智猩猩Robot整理
端到端的机器人操作学习是具身智领域的关键研究方向,目前的主流技术方向可以大致分为两个分支:VA(Vision-Action Models)和 VLA(Vision-Language-Action Models)。但现阶段VLA中L能起到的作用非常有限,在单一任务的情况下,对观测到行动的预测,即VA的建模是一个更基础的问题,它有助于更深刻地理解时空表达如何影响动作预测,同时也可以通过各种创新不断探索VA的能力边界。因此,本论文主要聚焦的技术方向为VA,即视觉运动学习(Visuomoter Learning)。
随着视觉基础模型的快速发展,为纯视觉方案提供了可靠的预训练模型。特别是近期VGGT的出现,明确地将基础视觉模型的能力从二维语义感知提升到三维空间感知。然而,纯视觉方案在机器人操作领域尚未能应有的性能,其根本原因在于动作策略模型中的感知表征模块相对薄弱。为此,地瓜机器人联合同济大学提出仅视觉、单视角的扩散策略学习方法VO-DP,利用预训练的视觉基础模型实现语义与几何特征的有效融合。VO-DP采用预训练视觉表征器替代硬件原生点云输入的方案,旨在构建能够超越以3D作为观测输入的方法的纯视觉方案。
论文标题:Semantic-Geometric Adaptive Diffusion Policy for Vision-only Robotic Manipulation
参与人员:
Zehao Ni1, 2, Yonghao He1, Lingfeng Qian1, Fa Fu1, Jilei Mao1, Wei Sui1
参与单位:1.D-Robotics 2.Tongji University
在仿真实验中,VO-DP(3 frames)与DP3在精度上已经持平,并且VO-DP(1 frame)已经略微超过DP3,证明了该纯视觉方案已经能够与3D方案在精度上对齐,甚至有所超越。VO-DP也已经成果部署到真实机械臂上,并能成果执行桌面收纳、混合堆叠等复杂任务。
1
核心贡献
1. 该团队充分挖掘了纯视觉在机器人操作任务中的性能潜力。实验证明,本论文所提出的纯视觉方案不仅突破了传统纯视觉方法(DP)的性能瓶颈,还实现了与基于3D点云方案(DP3)的性能对齐,甚至有所超越,充分表明纯视觉表征在复杂操作任务中具备与三维感知方案相抗衡甚至取而代之的技术潜力。
2. 提出了VO-DP (Vision-Only Diffusion Policy) 方法,该方法将语义特征和几何特征进行融合并压缩,作为下游Policy Head的输入。具体地:1)引入VGGT的中间层特征,即DINOv2的语义特征和Alternating Attention的几何特征;2)设计了一种基于Cross-Attention的的融合模块对语义特征和几何特征进行融合,进行特征增强的同时,也降低了特征的数量;3)提出了空间特征压缩的模块,将增强后的特征进行压缩,适配下游任务的输入。经过融合的特征,可以显著提升Robotic Manipulation的成功率。
3. 研发了面向 Robotic Manipulation 训练框架 DRRM(D-Robotics Robotic Manipulation),该框架基于 Accelerate 实现多机多卡并行训练,支持bf16/fp16等混合精度。已兼容DP/DP3等Visiomotor Policy以及Robotwin仿真器。
2
背景介绍
端到端的机器人操作(Robotic Manipulation)学习是具身智领域的关键研究方向,其本质在于构建 “感知 - 决策 - 控制”一体化模型,从而实现机器人与物理环境的精准交互。机器人端到端操学习作目前的主流技术方向可以大致分为两个分支:VA(Vision-Action Models)和 VLA(Vision-Language-Action Models)。
