想象一下,如果机器人也能像我们一样,通过刷视频就能学习各种操作技能——比如从抖音上的叠衣服技巧学会整理衣物,从B站的收纳教程学会归置物品——那会是什么样子?
听起来很科幻?但在本月公布的CoRL 2025论文收录名单中,一篇来自南方科技大学CLEAR Lab、逐际动力和香港大学的联合研究,正在把这个设想变成现实。

收录地址:https://www.corl.org/program
Conference on Robot Learning (CoRL)可不是一般的学术会议。作为机器人学习领域的顶级学术会议,自2017年创办以来,CoRL始终引领着机器人学习的技术前沿。今年CoRL 2025关注操作与模仿学习、感知、规划与安全、运动控制、人形与硬件等大热核心主题,竞争之激烈可想而知。
在这样的背景下,南方科技大学CLEAR Lab联合逐际动力、香港大学的论文《Generative Visual Foresight Meets Task-Agnostic Pose Estimation in Robotic Table-top Manipulation》能够成功入选,是因为它提出了一种巧妙的机器人训练范式:让机器人通过视频来预测任务执行过程,进而学会自主操作。这也是逐际动力在利用视频数据进行具身智能训练的又一突破,有望加速机器人自主操作能力的发展。

[图:机器人通过观察人类来学习]
▍GVF-TAPE:让机器人先"看懂"再操作的新范式
在具身智能训练的数据金字塔中,视频数据是最大的变量。为什么这么说?因为互联网上有海量的人类操作视频——从美食教程到手工DIY,从工业装配到日常家务,这些视频本质上都是宝贵的"教学资源"。
问题是,如何让机器人真正"看懂"这些视频并转化为自己的技能?
传统方法就像让机器人死记硬背——工程师需要针对特定场景、特定操作任务进行手把手示教,告诉机器人每个动作的精确参数。这种方式下的人力、时间成本高昂,且无法应对环境的变化,导致部署和泛化的效率低下。
论文中所介绍的GVF-TAPE(Generative Visual Foresight with Task-Agnostic Pose Estimation)算法,核心创新在于将生成式视觉预测和与任务解耦的姿态估计相结合,简单来说,就是让机器人通过看视频学习操作,像人类一样先在脑海里"演练"一遍完成任务的整个过程:
1.先从视频学习一遍:机器人“看”同类的操作视频,学习操作动作
2.准确预测完成任务的画面:通过视频生成模型,预测出自己完成任务时的RGB-D视频,既有颜色信息,更重要的是还有深度信息。
3.再根据想象的画面推理动作:从生成的视频中提取末端执行器的姿态信息
4.最后执行具体操作:通过低层控制器将姿态转化为可执行的运动指令

