WorldForge团队 投稿
量子位 | 公众号 QbitAI
近来,由AI生成的视频片段以前所未有的视觉冲击力席卷了整个互联网,视频生成模型创造出了许多令人惊叹的、几乎与现实无异的动态画面。
然而,生成内容的精准可控性仍是制约其应用推广的短板,例如,模型可以生成“海滩边的排球比赛”的动态场景,但创作者很难指挥镜头何时推拉、如何摇移、从哪儿起落。
为补齐“可控性”这块短板,业界通常会在特定数据上微调或重训现有的视频生成模型,但微调一个大模型所需的时间成本和算力成本高昂,甚至还可能会削弱模型内在的世界知识,损害模型的泛化能力与画面质感。
其背后反映出的问题是当前视频模型尚未真正内化三维结构与运动规律,更多依赖外部监督去“硬性施控”,而这也是当前火热的世界模型(World Model)所面临的挑战,比如近期的一些世界模型的探索(如 Google 的 Genie系列)依然走“数据与算力堆料”的大规模训练路径,技术与资源门槛居高不下,也引出一个直面的问题:迈向空间智能,是否只能靠这一条路?
西湖大学AGI实验室提出的WorldForge给出了另一种答案:绕开训练泥潭,转向“推理时引导”——为现有视频生成模型装上精密的路径导航,通过不改权重、即插即用的引导策略,让“随性”的 AI 也能迅速听懂导演的镜头语言。
WorldForge的核心秘籍:在推理环节“写入”引导信号
WorldForge的构想十分巧妙:它不试图去改变视频模型本身的权重,而是在其每一步去噪生成的过程中,巧妙地施加时空信息引导与修正。
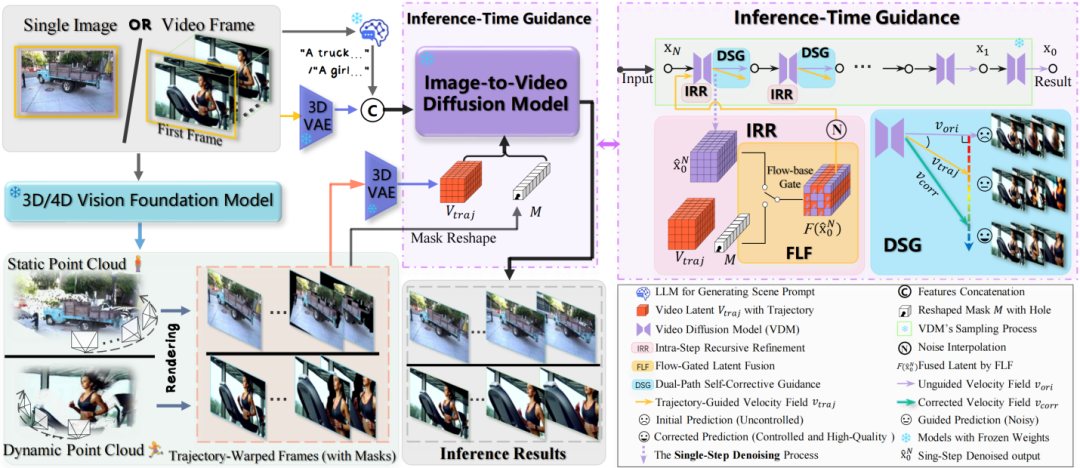
△WorldForge整体流程图
这一框架主要由三大协同工作的创新模块构成:
1. 步内递归修正 (IRR):为“想象”设定边界
AI生成视频的过程,本质上是从一片混沌的噪声中,一步步“猜”出清晰的画面。如果放任其自由猜测,结果自然天马行空。要想让它按照预设的轨迹运动,就必须在它每一次预测后,进行及时引导与纠偏。
为此,IRR模块设计了一个“预测-校正”的微循环。在模型推理的每个时间步中,它先让模型大胆预测,然后再定位与参考内容重合的已知区域,用真实信息覆盖回注。依托这种不间断的逐步校正,轨迹偏离得以及时消除,最终使生成内容遵循预设轨迹。
2. 流门控潜在融合 (FLF):拆分“外观/运动”,把控制打到点上
视频生成模型的潜在表征空间里,掌管物体运动的特征和负责画面质感的特征往往交织在一起。简单粗暴地向所有特征通道都注入运动信号,很可能在改变视角的同时,也破坏了场景的细节纹理、建筑的材质光感等。因此,精准控制视角的核心挑战在于如何在注入运动信息的同时,不破坏原有的生成质量。
FLF模块首先通过光流得分来评判每个特征通道的运动相关度,然后将轨迹信号精准注入到运动相关度高的通道中。实现动静分离与定点制导。
3. 双路径自校正引导 (DSG):用高质量先验修正强引导的副作用
注入到模型中的引导信号通常并不完美,常常含有噪声与深度误差。若完全依赖该信号,容易导致画质下降。
为了解决这个问题,DSG利用了IRR的去噪过程中产生的两条并行去噪路径,在遵循轨迹的同时,利用模型自身的高质量先验纠正引导带来的偏差:第一条是模型初始预测产生的非引导路径,该路径保持模型原生预测,细节与质感更好,但不受轨迹约束;第二条是注入轨迹信号后的引导路径,该路径由于注入了轨迹约束,服从先验轨迹约束,但也容易继承引导信号中的噪声。在每个时间步,DSG 计算两路径输出的差异并生成校正项,将引导路径结果向非引导路径的高质量解收敛。由此同时保证轨迹精确与画面质量稳定。
贯通单图与视频,驾驭动静全场景
得益于这套精巧的控制策略,WorldForge在实际应用中展现出了惊人的能力。
- 单视图生成 3D 静态场景
只需一张照片,WorldForge 即可重建出一致的三维静态场景。并且能够实现以物体为中心拍摄的360°环绕视频。这表示AI可以从二维平面读懂三维世界,为探索更高效、轻量化的世界模型实现路径提供了全新可能。
- 视频电影级重运镜
用户可以自由设计全新的镜头轨迹“重拍”已有的视频,无论是平滑的推拉摇移,还是复杂的弧线跟拍,WorldForge都能完美执行,并智能补全因视角变化而新出现的场景区域,效果领先同类需要大量训练的SOTA模型。
- 视频内容二次创作
除轨迹操控外,WorldForge同样支持视频内容的编辑,例如主体替换、物体擦除/添加、虚拟试穿等二次创作。
以引导激发潜能:一种世界模型构建的新思路
WorldForge为视频生成领域引入了一种新颖的交互与控制思路。
它巧妙地绕开了对大模型本身的修改,转而在生成环节运用外部引导,以此来“唤醒”并结构化模型内部潜在的世界知识,让原本自由的生成过程遵循指定的时空逻辑。
更重要的是,这项工作为“可控世界模型”的构建开辟了一条新的研究路径。它证明了在不增加训练成本、不损耗先验知识的前提下,通过精巧的推理期引导,同样可以实现对复杂动态场景的有效控制。展望未来,沿着这一思路继续深化,我们有望通过更自然的语言或动作交互,让模型成为一个能精准理解并执行我们创意的视觉执行者。
论文链接:https://arxiv.org/abs/2509.15130
项目主页:https://worldforge-agi.github.io/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟










