InternVLA·A1是上海人工智能实验室(上海AI实验室)推出的首个理解、想象、执行一体化具身操作大模型,基于实验室自研的虚实混合操作数据集InternData·A1、上海国地中心实训场数据及互联网多源异构数据联合训练而成。
在真机评测上,InternVLA·A1显著优于π0及GR00T N1.5,并表现出高动态场景下的强适应能力。该模型已适配方舟无限、国地青龙人形机器人、智元Genie、松灵、Franka等多款机器人本体,可支持用户快速适配新场景、新任务。
随着InternVLA·A1的开源,上海AI实验室已开放共享具身智能“思考-行动-自主学习”完整技术闭环:InternVLA·M1作为“大脑”,负责空间推理与任务规划;InternVLA·A1作为“小脑”,实现敏捷精准的动作执行;通用奖励模型VLAC提升机器人在真实世界的强化学习效率。
9月19日(本周五)晚上19:30,上海AI实验室将联合多个行业专业机构启动开源周第2场直播,深度解析相关技术,欢迎预约观看。
代码链接:(文末点击阅读原文可直达)
https://github.com/InternRobotics/InternVLA-A1
核心突破:
• 动态场景交互优势显著: InternVLA·A1的操作成功率显著超越业界先进模型如π0及GR00T N1.5,尤其在涉及传送带动态抓取、多机协作的高动态场景表现出强适应能力。
• 广泛适配主流机器人平台: 目前已成功适配国地中心青龙、方舟无限Lift2、松灵Aloha、智元A2D、Franka等多款机器人型号。
• 开放共享: InternVLA·A1的模型权重及相关工具链将开源于Intern-Robotics社区,全球开发者均可免费体验及使用。
理解、想象、执行一体化,机器人自主操作更智能、更灵活
目前,在操作策略学习方面的具身智能模型大致可分为三类:
简单端到端策略模型(最早期的方法):研究者仅采用一个简单的策略模块进行端到端训练,直接把“观测状态”映射到“机器人控制动作”(比如ACT、DP算法),这种方法简单直接,但因为完全是“反应式”的,没有语义支撑,所以在跨场景、跨任务时泛化能力不足。
多模态大模型驱动的策略模型:如图(b)所示,这类方法引入多模态大模型作为基座,利用预训练的多模态知识来增强场景和指令理解,典型代表是π0和 GR00T-N1/N1.5的。然而,这些模型缺乏时间演化建模,本质上仍然是“即时反应”,因此在动态环境或长程任务中表现不稳定。
基于视觉预测指导的策略模型:近期,基于视觉预测的策略尝试将未来的观察结果作为辅助信号进行预测,如图(c)所示,典型代表有VPP 和 Genie Envisioner,但由于没有集成多模态大模型的语义理解,其预测缺乏语义基础,导致跨场景的泛化能力有限。
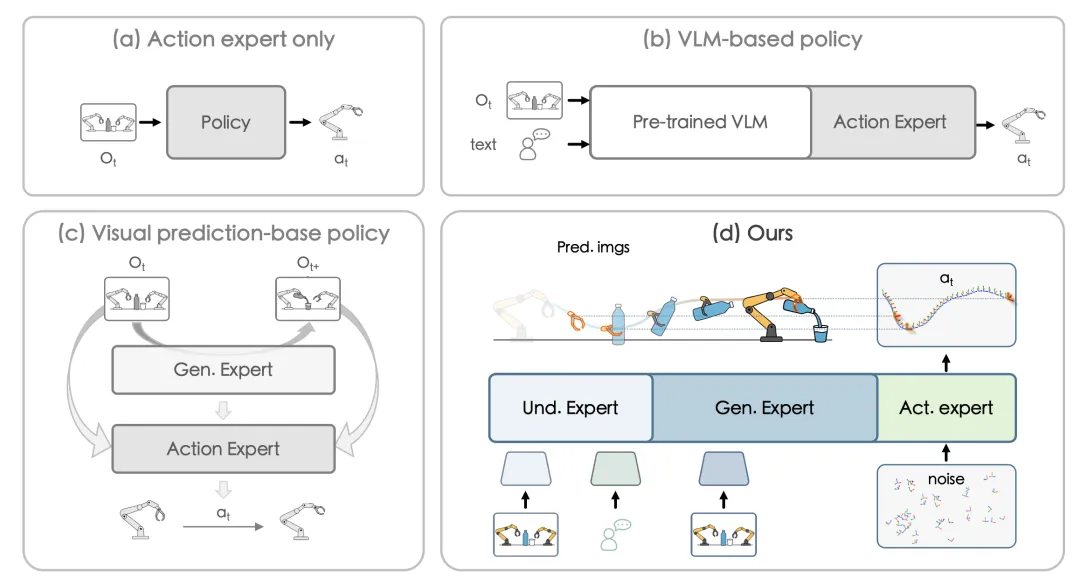
为了破解上述策略模型的局限性,研究团队创新性地提出了“理解-想象-执行”一体化架构(如图 d 所示),以通用多模态大模型InternVL3为基座,深度融合场景理解、指令解析与动态时间建模能力打造InternVLA·A1,让机器人不仅“看得懂、听得清”,更能“想得准、动得稳”。一体化架构由三大模块构成:场景理解模块以图像和文本为输入,解析任务指令并构建对任务场景的理解;任务想象模块基于场景理解的解析结果,预测未来图像并推演任务的可能演变;动作执行模块在任务想象的指导下,借助Flow Matching技术输出机器人控制指令。三大模块相互协同,实现更智能、更灵活的机器人自主操作。