VA 模型主要基于视觉观测对机器人未来的动作进行预测。VA只关联了两个模态的信息,即视觉观测和机器人动作,VA不依赖语言(Language)指令作为引导。VLA相比较于VA增加了语言作为引导,它关联了三个模态的信息,即语言指令、视觉观测和机器人动作。通常VLA的模型参数量会显著多于VA,大约是VA的10倍左右可达几B甚至几十B。
VA和VLA都是在模仿学习的范畴之下进行训练的。VLA一般是由一个VLM基座结合负责动作预测的Action Expert 构成。其中VLM是在大量的互联网数据上进行预训练,Action Expert则是通常是在在预先训练的基础上,通过少量采集的动作轨迹数据进行finetune。
现阶段VLA中L能起到的作用非常有限,原因如下:1)相同任务的不同demonstration中,L的文本内容通常都是完全一致的,那么意味着文本本身提供的语义可视为一个固定不变的条件,即用于区分不同任务的标志,对于动作准确性的提升是有限的; 2) L的使用要引入Text encoder 或者 VLM,这会显著增大模型的参数量和减慢模型的推理速度。
地瓜机器人团队认为,在单一任务的情况下,对观测到行动的预测,即VA的建模是一个更基础的问题,它有助于更深刻理解时空表达如何影响动作预测,同时也可以通过各种创新不断探索VA的能力边界。因此,本论文主要聚焦的技术方向为VA,即视觉运动学习(Visuomoter Learning)。
在近2年的VA方案中,较为经典的方案是DP(Diffusion Policy)[1]。DP的关键创新之处在于将扩散模型(Diffusion Model)引入动作序列的预测,并利用条件去噪扩散概率模型(Conditional DDPM)对动作分布进行建模。但在观测端的表示学习方面,DP做的探索较少,留下了较大的提升空间。DP采用图像(即纯视觉信息)作为观测输入,利用经典的残差网络(ResNet)作为图像特征提取器,同时也对其它几种二维特征提取网络进行了消融实验,大致结论为:若以从头开始训练(train from scratch)的方式进行训练,则各特征提取器之间的差异并不明显,因此文中选择了最为简单的ResNet18作为最终的特征提取器。
此外,DP3(3D Diffusion Policy)[2] 在DP的基础上,将输入模态由RGB图像转变为3D点云。通过对稀疏3D点云开展特征学习,获取场景紧凑的3D特征表达,并将其作为Diffusion Policy的条件输入。由于直接依托3D点云的特征对空间距离具备更优的表达能力,故而DP3在精度方面通常相较于DP具有显著优势。
视觉基础模型的快速发展,为纯视觉方案提供了可靠的预训练模型。特别是近期VGGT [3] 的出现,明确地将基础视觉模型的能力从二维语义感知提升到三维空间感知。具体而言,VGGT以多视角的图像作为输入,采用DINOv2 [4] 作为图像编码器,随后进行帧注意力(frame-attention)与全局注意力(global attention)操作,充分融合多视角图像的特征,最后使用DPT [5] 恢复原图分辨率,对深度和点云进行预测。这种范式能够直接从RGB图像中获得空间感知能力。
本方案旨在通过深入研究视觉观测的表示学习方案探索纯视觉条件下VA的能力上限。本方案专注于表示学习本身,以DP作为基线(baseline),并不对扩散策略(diffusion policy)部分进行改动,最终旨在构建能够超越以3D作为观测输入的方法的纯视觉方案。
3
方案动机
视觉传感器的综合性能优势。相较于深度相机(RGB-D)与激光雷达(LiDAR),RGB相机具备显著的成本效益与工程便利性。其硬件成本可降低数倍至数十倍,且无需多传感器标定带来的系统复杂性。自动驾驶领域已验证 RGB 传感器可以达到更高的观测频率从而生成更平滑的轨迹预测,减少运动模糊导致的控制延迟, 从而带来更好的智能驾驶体验。
其次纯视觉感知更加符合生物学基础。人类通过双目视觉系统感知世界,仅依赖纯视觉输入即可完成复杂任务操作(如精准抓取、避障导航)。这表明生物智能在无深度传感条件下,通过二维视网膜成像与大脑神经处理的高效协同,已具备空间几何推理与行动预测的潜力。