[图.方法框图概览]
▍三项突破,让机器人更快学会操作
突破一:无需深度相机即可生成RGB-D视频
传统方法生成的只是2D RGB视频,没有空间信息,机器人无法在三维空间准确执行操作。而GVF-TAPE的突破在于,仅凭RGB图像就能生成RGB-D视频——既有颜色信息,也有深度信息,不需要再借助额外的深度相机来植入空间信息。
 [图. 生成RGB-D操作视频,第一行代表RGB图,第二行代表对应的深度图。]
[图. 生成RGB-D操作视频,第一行代表RGB图,第二行代表对应的深度图。]
这就像给机器人装上了"立体视觉",让它能更准确地判断物体在三维空间中的位置。在仿真实验中,加入深度信息后,任务成功率平均提升了6.78%。更重要的是,不需要深度相机后,对于数据采集工具要求进一步降低,成本下降的同时效率也大幅提高。
突破二:与具体任务解耦的机器人姿态预测
让人眼前一亮的是GVF-TAPE的训练方式。不同于传统的手把手示教,它采用了"机器人随机探索"训练模式,机器人随机运动,就能获得对场景泛化有价值的数据:
[视频.机器人自主随机探索]
机器人在环境中随意运动,利用内置的本体感知系统记录当前场景下机器人位姿(位置和姿态)。这些看似毫无章法的动作,实际上是在构建一个庞大的"场景-位姿"对应关系数据库,让算法对场景“免疫”,在任何场景都能识别机器人的位姿。
这种方法的巧妙之处在于:
动作与任务完全解耦,同一份数据可以用于训练各种不同任务,提高了数据复用率
数据采集完全自动化,不需要任何人工标注,大幅减少了人力成本,也加速了数据库的积累与迭代速度
可扩展性极强,数据库越大,泛化能力越强,模型将在更多任务中有更稳健的表现
通过这种自主探索方式,机器人建立了丰富的位姿数据库。面对新场景、新任务时,它能够调用相关经验,快速排除场景噪音,生成最优控制轨迹,真正实现了"一次训练,多任务、多场景应用"。
突破三:实时响应的视频生成速度
以往基于扩散模型(Diffusion Model)的视频生成方法,就像传统胶片相机的冲印过程——需要经过显影、定影等多个步骤才能得到清晰照片,往往要花好几秒甚至十几秒才能生成一段动作视频。
而GVF-TAPE采用了"流匹配"(Flow Matching)技术,就像数码相机的即拍即得——虽然两者都是通过降噪来生成清晰图像,但Flow Matching能用更少的步骤达到同样甚至更好的效果,将单个动作的预测时间缩短到0.6秒。
 [图. 生成质量对比]
[图. 生成质量对比]
从图中可以看到,左侧图表显示的是视频生成误差——流匹配(红线)在相同步数下,误差值大大小于扩散模型(蓝线)。右侧图表展示的是生成视频的图像质量,流匹配仅用前三步就达到了大大高于扩散模型的质量。这种速度提升,让机器人能够在不同场景下快速、准确地执行操作,真正实现了实时闭环控制。
▍实验验证:更高的效率和成功率
为了验证这种"先预测再操作"方法的有效性,研究团队在仿真和真实环境中都进行了大量测试。
仿真环境表现
在LIBERO基准测试中,GVF-TAPE与多个最先进的方法进行了对比。结果显示:

[图. 仿真试验结果]
在LIBERO-Spatial和LIBERO-Object测试中,GVF-TAPE分别取得了95.5%和86.7%的成功率
整体平均成功率达到83%,比第二名高出11.56%
最关键的是,其他方法都需要20%的动作标注数据,而GVF-TAPE完全不需要
实机部署验证
在真实环境中,研究团队测试了7个不同难度的任务,包括刚体、柔体和铰接物体操作等。具体包括把碗放进微波炉并关门、抓取纸巾、折叠衣服、把抹布扔进垃圾桶等。
从简单抓取到复杂的开合操作,从刚性到柔性物体,GVF-TAPE在不同场景和操作变化下都展现出了强大的适应性。特别值得一提的是,在引入人类操作视频进行预训练后,成功率从56%飙升至86%。
[视频. 真机操作样例展示]
▍基于生成视频数据的自主操作探索再升级
作为该成果的研究团队成员之一,逐际动力一直在探索"多元数据配方"策略——通过整合不同模态、不同来源的数据,让机器人更高效地学习操作技能。在视频数据驱动的机器人训练这一方向上,他们取得了多项突破。
从分钟级延迟到亚秒级响应,实现了实时视频生成
从依赖深度相机到纯视觉生成,增强了空间感知能力
以本体随机探索替代人类示教,大幅降低了数据采集成本
这种持续的技术迭代,正在让视频数据成为机器人学习的"通用教材",推动着具身智能向更实用、更高效的方向发展。
试想一下,未来的场景:工厂里的机器人,通过学习大量操作视频就能快速上岗;家里的服务机器人,参考网上的教程视频不断学习新技能;医院的手术机器人,通过观摩手术录像持续提升操作水平。
这种让机器人通过视频学习的能力,或许正是具身智能真正走向大规模应用的关键一步。
毕竟,谁不想身边有一个通过视频就学会干活的机器人助手呢?
如需咨询企业合作事宜,欢迎联系机器人大讲堂-客服(19560423866,手机与微信同号)进行对接。
----------------END-------------------

