

相关阅读
【内容目录】
2.制程节点到工艺集成的转变
3.结语
【湾芯展推荐】本文涉及的相关厂商

Advanced(图源:NVIDIA)
在人工智能(AI)和高性能计算(HPC)需求爆炸性增长的驱动下,突破传统互连瓶颈成为关键。台积电(TSMC)凭借其领先的封装技术,通过整合CoWoS®先进封装平台与创新的COUPE(紧凑型通用光子引擎)光学技术,为共封装光学(CPO)解决方案开辟了新道路,在十倍的功耗优势,二十分之一的信号延迟降低的诱惑下,传统依靠高速铜缆的电信号已经捉襟见肘,高性能计算(HPC)的“光电时代”正式来临。
杀手锏之CoWoS® 和 COUPE
CoWoS®平台是TSMC专为HPC和AI应用打造的2.5D封装技术平台,异构集成Chiplet允许将不同工艺制程和不同功能的芯片以各种堆叠互联形式共同封装在同一款塑封体内,而 COUPE通过SolC®(Silicon on low k Carbon-doped oxide)堆叠技术,将先进逻辑芯片(EIC)集成在光子集成电路(PIC)之上,形成一个完整的光学引擎(Optical Engine),最后通过CoWoS(包括其变体CoWoS-S, CoWoS-L, CoWoS-R)完整技术栈将自研硅光引擎直接封装到XPU内部,以达到多算力核心光网络互联的一体化架构。
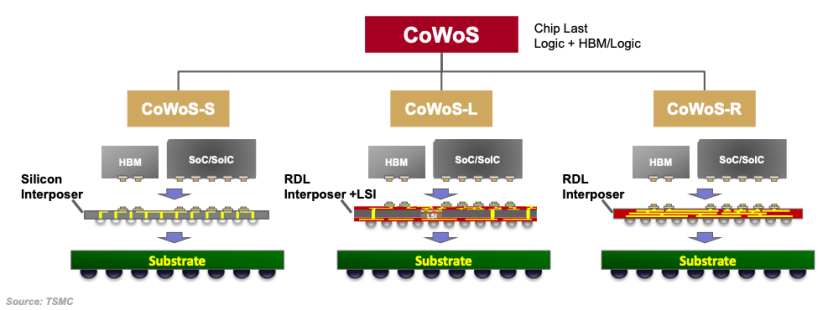
A versatile 2.5D packaging technology for heterogeneous chiplet integration (图源:TSMC)
根据TSMC在今年8月OCP展示的资料来看,从2016年到2025年九年时间内将CoWoS的Interposer从1.5-reticle提升到了9.5-reticle,单芯可容纳超过12颗HBM4E,预计2027年A16制程节点的SoC/SoIC+≥12 HBM4E的CoWos-L将实现量产。针对不同客户还向业界提供了三种CoWoS方案:纯硅中介的CoWoS-S、拥有Si+LSI桥的CoWoS-L、RDL中介层的CoWoS-R。
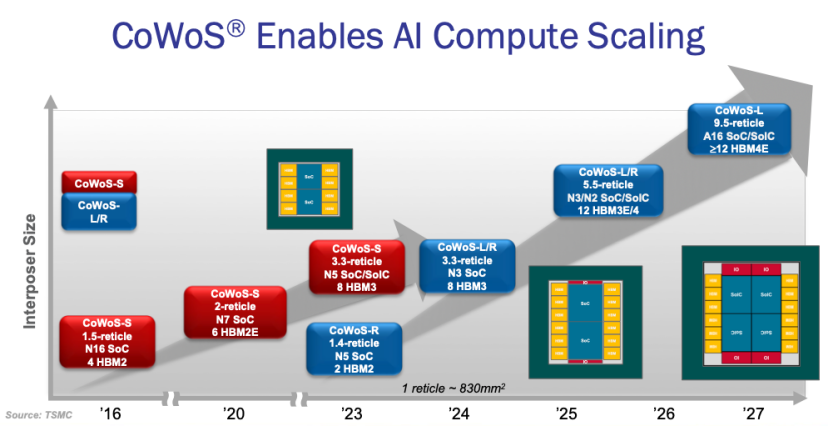
CoWoS® Enables AI Compute Scaling(图源:TSMC)
拥有超小尺寸(垂直堆叠节省面积)、超高能效(光互联损耗降低20倍)COUPE更是混合封装的集大成者,在硅片载体上加工硅透镜,配合光栅耦合器下方的反射透镜,将光路进行了一次折射,并巧妙的加入抗反射涂层(ARCoating)以提升光学性能,节省了额外的透镜。根据其晶圆级测试结果显示:与单独的PIC晶圆相比,COUPE实现了净零插入损耗(Net Zero IL);其一维光栅耦合器(1D GC)实现了插入损耗(IL)≤ -1.2dB,且具有约25nm的1dB带宽,确保了高效、宽频的光信号传输。
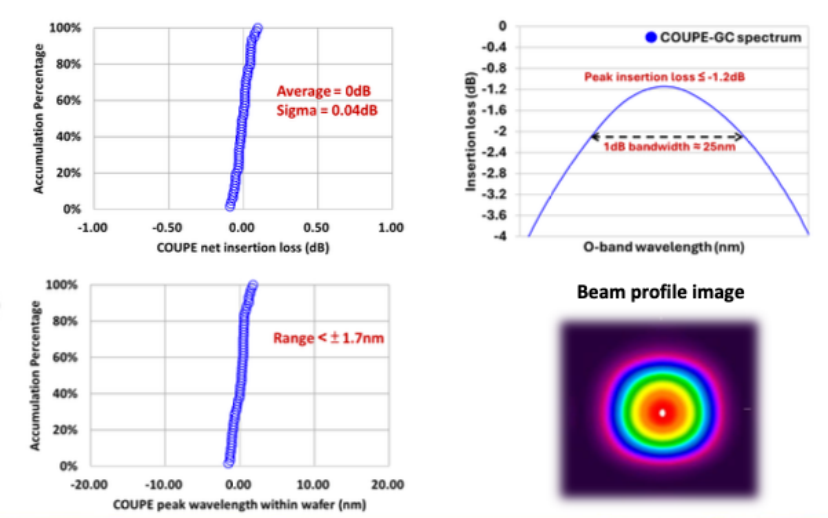
COUPE Optical Performance Characterization (图源:TSMC)
制程节点到工艺集成的转变
算力单元单核心的性能长期依靠制程节点提升其晶体管密度和数量来进行提升,而随着算力密度的爆发式增长,铜缆互联,外置存储等等传统的算力架构已经不能满足,尤其在带宽和功耗上的瓶颈愈发凸显。所以从最早的铜线电信号,到前些年的拔插式光模块,再到如今的基板级CPO(光电共封装)和下一代的硅中介层CPO。不难看出,TSMC作为晶圆制程的领导者已经将制程节点的提升重心转为封装集成工艺的提升。