然而,纯视觉方案在机器人操作领域尚未能应有的性能,其根本原因在于动作策略模型中的感知表征模块相对薄弱。为此,地瓜机器人团队提出采用预训练视觉表征器替代硬件原生点云输入的方案。纯视觉模型拥有比点云模型更为丰富的预训练模型生态,例如多模态预训练模型(如 CLIP)、纯视觉预训练模型(如 DINOv2)等。在具身操作任务中,对空间状态的表征通常决定了动作策略的性能上限,因此选用了 VGGT 面向几何重建的视觉大模型。
4
方法概要
4.1 VGGT介绍
本部分先对VGGT进行简要介绍,阐释其为何是一种优秀的VA特征提取器。首先,VGGT以纯图像作为输入(单张图像或多视角图像均可),满足纯视觉输入的要求;其次,VGGT的图像编码器部分采用了DINOv2,此部分输出的token具有极为出色的语义特征;最后,VGGT主干末端输出的token具备良好的空间感知信息,这是因为VGGT的学习目标是重建输入图像中的三维场景。通过上述分析可知,VGGT高度契合对特征的要求。
4.2 本论文的方法
基于VGGT和下游Diffusion Policy,重新设计了一套面向VA的特征表示学习的结构。
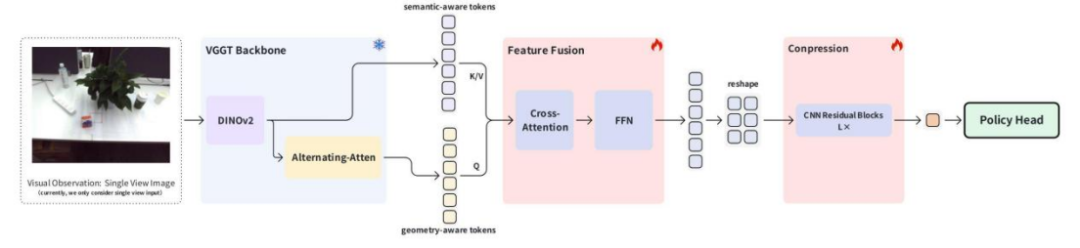
本论文的核心创新如下:
1. 基于 Cross-Attention 的 semantic-aware feature 和 geometry-aware feature 融合
Semantic-aware feature,即语义感知特征,能够为动作策略提供高层次抽象信息(如物体类别、场景上下文),从而实现目标物体与场景状态的识别;而geometry-aware feature,即几何感知特征(如边界、位置、尺度等),通过描述空间结构细节来实现目标物体与本体的相对位置判定。Cross-Attention通过动态计算两类特征的关联权重,从而自适应地选取任务中更受关注的模态信息,助力精准的动作生成。
具体而言,将 VGGT 图像编码器(即 DINOv2)输出的 tokens 用作 semantic-aware feature,将 VGGT 主干网络末端(头部之前)输出的 tokens 用作几何感知特征,以几何感知特征作为查询(Query),语义感知特征作为键/值(Key/Value)进行融合。
2. 1 中融合完成后得到的token,需要进一步做处理。下游Diffusion Policy需要高度压缩后的特征,即所有的观测最终要变成一个特征向量,作为diffusion的条件输入。1 中得到的token有多个,做如下设计:
将token恢复成HW的空间排列
使用带有residual connection的CNN结构对token进行压缩
最终使用 global avg的方式将所有的token压缩成最终的单一特征向量表示
VGGT在大量的重建数据上完成了训练,因此在训练过程中,不对VGGT的权重进行微调,仅对特征融合模块和CNN的特征压缩模块开展训练,以尽可能降低可训练的参数量。在模仿学习的框架下,示教数据量通常相对较少,因此在一定程度上减少可学习的参数量有助于缓解过拟合问题。
5
实验验证
5.1 仿真验证
当前,学术界可供使用的仿真平台较为丰富。考虑到仿真的综合效果、任务的挑战性以及接口的便捷性,最终选用RoboTwin 1.0进行验证。
实验设置如下:
使用RoboTwin为每个任务生成100条示例,作为训练数据
评测时,每个任务运行100次,使用相同的seed保证初始状态一致
一个模型每个任务会评测三轮,即运行三个100次,最终成功率取平均值和方差
bachsize=128,训练时对每个任务的100条示例随机采样训练约 40000 iters (300 epochs)
5.2 特征选择(消融实验)
VGGT中可以用到的特征主要有三种:DINOv2的特征,Alternating-Atten的特征,以及前两者的结合。
