近年来,视频生成模型(VGMs)凭借其互联网规模的预训练所带来的强大动态建模能力,已被广泛用作VLA模型的特征提取主干网络。然而,现有世界模型往往未能充分利用其强大的分布建模能力来预测未来状态。这一局限源于双重挑战:一方面,将视频生成过程与特征学习相结合存在技术难点且理论基础尚不完善;另一方面,生成式世界模型在机器人领域的应用面临现实瓶颈,基于视频扩散模型逐帧生成未来画面的方式计算效率低下,无法满足实时控制的要求。
为应对这些挑战,腾讯Robotics X联合香港科技大学、北京大学提出一个用于实时机器人控制的双系统世界模型Manipulate in Dream (MinD)。该模型创新性地结合了视频生成与动作预测,解决了现有方法在生成建模与效率上的双重挑战。MinD通过低频视频生成和高频动作扩散两个异步过程,实现快速预测与风险感知规划。此外,MinD还实现了高效推理流程,无需完整的多步去噪,只需单步去噪,模型能够以极低的计算开销实现实时机器人控制。
为了将早期预测与动作联系起来,该团队提出了一个视频-动作扩散匹配模块(DiffMatcher),并采用一种新颖的协同训练策略,该策略为每个扩散模型使用独立的调度器。实验表明,MinD在RL-Bench上达到63%成功率,在真机Franka上每秒传输帧数达到11.3,还能提前预测74%的任务失败率,为安全监控提供实时信号。

论文标题:《MinD: Learning A Dual-System World Model for Real-Time Planning and Action Consistency Video Generation》
论文链接:https://www.arxiv.org/abs/2506.18897
项目主页:
https://manipulate-in-dream.github.io/
代码链接:
https://github.com/manipulate-in-dream
1
方法
1.1 整体框架
双系统世界模型MinD基于扩散模型构建,将低频的视觉想象与高频动作生成分离,使策略能够基于中间态、计算高效的未来表征进行条件生成,而非基于完整渲染的视频。模型整体框架如图3所示,包含三个核心组件:分层扩散框架、异步协同训练策略和基于单步预测的推理。
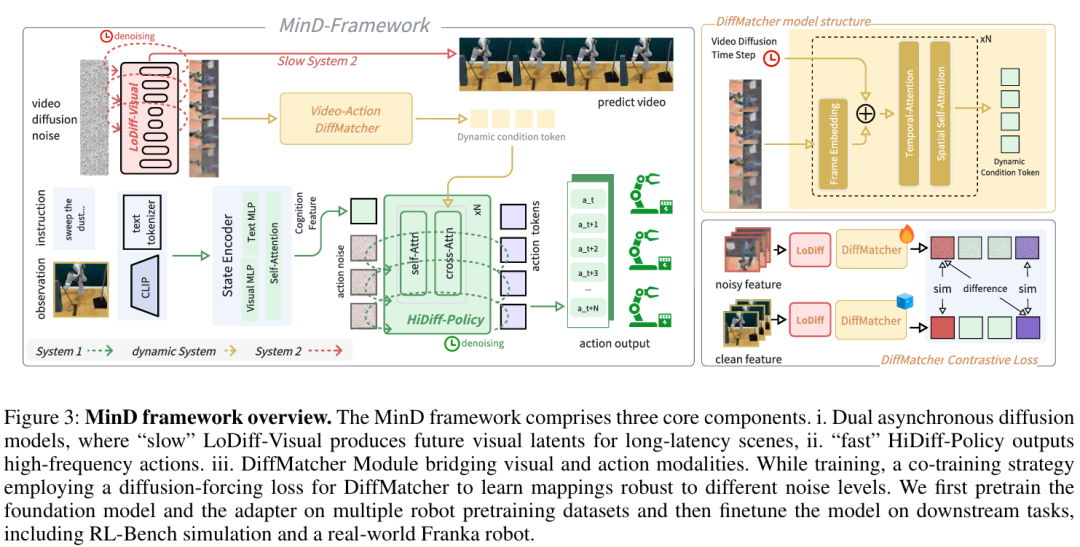
1.2 分层扩散框架
MinD通过两个异步扩散模型运作:
低频视频生成器(LoDiff-Visual):是一个基于潜扩散模型的视频生成器,是MinD的“慢思考”系统,负责“想象”未来。给定初始观测 和语言指令 l ,能预测未来视觉潜在序列
和语言指令 l ,能预测未来视觉潜在序列 。
。
高频动作策略(HiDiff-Policy):作为“快反应”系统,是一个高频运行且参数较少的扩散Transformer(DiT)策略。该策略能够生成高频动作序列 它以LoDiff-Visual的单步预测视觉特征为条件,采用很短的时间调度(如T′′=100步)以实现快速动作生成。
它以LoDiff-Visual的单步预测视觉特征为条件,采用很短的时间调度(如T′′=100步)以实现快速动作生成。
DiffMatcher模块:为了连接两个异步系统,提出了轻量级模块DiffMatcher,负责对齐视觉与动作模态。该模块将LoDiff-Visual在去噪步骤 t 产生的带噪视觉潜在 映射为紧凑特征向量
映射为紧凑特征向量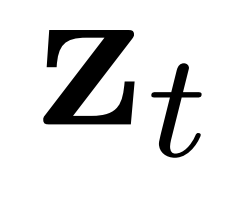 。此特征
。此特征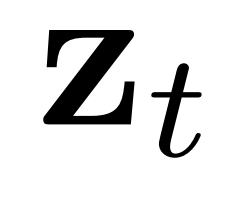 作为HiDiff-Policy的条件,有效将动作计划与未来预测关联起来。
作为HiDiff-Policy的条件,有效将动作计划与未来预测关联起来。
1.3 异步协同训练策略
关键挑战在于确保HiDiff-Policy能正确解读LoDiff-Visual产生的含噪中间单步表征。但独立训练模型无法建立这种关联。因此,提出异步协同训练策略以联合优化整个框架。总训练目标是三项损失的加权和:
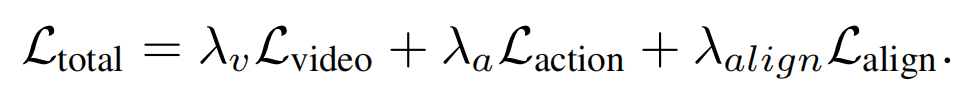
核心在于对齐损失 ,称之为扩散强制(diffusion-forcing)。训练过程中,通过取用不带噪声的真实视频潜在
,称之为扩散强制(diffusion-forcing)。训练过程中,通过取用不带噪声的真实视频潜在 ,并添加对应随机时间步 t 的噪声生成带噪版本
,并添加对应随机时间步 t 的噪声生成带噪版本 ,来模拟推理条件。随后训练DiffMatcher生成噪声无关的表征。
,来模拟推理条件。随后训练DiffMatcher生成噪声无关的表征。
1.4 单步预测的推理
MinD设计实现了高效推理流程。无需对未来视频进行完整的多步去噪,而只需在LoDiff-Visual模型上执行单步去噪。此过程使MinD够以极低的计算开销实现实时机器人控制,同时充分发挥视频模型的预测能力。
2
实验
2.1 模型实现细节
MinD基于DynamiCrafter框架构建,保留其视觉编码器和时空UNet主干作为预训练视觉模块。针对机器人任务训练,参考OpenVLA的方法,使用CLIP特征和分词器实现高效状态表征。采用RT-1、Robomind和部分OXE数据进行特征对齐预训练。
实现了两个HiDiff-Policy变体(Small和Base),其参数量与CogACT相当,并增加了交叉注意力层。数据预处理遵循Dynamicrafter标准,包括128×128图像缩放和RLDS动作格式。
2.2 仿真环境操作任务
研究人员在RL-Bench使用CoppeliaSim进行评估,配置Franka Panda机器人和多视角相机系统,仅使用前视图像作为输入。选择了7个不同的任务,通过预定义路径点和关键帧降采样构建数据集。使用Adam优化器在构建数据集上对预训练检查点进行微调。实验结果如表1所示。