构建“操作数据金字塔”,驱动模型高效进化
为应对具身模型训练数据稀缺与真实性难题,支持InternVLA·A1持续训练,研究团队提出构建一个融合真实机器人操作数据、仿真合成数据与互联网开源数据的“操作数据金字塔”。三层数据协同,既为 InternVLA·A1 提供了海量训练数据,又通过数据多样性与真实性的平衡,助力模型在“感知-想象-执行” 全流程中提升精度与泛化能力,为其实现复杂具身操作任务夯实数据基础。
真实机器人操作数据
这类数据采集遵循“模型验证驱动的高频迭代”原则,并采用复杂度分阶段渐进式上升和模型注意力反馈修正的策略,持续提升数据质量。
(1)数据采集与模型验证紧密结合,高频迭代有助于及时发现并纠正问题;
(2)数采复杂度循序渐进,从位置布局、物体类别到光照、背景等要素逐步增加难度;
(3)结合模型部署的表现,分析机器人部署时的Failure Mode,并针对性进行补充采集。
仿真合成数据
借助虚拟仿真引擎,可低成本、高效率地大规模合成仿真数据:单节点 8 卡 4090 一天即可生成 1.5 万条高质量数据,单条成本仅 2 分钱,约为真机数据的 0.2%。此外,仿真数据能显著扩充真机数据的多样性。前期实验证明,当仿真与真机数据以 5:1 混合训练时,模型性能可从 46.7% 提升至 93.3%。
互联网开源机器人数据
借助互联网上的异构多源机器人数据,进一步提升任务和场景的覆盖面。
InternVLA·A1模型融合了上海AI实验室的虚实混合操作数据集InternData·A1、上海国地中心实训场数据及互联网多源异构数据,数据总量约 27 万条。基于上述多源异构与多场景机器人数据中,InternVLA·A1学习了广泛且通用的操作知识。

InternData·A1数据集也已开源至HuggingFace,欢迎大家下载使用(https://huggingface.co/datasets/InternRobotics/InternData-A1)。该数据集的特点为:
• 异构多机器人本体:覆盖方舟无限Lift-2、青龙人形机器人、智元A2D、松灵分体式Aloha、Franka多款机器人本体。
• 虚实共生:大规模虚实混合数据集,每个真实采集任务均配有仿真环境中的数字孪生任务。
• 动态场景多样性:包含传送带场景、多机协作、人机交互等大量动态场景数据。
高动态场景下,助力机器人稳定、精准执行
InternVLA·A1引入了“任务想象”模块,可对任务的未来演变进行预测,让机器人在复杂、快速变化的场景中(如传送带、旋转台等场景)也能稳定、精准完成任务。另外,得益于仿真数据的多样性,机器人在背景、光线等复杂干扰下依然保持高稳定性与鲁棒性。
以下为部分实例展示。
在传送带场景中,面对形态各异的动态包裹,模型能够实时追踪并精准预测其运动轨迹,在高速运行下依然实现稳定抓取;还能根据面单状态,自适应地完成包裹翻面与快递信息识别。

包裹翻面与快递面单识别
在旋转台场景中,面对高速运转的多样食材,模型能够根据成品菜肴的需求快速识别与定位目标,并精准完成夹取,充分展现出对复杂环境的高度适应性与任务导向的智能。

旋转台物体动态抓取
在多机协作场景中,依托动态视觉捕捉技术和“任务想象模块”中的前瞻预测算法,系统能够快速调整动作,实现高精度的实时交互。

多机协作
在人机动态交互场景中,利用仿真环境中的域随机化技术显著提升样本多样性,使模型即使在复杂背景切换或极端光照干扰下,依然能够保持出色的任务稳定性和环境鲁棒性。

动态人机交互
在物流、商超及办公等多元化真实场景中开展的十余项真机测试中,InternVLA·A1平均任务成功率则达到 82%,显著优于对比模型π0 和gr00t n1.5,性能提升分别超过17%和30%。


欢迎全球开发者扫描下方二维码加入Intern-Robotics讨论社群,交流技术心得、探索前沿方法。

基于『书生』具身全栈引擎Intern-Robotics,上海AI实验室取得一系列技术新进展,并通过【具身智能开源周】集中推出。目前开源的导航大模型InternVLA·N1、通用奖励模型VLAC、操作“大脑”InternVLA·M1、时空数据集OmniWorld,已连续多日占据Hugging Face Trending 前列;后续还将上线人形机器人运动大模型,敬请期待。
-- 完 --
机智流推荐阅读:
1. 万字长文解答为何LLM同问不同答?OpenAI前CTO团队最新研究让大模型结果可复现
2. VLA-Adapter:北邮等团队以0.5B参数实现机器人智能新高度,还无需预训练
3. 理解和生成让任务真的能相互受益吗,还是仅仅共存?北大&百度UAE框架,统一视觉理解与生成,实现多模态模型新突破
4. 聊聊大模型推理系统之Q-Infer技术突破:GPU-CPU协同推理提速3倍背后的三大创新
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










