点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
写在前面
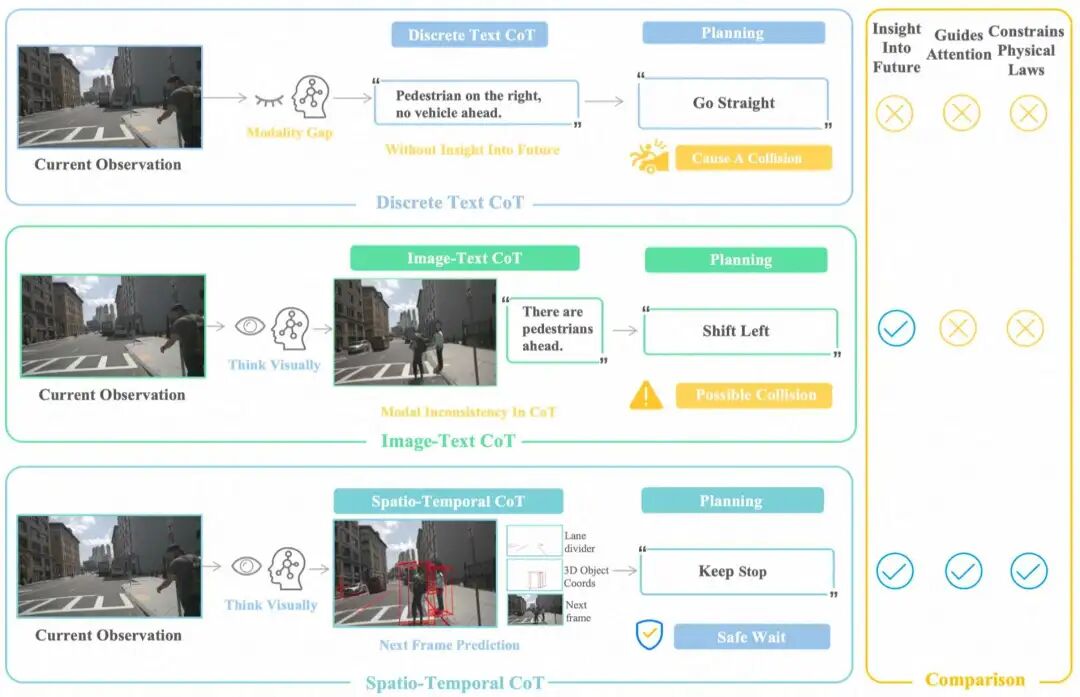
视觉-语言-动作模型(VLA)正快速渗透到自动驾驶研究之中。但现有方法常借助离散文本的Chain-of-Thought(CoT)做中间推理:把连续、高维的视觉信息压缩为语言描述与坐标等符号。这种“视觉→文本→推理”的路径像是强迫老司机用文字解释直觉,必然带来时空关系的歧义与细节损耗,限制了在复杂动态场景中的决策可靠性。
我们提出 FSDrive(FutureSightDrive),一个以时空思维链(Spatio-temporal CoT)为核心的新型端到端规划框架,让模型像人类驾驶员一样,在统一的视觉空间中“先看见未来,再做出决策”,真正实现可视化思考。
项目主页: https://miv-xjtu.github.io/FSDrive.github.io/论文链接: https://arxiv.org/abs/2505.17685代码仓库: https://github.com/MIV-XJTU/FSDrive
关键词:视觉-语言-动作模型(VLA)、世界模型(World Model)、视觉因果推理、时空思维链(Spatio-temporal CoT)、自动驾驶
研究动机与挑战
信息损耗:视觉感知的连续性与高维度在文本符号化过程中被压缩,细粒度细节与时空约束难以完整保留。 模态鸿沟:视觉与文本往返转换引入语义偏差,影响在复杂路况下的推理精度与可解释性。
FSDrive的核心设想是:用“统一的未来图像”作为中间推理载体,把未来的空间结构(车道线、3D障碍物)与时间演化(未来像素帧)在同一张图上共同表达,支持后续更可靠的规划决策。
方法概览:从“文字思考”到“视觉思考”