实验结果表明,MinD-B(Base版)在7个任务上的平均成功率达到了63.0% ,显著超越了所有VLA基线(OpenVLA 48.0%, CogAct-L 61.7%)和基于VGM的基线(RoboDreamer 50.3%, VPP 58.0%),实现SOTA性能。特别是在需要复杂时序推理的任务中表现突出,如"扫入簸箕"任务实现96%成功率和"关闭笔记本"任务达到68%成功率。
此外,MinD的控制频率达到了10.2 ~ 11.3Hz,远超其他需要多步视频生成的VGM方法(RoboDreamer ~1 FPS, VPP ~1.1 FPS),展现了模型在实时控制上的巨大优势。
2.3 真机实验
使用Franka Research 3机器人进行实验,配置前视和腕部相机。训练和测试采用三类任务:1)抓放任务(如将立方体放入碗中或将面包放入篮子里);2)拔插充电器;3)擦白板。每个任务通过SpaceMouse遥操作收集100条人工演示数据。

实验结果如表2所示,MinD在腕部相机的配置下取得了68.75%的成功率,MinD在前视相机配置下得到了72.5%的成功率。MinD性能仍旧超越以OpenVLA为代表的VLA模型和以VPP为代表的VGM世界模型。
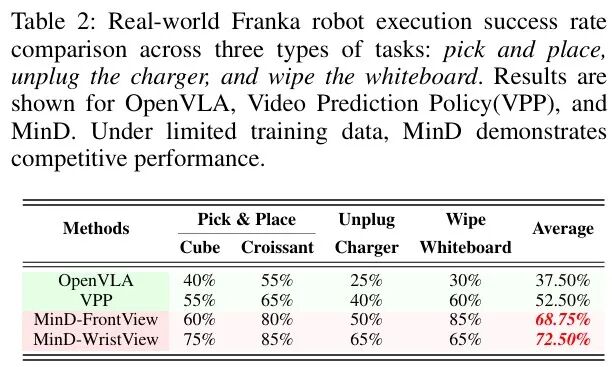
值得注意的是,虽然VPP在长程任务擦白板中也具有很高的成功率60%,但MinD在获得更优性能的同时还能维持更高控制频率。这归功于DiffMatcher设计,不仅保留了快慢双系统的特性,还实现了预测与执行间更紧密的耦合。
3
总结
本论文中,腾讯Robotics X联合香港科技大学、北京大学提出一个面向视觉-语言-动作任务的双系统扩散世界模型MinD,用于实时机器人控制。该模型通过低频视频生成和高频动作扩散两个异步过程,实现快速预测与风险感知规划。为了对齐视觉与动作模态,还提出了轻量级模块DiffMatcher。
在仿真和真机测试中MinD均展现出SOTA性能,真机实验中MinD在前视相机配置下平均成功率达到72.5%,超越了以OpenVLA为代表的VLA模型和以VPP为代表的世界模型。更重要的是,MinD能通过潜在特征分析提前预测任务失败,充分展现了视频生成模型作为机器人领域预测性与可解释性世界模型的巨大潜力。
END
智猩猩矩阵号各专所长,点击名片关注










