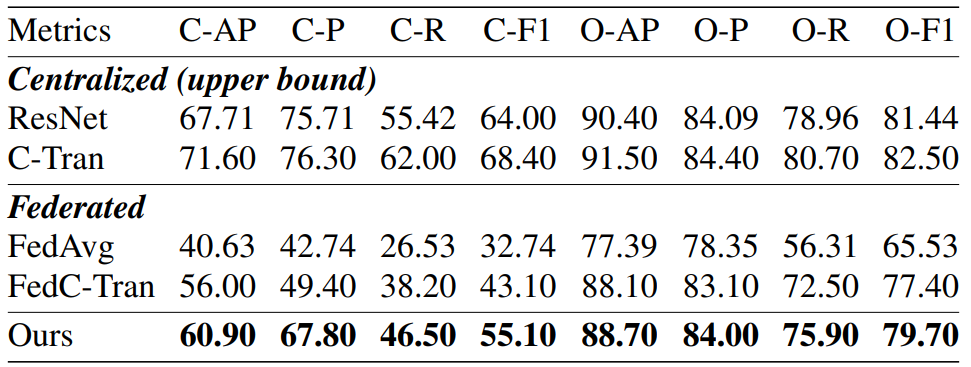
如下表1所示,在 FLAIR 粗粒度任务中,FedLGT 的性能全面领先现有方法:其 C-AP 达到 60.90,较 FedC-Tran(56.00)提升4.9个百分点,C-F1 为55.10,较 FedC-Tran(43.10)提升12个百分点;与 FedAvg 相比,优势更为显著,C-AP 提升近20个百分点。即使与集中式模型相比,FedLGT 的性能衰减幅度也最小,例如 C-AP 仅比集中式 C-Tran 低10.7%,而 FedC-Tran 则低15.6%,充分证明其对标签关联的建模能力更优。
表1 FLAIR 粗粒度任务
如下表2所示,在更具挑战性的FLAIR细粒度任务中,FedLGT的优势进一步放大:其C-AP达10.60,是 FedC-Tran(3.30)的3.2倍,O-F1为33.40,较FedC-Tran(31.70)提升1.7个百分点。这一结果验证了 FedLGT 在大规模标签空间中处理稀疏分布标签的能力,尤其在类别数量庞大、数据异质性更强的场景中,其优势更为突出。
表2 FLAIR 细粒度任务

如下表3所示,在 MS-COCO 与 PASCAL VOC 数据集上,FedLGT 同样表现优异。MS-COCO 上,其 O-F1 达76.80,较 FedC-Tran(75.30)提升1.5个百分点;PASCAL VOC 上,C-F1 为85.50,超越 FedC-Tran(83.60)1.9个百分点,证明其泛化能力不受数据集特性限制,在传统多标签场景中依然有效。
表3 FedLGT 与联邦学习基线在 MS-COCO 和 PASCAL VOC 上的比较

如下表4所示,消融实验进一步验证了各核心组件的有效性:仅添加 ULE 时,FedC-Tran 的 C-AP 从56.00提升至59.70(+3.7个百分点),证明统一标签语义空间的重要性;仅添加 CA-MLE 时,C-AP 仅提升0.1个百分点,但与 ULE 结合后,C-AP 可进一步提升至60.90(+1.2个百分点),体现了组件间的协同价值。
表4 消融实验

结论
论文提出的 FedLGT 框架首次系统解决了联邦多标签分类中的数据异质性与标签关联建模难题,通过 CA-MLE 引导局部模型聚焦全局知识缺口,借助 ULE 实现跨客户端标签语义对齐,在多个数据集上的实验充分验证了其优越性。该方法不仅为联邦学习在多标签场景的应用提供了关键技术支撑,更开创了利用预训练视觉 - 语言模型解决联邦学习中语义对齐问题的新思路。
撰稿人:刘世港
审稿人:周成菊


脑机接口与混合智能研究团队



团队主页
www.scholat.com/team/hbci