工业机器人企业
埃斯顿自动化 | 埃夫特机器人 | 非夕科技 | 法奥机器人 | 越疆机器人 | 节卡机器人 | 松灵机器人 | 珞石机器人 | 盈连科技 | 集萃智造 | 优傲机器人 | CGXi长广溪智造 | 阿童木机器人 | 极智嘉
服务与特种机器人企业
医疗机器人企业
元化智能 | 天智航 | 思哲睿智能医疗 | 精锋医疗 | 佗道医疗 | 真易达 | 术锐®机器人 | 罗森博特 | 磅客策 | 柏惠维康 | 迪视医疗 | 水木东方
人形机器人企业
优必选科技 | 宇树 | 云深处 | 星动纪元 | 伟景机器人 | 逐际动力 | 乐聚机器人 | 大象机器人 | 中科深谷 | 魔法原子 | 众擎机器人 | 帕西尼感知 | 赛博格机器人 | 数字华夏 | 理工华汇 | 傅利叶智能 | 天链机器人 | 开普勒人形机器人 | 灵宝CASBOT | 清宝机器人 | 浙江人形机器人创新中心 | 动易科技 | 智身科技 | PNDbotics
具身智能企业
跨维智能 | 银河通用 | 千寻智能 | 灵心巧手 | 睿尔曼智能 | 微亿智造 | 推行科技 | 中科硅纪 | 枢途科技 | 灵巧智能 | 星尘智能 | 穹彻智能 | 方舟无限 | 科大讯飞 | 北京人形机器人创新中心| 国地共建人形机器人创新中心 | 擎朗智能 | 戴盟机器人 | 视比特机器人| 星海图 | 月泉仿生 | 零次方机器人
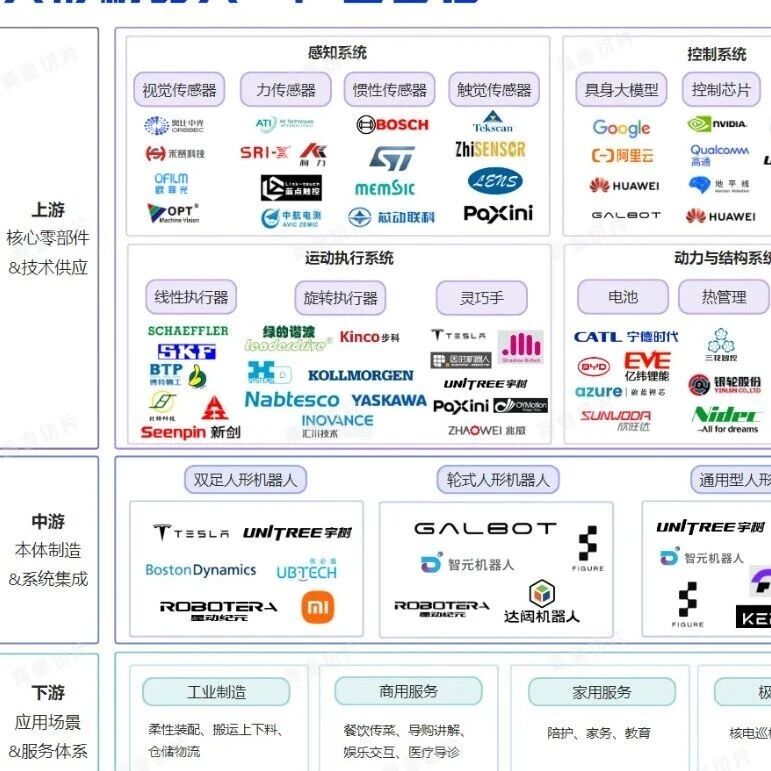
核心零部件企业
绿的谐波 | 因时机器人 | 坤维科技 | 脉塔智能 | 青瞳视觉 | 本末科技 | 鑫精诚传感器 | 蓝点触控 | BrainCo强脑科技 | 宇立仪器 | 极亚精机 | 思岚科技 | 神源生 | 非普导航科技 | 锐驰智光 | NOKOV度量科技 | 因克斯 | 褔德机器人 | 巨蟹智能驱动 | 微悍动力 | 凌云光 元客视界 | 璇玑动力| 意优科技| 瑞源精密 | 灵足时代 | Xynova曦诺未来 | HIT华威科
教育机器人企业
加入社群
欢迎加入【机器人大讲堂】读者讨论群, 共同探讨机器人相关领域话题,共享前沿科技及产业动态,添加微信“robospeak2018”入群!


看累了吗?戳一下“在看”支持我们吧