此处的消融实验,选用的任务为:Pick Apple Messy,Block Hammer Beat,Dual Bottles Pick (Easy),Put Apple Cabinet,Blocks Stack (Easy)
上述三种特征对应的token数量以及维度完全一致。
下表是这三种特征的实验结果

从整体视角分析,本研究提出的方法显著优于DP方法。这一结果充分表明,在相关任务中,不仅需要可靠的策略头,优质的特征表示同样至关重要。
综合各项指标,使用融合了DINOv2和VGGT-AA特征的方案效果是最优的,超过任何其中单一特征的精度;同时,任意一个特征独立使用,二者均显著优于DP方法。
因此,本研究确认了两个极具潜力的特征来源,即DINOv2和VGGT - AA。选用这两个特征的主要原因在于,DINOv2更侧重于语义特征,而VGGT - AA更侧重于空间几何特征,融合两者后的特征,能够同时具备语义和空间感知的能力。
5.3 总体实验比较(DP,DP3)
在本小节,将在更多的任务上,与DP和DP3进行对比

VO-DP (3 frames/1 frame) 分别表示利用连续三帧的图像和一帧的图像作为Policy Head的输入。DP和DP3默认为三帧(官方设置)
DP3和VO-DP(本论文的方法)在整体的表现上是显著优于DP的
本论文的方案VO-DP(3 frames)与DP3在精度上已经持平,并且VO-DP(1 frame)已经略微超过DP3,这也充分说明了纯视觉方案已经能够与3D方案在精度上对齐,甚至有所超越
可以从个别任务发现,有一些任务DP3会表现明显更好(Bottle Adjust,Container Place,Diverse Bottles Pick),而另外一些任务VO-DP则会明显更好(Pick Apple Messy,Blocks Stack (Easy)),这充分说明,不同类型的任务对于特征的依赖是不同的,因此表征学习的优化一定会待来更优的效果
部分可视化结果——DP,VO-DP(1 frame)
Block Hammer Beat
DP
VO-DP
Put Apple Cabinet
DP
VO-DP
Dual Bottle Pick (Hard)
DP
VO-DP
Container Place
DP
VO-DP
5.4 真机验证
实验配置
机械臂——睿尔曼RM65-B(单臂)
相机——Realsense L515。
每个任务采集了100条样例作为学习数据,仅RGB图像进行训练
任务一
桌面收纳,将两个正方体的积木放到盘子中,将一个长方体的积木放到杯子中
成功执行的视频展示如下:



(视频均做了2x的加速处理,后续的视频也做同样的加速处理;视频中的三幅图从左到右分别是L515的图像,ZED左目图像和ZED右目图像)
任务二
堆叠积木,首先将红色的正方体积木放到盘子中,随后将绿色的长方体积木放在红色正方体积木上,最后将蓝色正方体积木放在绿色长方体积木上
成功执行的视频展示如下:



任务三
混合堆叠,首先将红色的正方体积木放置到盘子中,随后将倒扣的杯子扣在红色正方体积木上,最后将蓝色的正方体积木放置到倒扣的杯子底部
成功执行的视频展示如下:



6
总结与未来工作
针对以纯视觉作为输入的VA探索,制定了一系列长期规划,目前已顺利完成第一阶段。
第一阶段:聚焦于单视角,构建对行动轨迹预测具有显著助益的特征学习方法,涵盖预训练模型的选择、特征学习路径的设计等内容。此阶段主要在仿真平台上对各类方案选型进行快速验证。
后续将展开进一步探索。
第二阶段:拓展至多视角,在第一阶段的基础上,融合多个视角的表征,形成更具鲁棒性的表征。从预期效果来看,这能够适应更为复杂的任务,因为遮挡问题得到缓解,同时对场景的理解更为完善。这一阶段同样会在仿真平台上快速验证各类方案选型,并在真机上对阶段方案进行验证测试。
第三阶段:将静态预测拓展为动态预测,即引入记忆能力,将整个任务的执行视为一个增量过程,而非仅考虑当前状态,从而大幅提高在遮挡情况下的预测精度以及整体任务的成功率。
END
智猩猩矩阵号各专所长,点击名片关注