FSDrive把VLM/VLA同时作为世界模型与逆动力学模型,构成“观察-想象-决策”的闭环:
世界模型(预测未来):生成一幅统一的“未来帧”。其中,红色的车道线与3D检测框呈现未来的空间关系;未来像素帧呈现场景的时间演化。 中间推理(时空CoT):这张“思考图”作为显式的中间步骤,承载可视化的因果推理。 逆动力学(规划轨迹):基于当前观测与生成的未来图像,反推实现该未来状态的最优轨迹。
这种统一视觉范式避免了跨模态转换引发的语义落差,让“看见—思考—决策”在像素空间端到端闭合。
核心创新
统一视觉形式的时空思维链:将未来感知结果(车道线、3D框)直接绘制在未来像素帧上,在单一图像中同时编码时序变化与空间约束。 低成本激活生成能力的统一预训练:在不改动原有MLLM架构的前提下,仅扩展词表以纳入视觉token,保留理解能力的同时高效解锁图像生成。 渐进式(由易到难)生成策略:先生成物理骨架(车道线、3D框)以注入静/动态物理先验,再补充细节像素,显著提升预测的物理可信度。 端到端视觉因果推理:在像素空间直接进行因果关联学习,减少符号抽象带来的信息缺失。
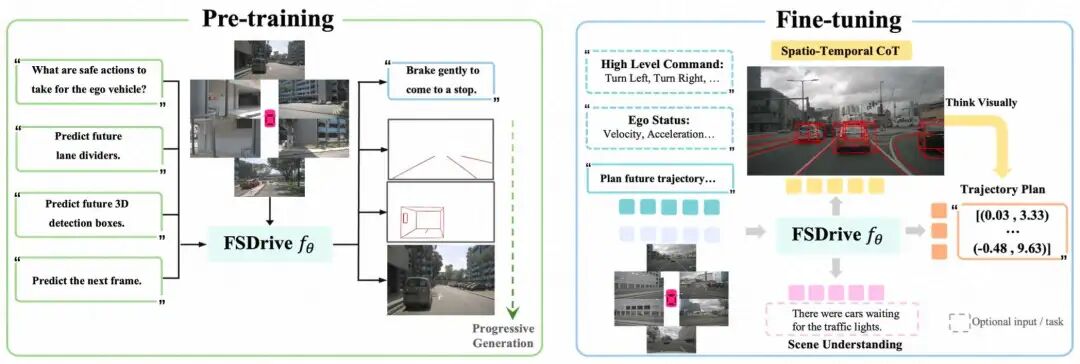
训练范式与实现要点
保持原生MLLM结构:直接在词表中加入VQ-VAE视觉token,使模型具备预测图像token并经解码器还原为像素的能力,最大化利用已有权重与世界知识。 统一预训练(理解+生成): 理解侧:采用VQA等任务保持对驾驶场景的语义理解与问答能力。 生成侧:自回归预测未来帧token,利用海量视频中的天然未来帧学习场景演化规律。 渐进式生成:在少量带注释数据上先学未来车道线与3D检测(物理骨架),再在其约束下补全未来像素细节。 推理阶段:不再分开生成各子结果,而是将“未来像素+红色车道线+3D框”融合为一张统一的未来图像,作为时空CoT驱动轨迹规划。 广泛适配:可基于Qwen2-VL、LLaVA等现成MLLM初始化,避免从零训练带来的高昂成本。
