
新智元报道
新智元报道
【新智元导读】DreamPRM由加州大学圣地亚哥分校的研究团队开发,在数学推理权威测评榜MMMU上获得了第一名。
一图看透全球大模型!新智元十周年钜献,2025 ASI前沿趋势报告37页首发
近年来,大语言模型(LLM)在推理能力上的进展显著,其中过程奖励模型(Process Reward Model, PRM)的提出,使得模型能够在推理链条的中间步骤获得监督,从而更稳健地选择合理的解题路径。
这类方法在文本推理任务中已经取得了良好效果,但在扩展至多模态场景 时,仍然面临两个突出挑战:
分布偏移:多模态输入空间巨大,训练与推理分布往往存在显著差异;
数据质量不均:大规模训练集不可避免地包含噪声或低质量样本,降低了有效监督信号。
因此,如何在多模态推理中有效利用高质量样本,抑制噪声样本的负面影响,成为亟需解决的问题。
针对于此,研究人员设计了新的训练框架,通过双层优化框架,将数据样本的权重(Instance Weights)作为可学习参数,动态改变数据样本的在训练中的影响。

论文地址:https://arxiv.org/abs/2509.05542
代码地址:https://github.com/coder-qicao/DreamPRM-1.5

MMMU Leaderboard

此前,研究人员提出了DreamPRM 框架,通过领域级重加权(domain reweighting)的方式,在不同数据子集之间分配权重,从而提升训练效果。
在此基础上,DreamPRM-1.5将加权粒度进一步细化到单个训练样本:
高质量样本获得更大权重;
低质量或噪声样本权重降低。
这种实例级重加权(instance reweighting)策略,使模型能够充分挖掘每条数据的潜在价值。


DreamPRM1.5的两种模型架构
为了实现「样本级加权」,研究人员设计了两种互补方案:
Instance Table
给每个训练样本一个独立的权重参数;
灵活度高,尤其适合小规模数据集;
缺点是参数量和样本数挂钩,数据一大就很难撑住。
Instance Net
不直接存表,而是用一个小型MLP网络来预测每条数据的权重;
参数量固定,不受数据规模限制;
更适合大规模训练,泛化能力更强。
这就像两种「学习笔记」方式:Instance Table 像是给每道题都写一条批注;Instance Net 则像是总结出一套「看题给分」的规则。

DreamPRM-1.5 的训练流程采用 双层优化框架:
下层优化:利用样本权重对 PRM 进行更新:
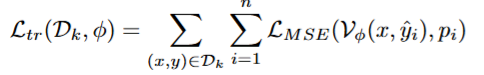
上层优化:在元数据集上评估推理表现,并基于反馈动态更新样本权重:

这种设计确保了权重的学习不是静态设定,而是由推理效果驱动、动态调整的,从而增强了模型在复杂任务中的适应性。

在DreamPRM-1.5中,研究人员采用了生成式奖励模型(Generative Reward Model) 来对推理过程中的每一步进行评分。其核心思想是:
评分方式:模型在每一步输出「+」或「-」,分别表示该步推理是否合理;
打分机制:通过softmax计算 「+」 的概率,将其作为该步骤的置信度;
聚合策略:对整条推理链的步骤分数进行聚合(平均),再与标准答案进行对比,用于指导样本权重的更新。
这一设计的优点在于,它不仅能逐步评估推理链条的合理性,还能为实例重加权 提供更细粒度的信号。

模型基座:采用InternVL3-1B作为PRM的基础模型,并在推理阶段基于GPT-5-mini进行测试。设计了生成式奖励模型的
训练数据:从VisualPRM-400k中采样不同规模的数据(12k、100k)分别训练Instance Table与Instance Net
元数据集:使用MMMU-Pro的标准分割(仅使用test set数据,以避免与validation set出现重合),生成候选推理链作为meta set,用于权重更新。
训练流程:
冷启动:先进行一次有监督微调(20k样本),使模型能够稳定输出「+/-」标记;
双层优化:在此基础上进行100k步迭代,采用AdamW优化器与余弦学习率调度。
计算资源:单卡NVIDIA A100,训练约72小时完成

研究人员在MMMU(Massive Multi-discipline Multimodal Understanding) 基准上对方法进行了系统评测。
该基准涵盖30个学科、183个子领域,题型覆盖图表、地图、化学结构等多模态输入,是目前最具挑战性的推理测试之一。


GPT-5-mini w/ thinking(基线):80.0%
DreamPRM-1.5(Instance Table):84.6% (+4.6)
DreamPRM-1.5(Instance Net):83.6% (+3.6)

No Selection:使用相同数据但不做重加权,仅有 79.1%,验证了实例加权的重要性;
VisualPRM:尽管使用完整的 400k 数据集,但仅达到 80.5%,说明数据规模并不能完全弥补质量差异;
Self-consistency:经典的 test-time scaling 方法为 81.4%,依然低于 DreamPRM-1.5。
整体来看,DreamPRM-1.5 不仅显著超越了基于 GPT-5-mini 的多种强基线,还在精度上超过了GPT-5(84.2%)和Gemini 2.5 Pro Deep-Think(84.0%)等顶级闭源模型。

DreamPRM-1.5将实例级重加权引入多模态推理训练中,通过双层优化动态调整样本权重,使模型能够更好地识别和利用高质量数据。
主要贡献体现在:
提出实例级重加权框架,突破了仅在领域级别加权的限制;
设计了Instance Table 与 Instance Net两种互补实现,兼顾小规模与大规模训练场景;
在MMMU基准上取得新的SOTA结果,超过多个闭源大模型。
这一结果表明,在未来的推理模型研究中,数据质量的精细利用方式也是值得关注的重要方面。
更智能的样本加权与过程评分方法,有望成为推动多模态推理进一步发展的关键方向。