Co-Packaged Optics Revamps Data Transmission (图源:TSMC)
早期铜缆互联的能效>30pJ/bit,相比于可拔插式光模块>10pJ/bit,其功耗过于高导致高算力中心不堪重负,逐渐退出新一代算力中心的视野;虽然光模块可以在一定程度上信号解耦,并且损坏时替换及其方便,但是仍旧不能满足系统算力单元的跨越式增长,功耗和时延仍旧过高;基板级的光引擎将能效进一步降低到5pJ/bit,时延也大幅度缩减为0.1X,如今高性能算力机组都会采用基板级的CPO方案,TSMC在2027年量产的硅中介层光学引擎则将能耗进一步减小到>2pJ/bit,时延陡降为0.05X。这不是传统提升晶体管数量和密度的“力大砖飞”,更像是用全局视野纵观系统后发现,通过改变封装拉进信号距离,功耗和延迟两大制约算力扩展的难题,变得迎刃而解。把光信号拉进到算力芯片内,功耗和延迟就能把系统带回到正轨。
算力中心在高宽带互联的物理极限,通过基板级CPO到硅中介级CPO的演进,得到了进一步的延续,同时互联不再是一个通道两头相连,其更像是一个系统的核心设计要素,尤其是下一代3.2T、6.4T CPO已经从互联部件转化为系统性工艺集成的大工程。

SiPh Roadmap: Bandwidth Growth (图源:TSMC)
当然TSMC也表明不单单是封装工艺带来的提升,其背后光纤、光源、FAU、Switch、基板材料等全链路的创新也至关重要。为了满足AI计算对带宽“每代翻倍”的增长需求,光学引擎(OE)、CPO以及光纤/光纤阵列单元(FAU)的支持将是构建整个CPO生态的重要环节。
结语
TSMC的CoWoS®平台是HPC/AI加速器异构集成的标杆,而COUPE则为从可插拔模块到CPO的光学引擎应用提供了高性能、低延迟的硅光平台。将COUPE与CoWoS®集成在一个CPO封装中,两大杀手锏齐发力让高性能算力向前飞跃了一大步。同时也给业界一个很好的启示,死磕制程、单一工艺和材料可能在面对复杂的系统工程时收效甚微,协同作用(CoWoS®与COUPE)和系统创新(光-存-算一体封装)或许才是问题的最优解。
*参考资料
1.《Advanced CPO Integrated by CoWoS® and COUPE 》
2.《先进 CPO:由 CoWoS® 与 COUPE 驱动的系统集成》
3.TSMC
文末福利:免费获取最全的行业资料信息汇总!
文末也给看到这的读者们发福利啦,深芯盟编辑近期分析了光学行业产业链,Yolo的最新分析报告也免费分享给读者朋友们,欢迎大家点赞和转发,我们下期再见。

关注本公众号并回复关键词:OIF,就可以领取每期给大家分享的行业资料啦!


芯启未来,智创生态