实验速览
我们在nuScenes与DriveLM等基准上,对轨迹规划、未来场景生成与场景理解进行了系统评估。
轨迹规划(nuScenes) 在L2误差与碰撞率等关键指标上,FSDrive在含/不含自车状态两种设置下均具备强竞争力,验证“视觉思考”对规划安全性的显著促进。 相较以离散文本为中间推理的做法,时空CoT有效降低碰撞率,体现出对潜在风险的前瞻识别能力。
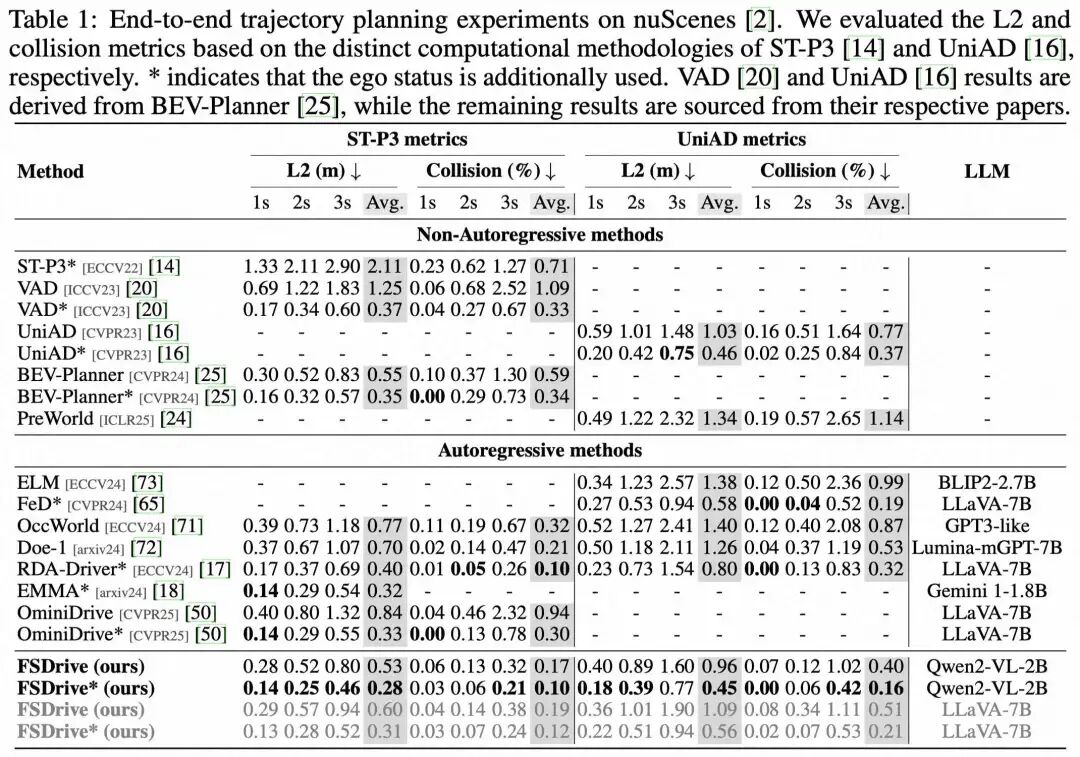
未来场景生成质量 即便采用更高效的自回归生成范式,FSDrive的FID仍优于多种专用扩散基线,表明统一预训练与渐进式生成在质量与效率上的平衡优势。

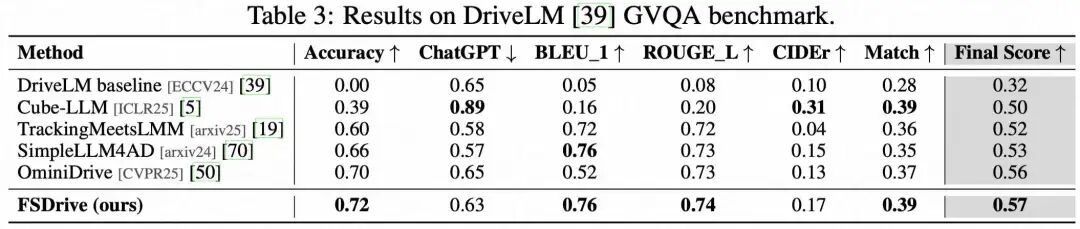
场景理解(DriveLM GVQA) 在多项语言与问答指标上取得优异成绩,说明“生成能力的引入”并未稀释理解能力,反而通过统一预训练实现协同增益。
可视化分析 通过生成包含未来车道线与障碍物位置的“思考图像”,FSDrive能够提前预见危险并规避,从而规划出更安全的行驶轨迹。

结语
FSDrive(入选 NeurIPS 2025 Spotlight)提出了一种“在图像里思考”的自动驾驶新范式:以统一的图像作为中间时空思维链,联结未来像素与未来感知结果,实现端到端的视觉因果推理。我们提出的统一预训练与渐进式生成策略,以极低的改动成本激活了MLLM的视觉生成能力,并在多个任务上带来实证收益。与依赖抽象语言符号的传统路径不同,FSDrive将推理锚定在更贴近物理世界的像素层面,推动自动驾驶朝“可视化推理”的新阶段演进。
3D视觉1V1论文辅导来啦!
3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001